MMToM-QA: Multimodal Theory of Mind Question Answering
2401.08743
0
0

Abstract
Theory of Mind (ToM), the ability to understand people's mental states, is an essential ingredient for developing machines with human-level social intelligence. Recent machine learning models, particularly large language models, seem to show some aspects of ToM understanding. However, existing ToM benchmarks use unimodal datasets - either video or text. Human ToM, on the other hand, is more than video or text understanding. People can flexibly reason about another person's mind based on conceptual representations (e.g., goals, beliefs, plans) extracted from any available data. To address this, we introduce a multimodal Theory of Mind question answering (MMToM-QA) benchmark. MMToM-QA comprehensively evaluates machine ToM both on multimodal data and on different kinds of unimodal data about a person's activity in a household environment. To engineer multimodal ToM capacity, we propose a novel method, BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models). BIP-ALM extracts unified representations from multimodal data and utilizes language models for scalable Bayesian inverse planning. We conducted a systematic comparison of human performance, BIP-ALM, and state-of-the-art models, including GPT-4. The experiments demonstrate that large language models and large multimodal models still lack robust ToM capacity. BIP-ALM, on the other hand, shows promising results, by leveraging the power of both model-based mental inference and language models.
Create account to get full access
Overview
- This paper introduces a new benchmark called "MMToM-QA" (Multimodal Theory of Mind Question Answering) for evaluating a model's ability to reason about the mental states of others.
- The benchmark consists of a large dataset of multimodal (text and images) questions that require understanding the beliefs, desires, and intentions of the characters depicted.
- The authors use this benchmark to assess the theory of mind capabilities of large language models (LLMs), which have recently been shown to exhibit human-like reasoning abilities.
Plain English Explanation
The paper presents a new way to test how well AI systems can understand the thoughts and feelings of other people. It's called the "MMToM-QA" benchmark, which stands for "Multimodal Theory of Mind Question Answering."
The idea is to show AI systems a series of images and text-based questions that require understanding the mental states of the characters involved. For example, a question might be "Why did the character in the image do that?" or "What does the character want to happen next?" To answer these questions correctly, the AI needs to have a "theory of mind" - the ability to imagine what someone else is thinking or feeling.
The researchers use this benchmark to evaluate large language models (LLMs), which are AI systems that can understand and generate human-like text. Recent studies have shown that these LLMs can exhibit human-like reasoning abilities, so the researchers wanted to see how well they could perform on this theory of mind task.
Technical Explanation
The MMToM-QA benchmark consists of a large dataset of multimodal (text and images) questions that require understanding the beliefs, desires, and intentions of the characters depicted. The dataset was created by crowdsourcing questions based on a variety of visual scenes, and it covers a range of theory of mind reasoning skills, from basic perspective-taking to more complex reasoning about social interactions and emotional states.
The authors use this benchmark to assess the theory of mind capabilities of large language models (LLMs). They find that while LLMs can perform reasonably well on some theory of mind tasks, they still struggle with more complex reasoning involving mutual theory of mind and higher-order reasoning. The authors argue that these limitations highlight the need for continued research into how LLMs can exhibit more human-like reasoning and the importance of theory of mind for effective human-AI communication.
Critical Analysis
The MMToM-QA benchmark represents an important step forward in evaluating the theory of mind capabilities of AI systems. By focusing on multimodal reasoning that requires understanding the mental states of others, the benchmark provides a more comprehensive and realistic assessment than previous approaches.
However, the authors acknowledge several limitations of their work. First, the dataset is primarily focused on static images, whereas real-world theory of mind reasoning often involves dynamic, multi-agent interactions. Additionally, the questions in the dataset may not fully capture the nuance and complexity of human social cognition.
Furthermore, the authors' analysis of LLM performance reveals significant room for improvement. While LLMs can handle some basic theory of mind tasks, they struggle with more advanced reasoning, particularly when it comes to understanding mutual theory of mind and higher-order cognition. These limitations suggest that current AI systems still have a long way to go in matching human-level social intelligence.
Conclusion
The MMToM-QA benchmark represents an important step forward in evaluating the theory of mind capabilities of AI systems. By focusing on multimodal reasoning about the mental states of others, the benchmark provides a more comprehensive and realistic assessment than previous approaches. The authors' analysis of large language models reveals significant limitations in their ability to reason about the beliefs, desires, and intentions of others, highlighting the need for continued research into how LLMs can exhibit more human-like reasoning and the importance of theory of mind for effective human-AI communication. Overall, this work underscores the challenges that AI systems still face in matching human-level social intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
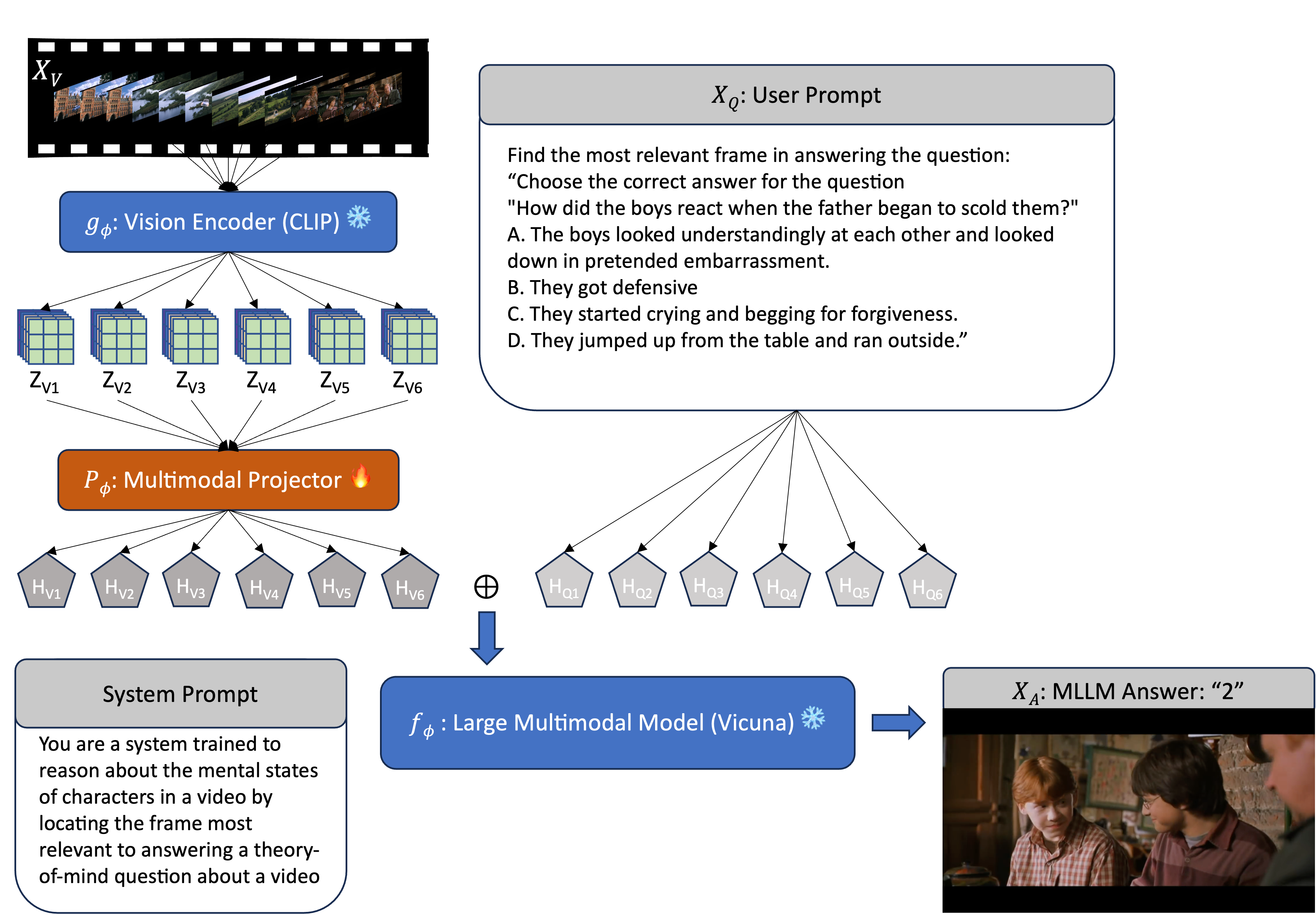
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Zhawnen Chen, Tianchun Wang, Yizhou Wang, Michal Kosinski, Xiang Zhang, Yun Fu, Sheng Li
0
0
Can large multimodal models have a human-like ability for emotional and social reasoning, and if so, how does it work? Recent research has discovered emergent theory-of-mind (ToM) reasoning capabilities in large language models (LLMs). LLMs can reason about people's mental states by solving various text-based ToM tasks that ask questions about the actors' ToM (e.g., human belief, desire, intention). However, human reasoning in the wild is often grounded in dynamic scenes across time. Thus, we consider videos a new medium for examining spatio-temporal ToM reasoning ability. Specifically, we ask explicit probing questions about videos with abundant social and emotional reasoning content. We develop a pipeline for multimodal LLM for ToM reasoning using video and text. We also enable explicit ToM reasoning by retrieving key frames for answering a ToM question, which reveals how multimodal LLMs reason about ToM.
6/21/2024
💬
OpenToM: A Comprehensive Benchmark for Evaluating Theory-of-Mind Reasoning Capabilities of Large Language Models
Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, Yulan He
0
0
Neural Theory-of-Mind (N-ToM), machine's ability to understand and keep track of the mental states of others, is pivotal in developing socially intelligent agents. However, prevalent N-ToM benchmarks have several shortcomings, including the presence of ambiguous and artificial narratives, absence of personality traits and preferences, a lack of questions addressing characters' psychological mental states, and limited diversity in the questions posed. In response to these issues, we construct OpenToM, a new benchmark for assessing N-ToM with (1) longer and clearer narrative stories, (2) characters with explicit personality traits, (3) actions that are triggered by character intentions, and (4) questions designed to challenge LLMs' capabilities of modeling characters' mental states of both the physical and psychological world. Using OpenToM, we reveal that state-of-the-art LLMs thrive at modeling certain aspects of mental states in the physical world but fall short when tracking characters' mental states in the psychological world.
6/4/2024

LLMs achieve adult human performance on higher-order theory of mind tasks
Winnie Street, John Oliver Siy, Geoff Keeling, Adrien Baranes, Benjamin Barnett, Michael McKibben, Tatenda Kanyere, Alison Lentz, Blaise Aguera y Arcas, Robin I. M. Dunbar
0
0
This paper examines the extent to which large language models (LLMs) have developed higher-order theory of mind (ToM); the human ability to reason about multiple mental and emotional states in a recursive manner (e.g. I think that you believe that she knows). This paper builds on prior work by introducing a handwritten test suite -- Multi-Order Theory of Mind Q&A -- and using it to compare the performance of five LLMs to a newly gathered adult human benchmark. We find that GPT-4 and Flan-PaLM reach adult-level and near adult-level performance on ToM tasks overall, and that GPT-4 exceeds adult performance on 6th order inferences. Our results suggest that there is an interplay between model size and finetuning for the realisation of ToM abilities, and that the best-performing LLMs have developed a generalised capacity for ToM. Given the role that higher-order ToM plays in a wide range of cooperative and competitive human behaviours, these findings have significant implications for user-facing LLM applications.
6/3/2024
❗
Mutual Theory of Mind for Human-AI Communication
Qiaosi Wang (Georgia Institute of Technology), Ashok K. Goel (Georgia Institute of Technology)
0
0
New developments are enabling AI systems to perceive, recognize, and respond with social cues based on inferences made from humans' explicit or implicit behavioral and verbal cues. These AI systems, equipped with an equivalent of human's Theory of Mind (ToM) capability, are currently serving as matchmakers on dating platforms, assisting student learning as teaching assistants, and enhancing productivity as work partners. They mark a new era in human-AI interaction (HAI) that diverges from traditional human-computer interaction (HCI), where computers are commonly seen as tools instead of social actors. Designing and understanding the human perceptions and experiences in this emerging HAI era becomes an urgent and critical issue for AI systems to fulfill human needs and mitigate risks across social contexts. In this paper, we posit the Mutual Theory of Mind (MToM) framework, inspired by our capability of ToM in human-human communications, to guide this new generation of HAI research by highlighting the iterative and mutual shaping nature of human-AI communication. We discuss the motivation of the MToM framework and its three key components that iteratively shape the human-AI communication in three stages. We then describe two empirical studies inspired by the MToM framework to demonstrate the power of MToM in guiding the design and understanding of human-AI communication. Finally, we discuss future research opportunities in human-AI interaction through the lens of MToM.
5/28/2024