Moderating New Waves of Online Hate with Chain-of-Thought Reasoning in Large Language Models
2312.15099
0
0
💬
Abstract
Online hate is an escalating problem that negatively impacts the lives of Internet users, and is also subject to rapid changes due to evolving events, resulting in new waves of online hate that pose a critical threat. Detecting and mitigating these new waves present two key challenges: it demands reasoning-based complex decision-making to determine the presence of hateful content, and the limited availability of training samples hinders updating the detection model. To address this critical issue, we present a novel framework called HATEGUARD for effectively moderating new waves of online hate. HATEGUARD employs a reasoning-based approach that leverages the recently introduced chain-of-thought (CoT) prompting technique, harnessing the capabilities of large language models (LLMs). HATEGUARD further achieves prompt-based zero-shot detection by automatically generating and updating detection prompts with new derogatory terms and targets in new wave samples to effectively address new waves of online hate. To demonstrate the effectiveness of our approach, we compile a new dataset consisting of tweets related to three recently witnessed new waves: the 2022 Russian invasion of Ukraine, the 2021 insurrection of the US Capitol, and the COVID-19 pandemic. Our studies reveal crucial longitudinal patterns in these new waves concerning the evolution of events and the pressing need for techniques to rapidly update existing moderation tools to counteract them. Comparative evaluations against state-of-the-art tools illustrate the superiority of our framework, showcasing a substantial 22.22% to 83.33% improvement in detecting the three new waves of online hate. Our work highlights the severe threat posed by the emergence of new waves of online hate and represents a paradigm shift in addressing this threat practically.
Create account to get full access
Overview
- Online hate is a growing problem that negatively impacts internet users
- Detecting and mitigating new waves of online hate is challenging due to the need for complex reasoning and limited training data
- The paper presents a novel framework called HATEGUARD to address these challenges through a reasoning-based approach using large language models and prompt-based zero-shot detection
Plain English Explanation
The paper discusses the problem of online hate, which is becoming increasingly common and harmful to internet users. Detecting and dealing with new waves of online hate, such as those related to current events like the 2022 Russian invasion of Ukraine, the 2021 US Capitol insurrection, or the COVID-19 pandemic, presents two key challenges.
First, it requires complex decision-making to determine if content is hateful, which involves a lot of reasoning. Second, there is a limited availability of training data for these new waves of hate, making it difficult to update existing hate detection models. To address these challenges, the researchers developed a new framework called HATEGUARD that uses large language models and a technique called "chain-of-thought prompting" to detect new waves of online hate.
HATEGUARD can automatically generate and update detection prompts with new hateful terms and targets, allowing it to effectively identify new forms of online hate without needing large amounts of training data. The researchers tested HATEGUARD on a new dataset they compiled, which includes tweets related to the three new wave events mentioned earlier. The results show that HATEGUARD significantly outperforms existing state-of-the-art hate detection tools, highlighting the severe threat posed by new waves of online hate and the need for innovative approaches to address this problem.
Technical Explanation
The paper presents a novel framework called HATEGUARD that leverages the chain-of-thought (CoT) prompting technique and large language models (LLMs) to effectively moderate new waves of online hate.
HATEGUARD employs a reasoning-based approach to determine the presence of hateful content, which is crucial given the complexity of this task. To address the challenge of limited training data for new waves of hate, HATEGUARD achieves prompt-based zero-shot detection. This means it can automatically generate and update detection prompts with new derogatory terms and targets found in samples of the new wave, allowing it to effectively identify emerging forms of online hate without requiring large amounts of labeled data.
The researchers compiled a new dataset consisting of tweets related to three recent new waves of online hate: the 2022 Russian invasion of Ukraine, the 2021 US Capitol insurrection, and the COVID-19 pandemic. Analysis of this dataset revealed crucial longitudinal patterns in the evolution of these new waves, highlighting the pressing need for techniques like HATEGUARD to rapidly update existing moderation tools.
Comparative evaluations against state-of-the-art hate detection tools show that HATEGUARD significantly outperforms them, achieving a 22.22% to 83.33% improvement in detecting the three new waves of online hate. These results demonstrate the superiority of the HATEGUARD framework and its potential to address the severe threat posed by the emergence of new waves of online hate.
Critical Analysis
The paper presents a compelling and well-designed approach to addressing the challenge of detecting and mitigating new waves of online hate. The use of large language models and the chain-of-thought prompting technique is a promising direction, as it allows the system to reason about the complex nature of hateful content without relying on large amounts of labeled training data.
However, the paper does not discuss potential limitations or ethical considerations of this approach. For example, there may be concerns about the reliability and bias of large language models, which could lead to inaccurate or unfair hate detection. Additionally, the automatic generation and updating of detection prompts could raise privacy or transparency concerns, as users may not understand how the system is making its decisions.
Further research is needed to address these potential issues and explore the long-term implications of deploying a system like HATEGUARD at scale. The paper's focus on rapidly updating moderation tools is valuable, but it will be important to ensure that such tools are developed and deployed responsibly, with a strong emphasis on fairness, transparency, and respect for user privacy.
Conclusion
The paper presents a novel framework called HATEGUARD that addresses the critical problem of detecting and mitigating new waves of online hate. HATEGUARD's reasoning-based approach, which leverages large language models and prompt-based zero-shot detection, demonstrates significant improvements over state-of-the-art hate detection tools.
The paper's analysis of new wave datasets highlights the severe and evolving threat posed by online hate, and the urgent need for innovative solutions to this problem. HATEGUARD represents a promising step forward, showcasing the potential of large language models and advanced reasoning techniques to address the challenge of rapidly updating hate moderation systems.
While further research is needed to address potential limitations and ethical concerns, the HATEGUARD framework offers a compelling blueprint for the development of more effective and responsive tools to combat the growing scourge of online hate.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Deep Learning Approaches for Detecting Adversarial Cyberbullying and Hate Speech in Social Networks
Sylvia Worlali Azumah, Nelly Elsayed, Zag ElSayed, Murat Ozer, Amanda La Guardia
0
0
Cyberbullying is a significant concern intricately linked to technology that can find resolution through technological means. Despite its prevalence, technology also provides solutions to mitigate cyberbullying. To address growing concerns regarding the adverse impact of cyberbullying on individuals' online experiences, various online platforms and researchers are actively adopting measures to enhance the safety of digital environments. While researchers persist in crafting detection models to counteract or minimize cyberbullying, malicious actors are deploying adversarial techniques to circumvent these detection methods. This paper focuses on detecting cyberbullying in adversarial attack content within social networking site text data, specifically emphasizing hate speech. Utilizing a deep learning-based approach with a correction algorithm, this paper yielded significant results. An LSTM model with a fixed epoch of 100 demonstrated remarkable performance, achieving high accuracy, precision, recall, F1-score, and AUC-ROC scores of 87.57%, 88.73%, 87.57%, 88.15%, and 91% respectively. Additionally, the LSTM model's performance surpassed that of previous studies.
6/27/2024

Watching the Watchers: A Comparative Fairness Audit of Cloud-based Content Moderation Services
David Hartmann, Amin Oueslati, Dimitri Staufer
0
0
Online platforms face the challenge of moderating an ever-increasing volume of content, including harmful hate speech. In the absence of clear legal definitions and a lack of transparency regarding the role of algorithms in shaping decisions on content moderation, there is a critical need for external accountability. Our study contributes to filling this gap by systematically evaluating four leading cloud-based content moderation services through a third-party audit, highlighting issues such as biases against minorities and vulnerable groups that may arise through over-reliance on these services. Using a black-box audit approach and four benchmark data sets, we measure performance in explicit and implicit hate speech detection as well as counterfactual fairness through perturbation sensitivity analysis and present disparities in performance for certain target identity groups and data sets. Our analysis reveals that all services had difficulties detecting implicit hate speech, which relies on more subtle and codified messages. Moreover, our results point to the need to remove group-specific bias. It seems that biases towards some groups, such as Women, have been mostly rectified, while biases towards other groups, such as LGBTQ+ and PoC remain.
6/21/2024
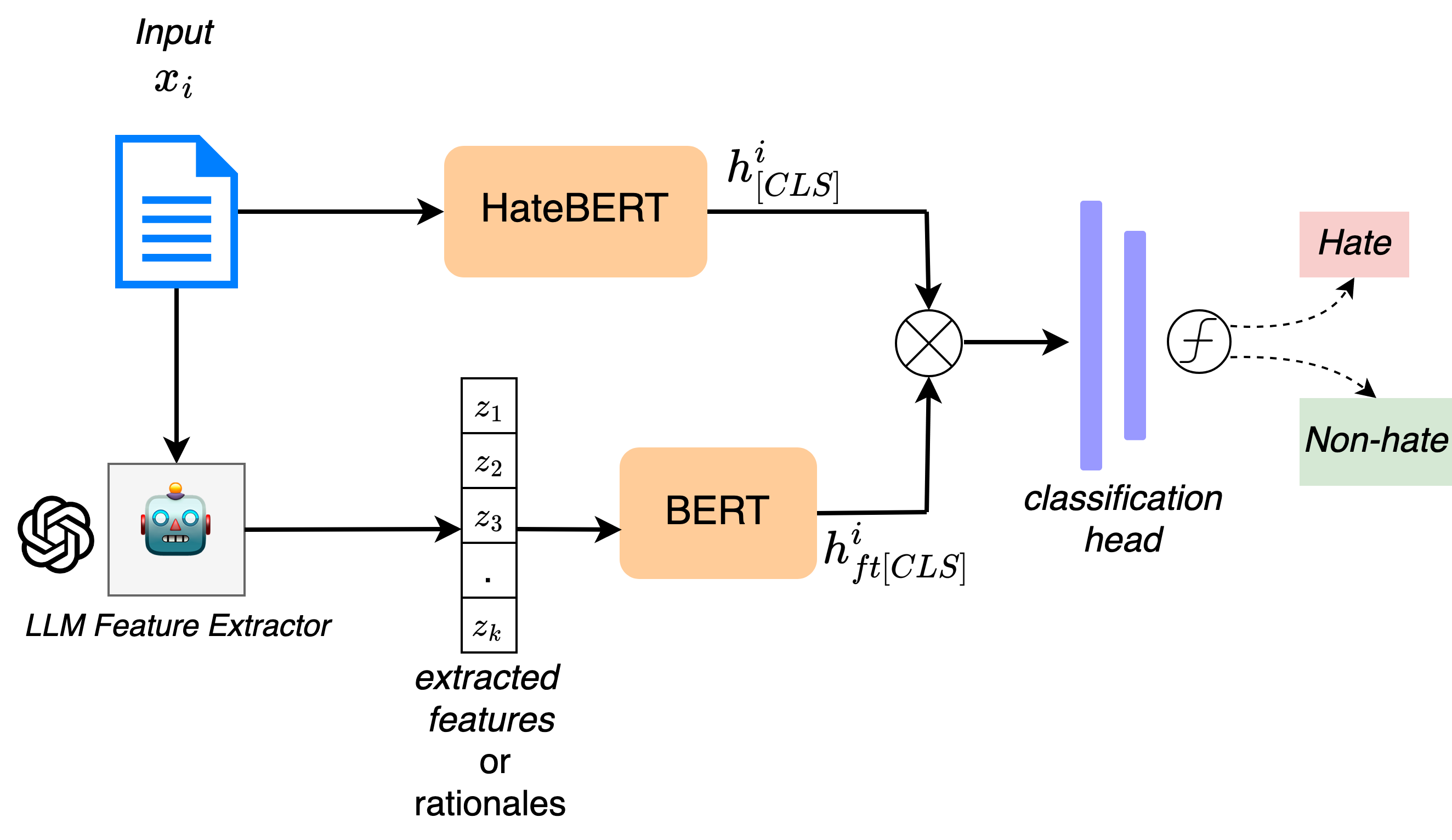
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Ayushi Nirmal, Amrita Bhattacharjee, Paras Sheth, Huan Liu
0
0
Although social media platforms are a prominent arena for users to engage in interpersonal discussions and express opinions, the facade and anonymity offered by social media may allow users to spew hate speech and offensive content. Given the massive scale of such platforms, there arises a need to automatically identify and flag instances of hate speech. Although several hate speech detection methods exist, most of these black-box methods are not interpretable or explainable by design. To address the lack of interpretability, in this paper, we propose to use state-of-the-art Large Language Models (LLMs) to extract features in the form of rationales from the input text, to train a base hate speech classifier, thereby enabling faithful interpretability by design. Our framework effectively combines the textual understanding capabilities of LLMs and the discriminative power of state-of-the-art hate speech classifiers to make these classifiers faithfully interpretable. Our comprehensive evaluation on a variety of English language social media hate speech datasets demonstrate: (1) the goodness of the LLM-extracted rationales, and (2) the surprising retention of detector performance even after training to ensure interpretability. All code and data will be made available at https://github.com/AmritaBh/shield.
5/9/2024
🗣️
Bridging the gap in online hate speech detection: a comparative analysis of BERT and traditional models for homophobic content identification on X/Twitter
Josh McGiff, Nikola S. Nikolov
0
0
Our study addresses a significant gap in online hate speech detection research by focusing on homophobia, an area often neglected in sentiment analysis research. Utilising advanced sentiment analysis models, particularly BERT, and traditional machine learning methods, we developed a nuanced approach to identify homophobic content on X/Twitter. This research is pivotal due to the persistent underrepresentation of homophobia in detection models. Our findings reveal that while BERT outperforms traditional methods, the choice of validation technique can impact model performance. This underscores the importance of contextual understanding in detecting nuanced hate speech. By releasing the largest open-source labelled English dataset for homophobia detection known to us, an analysis of various models' performance and our strongest BERT-based model, we aim to enhance online safety and inclusivity. Future work will extend to broader LGBTQIA+ hate speech detection, addressing the challenges of sourcing diverse datasets. Through this endeavour, we contribute to the larger effort against online hate, advocating for a more inclusive digital landscape. Our study not only offers insights into the effective detection of homophobic content by improving on previous research results, but it also lays groundwork for future advancements in hate speech analysis.
5/16/2024