A multitask learning framework for leveraging subjectivity of annotators to identify misogyny
2406.15869
0
0
Abstract
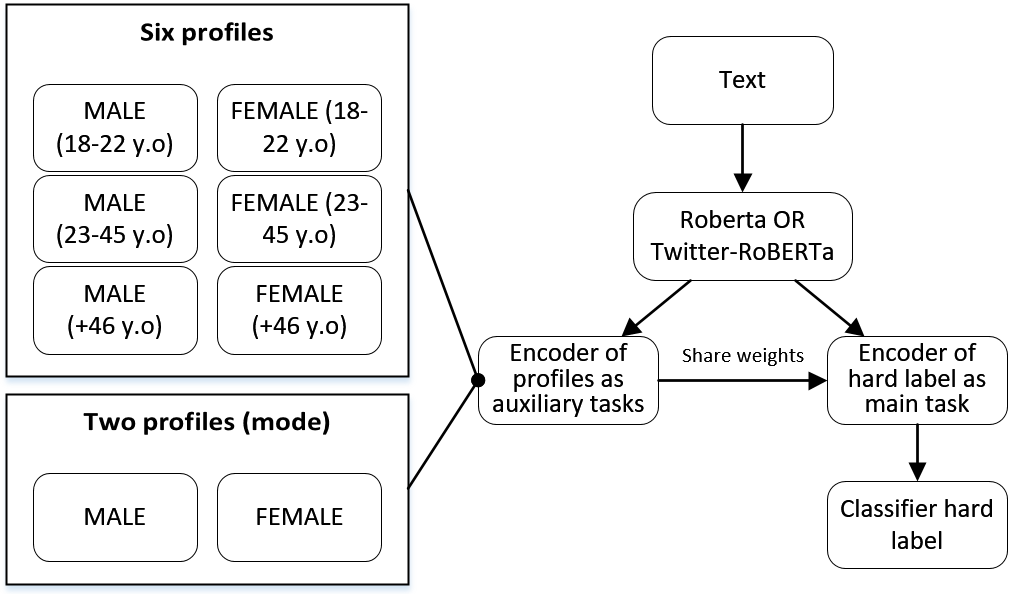
Identifying misogyny using artificial intelligence is a form of combating online toxicity against women. However, the subjective nature of interpreting misogyny poses a significant challenge to model the phenomenon. In this paper, we propose a multitask learning approach that leverages the subjectivity of this task to enhance the performance of the misogyny identification systems. We incorporated diverse perspectives from annotators in our model design, considering gender and age across six profile groups, and conducted extensive experiments and error analysis using two language models to validate our four alternative designs of the multitask learning technique to identify misogynistic content in English tweets. The results demonstrate that incorporating various viewpoints enhances the language models' ability to interpret different forms of misogyny. This research advances content moderation and highlights the importance of embracing diverse perspectives to build effective online moderation systems.
Create account to get full access
Overview
- This paper proposes a multitask learning framework to leverage the subjectivity of annotators in order to identify misogyny in online content.
- The framework aims to capture the diverse perspectives of annotators and use this information to improve the performance of misogyny detection models.
- The authors evaluate their approach on several datasets and demonstrate improvements over existing methods.
Plain English Explanation
Identifying misogyny, or hatred towards women, in online content is an important but challenging task. This is because people's perceptions of what constitutes misogyny can vary quite a bit. What one person might consider misogynistic, another person might not.
<a href="https://aimodels.fyi/papers/arxiv/sexism-detection-data-diet">Previous research</a> has shown that the way data is annotated for training machine learning models can have a big impact on model performance. If the annotators don't agree on what should be considered misogynistic, the models will struggle to learn a consistent definition.
This paper tries to address this issue by developing a new machine learning framework that
The key idea is to frame misogyny detection as a
<a href="https://aimodels.fyi/papers/arxiv/noise-correction-subjective-datasets">The authors argue</a> that this approach can help overcome issues with
Technical Explanation
The paper proposes a
The model architecture consists of a shared
During training, the model is optimized to minimize the combined loss across the main misogyny task and the auxiliary annotator prediction tasks. This encourages the model to learn representations that are not only useful for detecting misogyny, but also capture the
The authors evaluate their approach on several
Critical Analysis
The paper presents a novel and promising approach to addressing the challenges of
However, the authors acknowledge that their approach has some limitations. For example, the framework assumes that the annotators' judgments are
Further research could explore ways to
Conclusion
This paper presents a compelling approach to improving misogyny detection by
The findings of this research have important implications for the development of
Overall, this paper offers a promising direction for
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sexism Detection on a Data Diet
Rabiraj Bandyopadhyay, Dennis Assenmacher, Jose M. Alonso Moral, Claudia Wagner
0
0
There is an increase in the proliferation of online hate commensurate with the rise in the usage of social media. In response, there is also a significant advancement in the creation of automated tools aimed at identifying harmful text content using approaches grounded in Natural Language Processing and Deep Learning. Although it is known that training Deep Learning models require a substantial amount of annotated data, recent line of work suggests that models trained on specific subsets of the data still retain performance comparable to the model that was trained on the full dataset. In this work, we show how we can leverage influence scores to estimate the importance of a data point while training a model and designing a pruning strategy applied to the case of sexism detection. We evaluate the model performance trained on data pruned with different pruning strategies on three out-of-domain datasets and find, that in accordance with other work a large fraction of instances can be removed without significant performance drop. However, we also discover that the strategies for pruning data, previously successful in Natural Language Inference tasks, do not readily apply to the detection of harmful content and instead amplify the already prevalent class imbalance even more, leading in the worst-case to a complete absence of the hateful class.
6/10/2024
🌀
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
0
0
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
6/5/2024
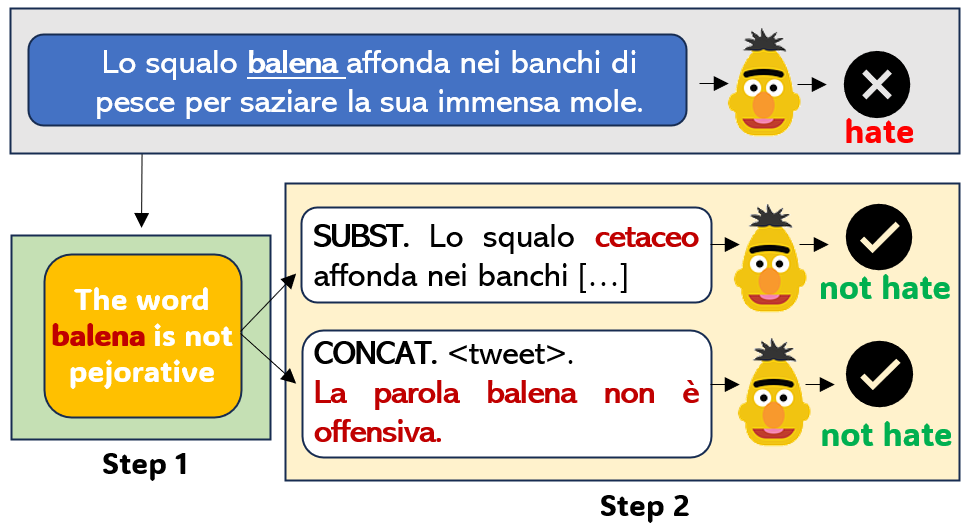
PejorativITy: Disambiguating Pejorative Epithets to Improve Misogyny Detection in Italian Tweets
Arianna Muti, Federico Ruggeri, Cagri Toraman, Lorenzo Musetti, Samuel Algherini, Silvia Ronchi, Gianmarco Saretto, Caterina Zapparoli, Alberto Barr'on-Cede~no
0
0
Misogyny is often expressed through figurative language. Some neutral words can assume a negative connotation when functioning as pejorative epithets. Disambiguating the meaning of such terms might help the detection of misogyny. In order to address such task, we present PejorativITy, a novel corpus of 1,200 manually annotated Italian tweets for pejorative language at the word level and misogyny at the sentence level. We evaluate the impact of injecting information about disambiguated words into a model targeting misogyny detection. In particular, we explore two different approaches for injection: concatenation of pejorative information and substitution of ambiguous words with univocal terms. Our experimental results, both on our corpus and on two popular benchmarks on Italian tweets, show that both approaches lead to a major classification improvement, indicating that word sense disambiguation is a promising preliminary step for misogyny detection. Furthermore, we investigate LLMs' understanding of pejorative epithets by means of contextual word embeddings analysis and prompting.
4/4/2024

Investigating Annotator Bias in Large Language Models for Hate Speech Detection
Amit Das, Zheng Zhang, Fatemeh Jamshidi, Vinija Jain, Aman Chadha, Nilanjana Raychawdhary, Mary Sandage, Lauramarie Pope, Gerry Dozier, Cheryl Seals
0
0
Data annotation, the practice of assigning descriptive labels to raw data, is pivotal in optimizing the performance of machine learning models. However, it is a resource-intensive process susceptible to biases introduced by annotators. The emergence of sophisticated Large Language Models (LLMs), like ChatGPT presents a unique opportunity to modernize and streamline this complex procedure. While existing research extensively evaluates the efficacy of LLMs, as annotators, this paper delves into the biases present in LLMs, specifically GPT 3.5 and GPT 4o when annotating hate speech data. Our research contributes to understanding biases in four key categories: gender, race, religion, and disability. Specifically targeting highly vulnerable groups within these categories, we analyze annotator biases. Furthermore, we conduct a comprehensive examination of potential factors contributing to these biases by scrutinizing the annotated data. We introduce our custom hate speech detection dataset, HateSpeechCorpus, to conduct this research. Additionally, we perform the same experiments on the ETHOS (Mollas et al., 2022) dataset also for comparative analysis. This paper serves as a crucial resource, guiding researchers and practitioners in harnessing the potential of LLMs for dataannotation, thereby fostering advancements in this critical field. The HateSpeechCorpus dataset is available here: https://github.com/AmitDasRup123/HateSpeechCorpus
6/19/2024