Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
2404.05868
0
1

Abstract
Large Language Models (LLMs) often memorize sensitive, private, or copyrighted data during pre-training. LLM unlearning aims to eliminate the influence of undesirable data from the pre-trained model while preserving the model's utilities on other tasks. Several practical methods have recently been proposed for LLM unlearning, mostly based on gradient ascent (GA) on the loss of undesirable data. However, on certain unlearning tasks, these methods either fail to effectively unlearn the target data or suffer from catastrophic collapse -- a drastic degradation of the model's utilities. In this paper, we propose Negative Preference Optimization (NPO), a simple alignment-inspired method that could efficiently and effectively unlearn a target dataset. We theoretically show that the progression toward catastrophic collapse by minimizing the NPO loss is exponentially slower than GA. Through experiments on synthetic data and the benchmark TOFU dataset, we demonstrate that NPO-based methods achieve a better balance between unlearning the undesirable data and maintaining the model's utilities. We also observe that NPO-based methods generate more sensible outputs than GA-based methods, whose outputs are often gibberish. Remarkably, on TOFU, NPO-based methods are the first to achieve reasonable unlearning results in forgetting 50% (or more) of the training data, whereas existing methods already struggle with forgetting 10% of training data.
Create account to get full access
Overview
- This paper introduces a novel technique called "Negative Preference Optimization" (NPO) that aims to address the problem of catastrophic forgetting in large language models.
- Catastrophic forgetting occurs when a model loses the ability to perform well on its original tasks after being fine-tuned on new tasks.
- The authors propose NPO as a way to effectively "unlearn" unwanted behaviors in a language model while preserving its core capabilities.
Plain English Explanation
The paper focuses on a common issue in machine learning known as "catastrophic forgetting." This refers to the problem where a model, like a large language model, can lose its ability to perform well on its original tasks after being trained on new tasks.
The researchers have developed a new technique called "Negative Preference Optimization" (NPO) to address this problem. The core idea behind NPO is to allow the model to effectively "unlearn" unwanted behaviors or preferences, while still preserving its core capabilities that were learned during the initial training.
This is an important advancement, as it could enable language models to be fine-tuned for new applications without completely losing their original skills and knowledge. By avoiding catastrophic forgetting, NPO could make large language models more robust and adaptable as they are used for an expanding range of tasks.
The paper outlines the key contributions of the NPO approach and provides a technical explanation of how it works. The authors also discuss potential limitations and areas for future research.
Technical Explanation
The authors propose a novel technique called "Negative Preference Optimization" (NPO) to address the challenge of catastrophic forgetting in large language models.
The key insight behind NPO is to frame the unlearning process as an optimization problem, where the goal is to minimize the model's preference for certain undesirable behaviors or outputs, rather than simply finetuning the model on new data. This allows the model to selectively "unlearn" specific behaviors while preserving its core capabilities.
The NPO framework involves defining a "negative preference" function that quantifies the model's undesirable behaviors. The training process then seeks to minimize this negative preference function, while also maintaining the model's performance on its original tasks. The authors provide a theoretical analysis to show that this approach can provably avoid catastrophic collapse, where the model completely forgets its original capabilities.
The paper also presents empirical results demonstrating the effectiveness of NPO on language modeling and text generation tasks. The authors show that NPO can successfully remove undesirable biases or behaviors from the model, while retaining its overall performance.
Critical Analysis
The NPO approach presented in this paper is a promising step towards addressing the challenge of catastrophic forgetting in large language models. By framing unlearning as an optimization problem, the authors have developed a principled framework that can selectively remove unwanted behaviors while preserving a model's core capabilities.
However, the paper acknowledges several limitations and areas for further research. For example, the authors note that the current NPO formulation may not be able to completely remove all traces of undesirable behaviors, and that more work is needed to understand the practical implications of the approach.
Additionally, the paper does not extensively explore the broader implications of the NPO technique, such as its potential impact on the safety and robustness of language models deployed in real-world applications. Further research is needed to understand how NPO might interact with other emerging techniques for improving the reliability and transparency of large language models.
Overall, this paper represents an important step forward in addressing the challenge of catastrophic forgetting. The NPO approach offers a novel and principled solution, but continued research will be necessary to fully realize its potential benefits and limitations.
Conclusion
This paper introduces a new technique called "Negative Preference Optimization" (NPO) that aims to address the problem of catastrophic forgetting in large language models. By framing the unlearning process as an optimization problem, NPO allows language models to selectively "unlearn" undesirable behaviors while preserving their core capabilities.
The authors provide a theoretical analysis and empirical results demonstrating the effectiveness of NPO on language modeling and text generation tasks. This work represents an important advancement in the field of machine unlearning, with potential implications for improving the safety, robustness, and adaptability of large language models as they are deployed in an expanding range of applications.
While the NPO approach shows promise, the paper also identifies several limitations and areas for further research. Continued work will be needed to fully understand the practical implications and broader impact of this technique on the development of reliable and transparent language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024
SNAP: Unlearning Selective Knowledge in Large Language Models with Negative Instructions
Minseok Choi, Daniel Rim, Dohyun Lee, Jaegul Choo
0
0
Instruction-following large language models (LLMs), such as ChatGPT, have become increasingly popular with the general audience, many of whom are incorporating them into their daily routines. However, these LLMs inadvertently disclose personal or copyrighted information, which calls for a machine unlearning method to remove selective knowledge. Previous attempts sought to forget the link between the target information and its associated entities, but it rather led to generating undesirable responses about the target, compromising the end-user experience. In this work, we propose SNAP, an innovative framework designed to selectively unlearn information by 1) training an LLM with negative instructions to generate obliterated responses, 2) augmenting hard positives to retain the original LLM performance, and 3) applying the novel Wasserstein regularization to ensure adequate deviation from the initial weights of the LLM. We evaluate our framework on various NLP benchmarks and demonstrate that our approach retains the original LLM capabilities, while successfully unlearning the specified information.
6/19/2024

Mitigating Social Biases in Language Models through Unlearning
Omkar Dige, Diljot Singh, Tsz Fung Yau, Qixuan Zhang, Borna Bolandraftar, Xiaodan Zhu, Faiza Khan Khattak
0
0
Mitigating bias in language models (LMs) has become a critical problem due to the widespread deployment of LMs. Numerous approaches revolve around data pre-processing and fine-tuning of language models, tasks that can be both time-consuming and computationally demanding. Consequently, there is a growing interest in machine unlearning techniques given their capacity to induce the forgetting of undesired behaviors of the existing pre-trained or fine-tuned models with lower computational cost. In this work, we explore two unlearning methods, (1) Partitioned Contrastive Gradient Unlearning (PCGU) applied on decoder models and (2) Negation via Task Vector, to reduce social biases in state-of-the-art and open-source LMs such as LLaMA-2 and OPT. We also implement distributed PCGU for large models. It is empirically shown, through quantitative and qualitative analyses, that negation via Task Vector method outperforms PCGU in debiasing with minimum deterioration in performance and perplexity of the models. On LLaMA-27B, negation via Task Vector reduces the bias score by 11.8%
6/21/2024
Towards Natural Machine Unlearning
Zhengbao He, Tao Li, Xinwen Cheng, Zhehao Huang, Xiaolin Huang
0
0
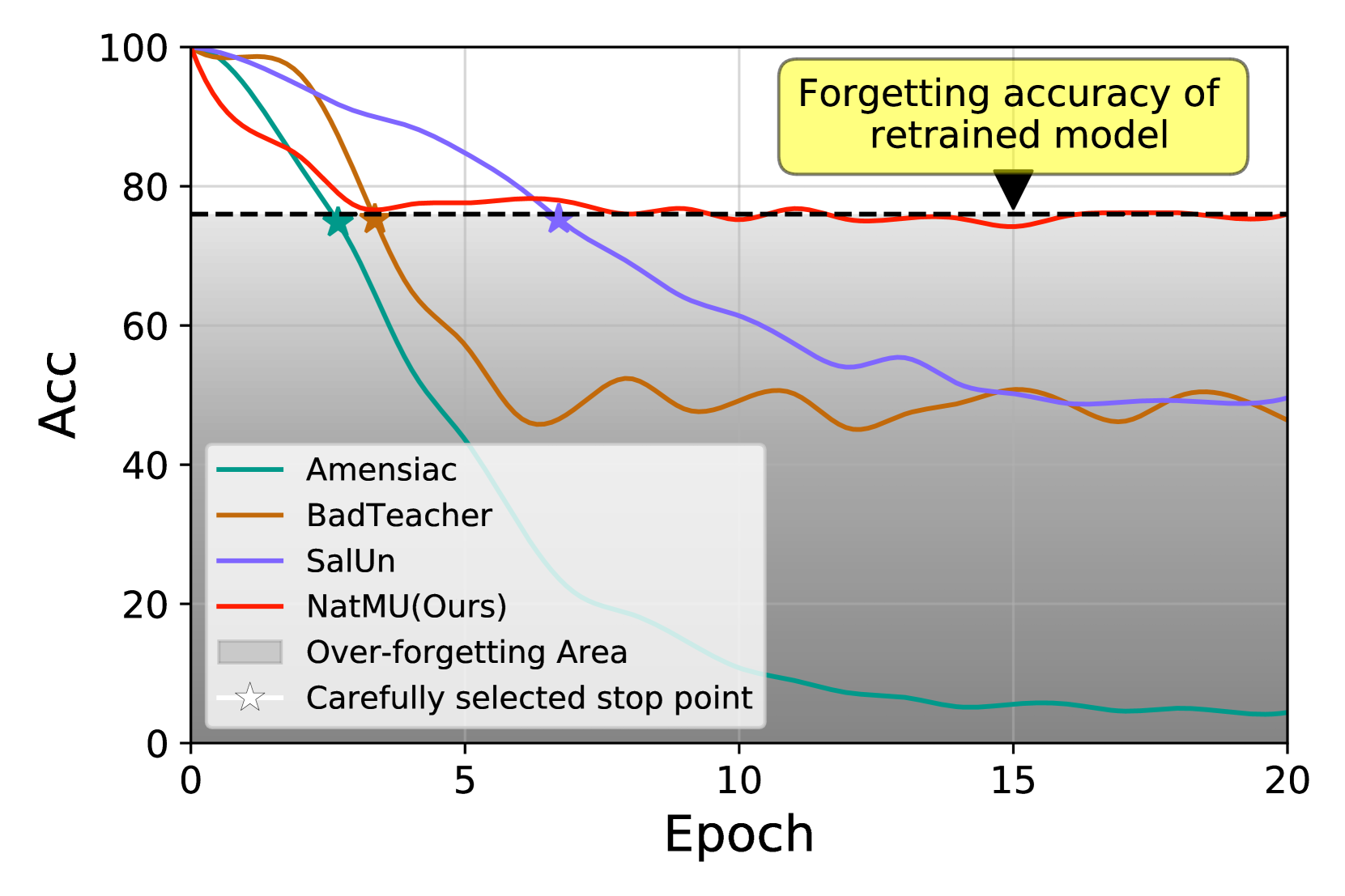
Machine unlearning (MU) aims to eliminate information that has been learned from specific training data, namely forgetting data, from a pre-trained model. Currently, the mainstream of existing MU methods involves modifying the forgetting data with incorrect labels and subsequently fine-tuning the model. While learning such incorrect information can indeed remove knowledge, the process is quite unnatural as the unlearning process undesirably reinforces the incorrect information and leads to over-forgetting. Towards more textit{natural} machine unlearning, we inject correct information from the remaining data to the forgetting samples when changing their labels. Through pairing these adjusted samples with their labels, the model will tend to use the injected correct information and naturally suppress the information meant to be forgotten. Albeit straightforward, such a first step towards natural machine unlearning can significantly outperform current state-of-the-art approaches. In particular, our method substantially reduces the over-forgetting and leads to strong robustness to hyperparameters, making it a promising candidate for practical machine unlearning.
5/27/2024