NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
2404.02185
0
0
Abstract
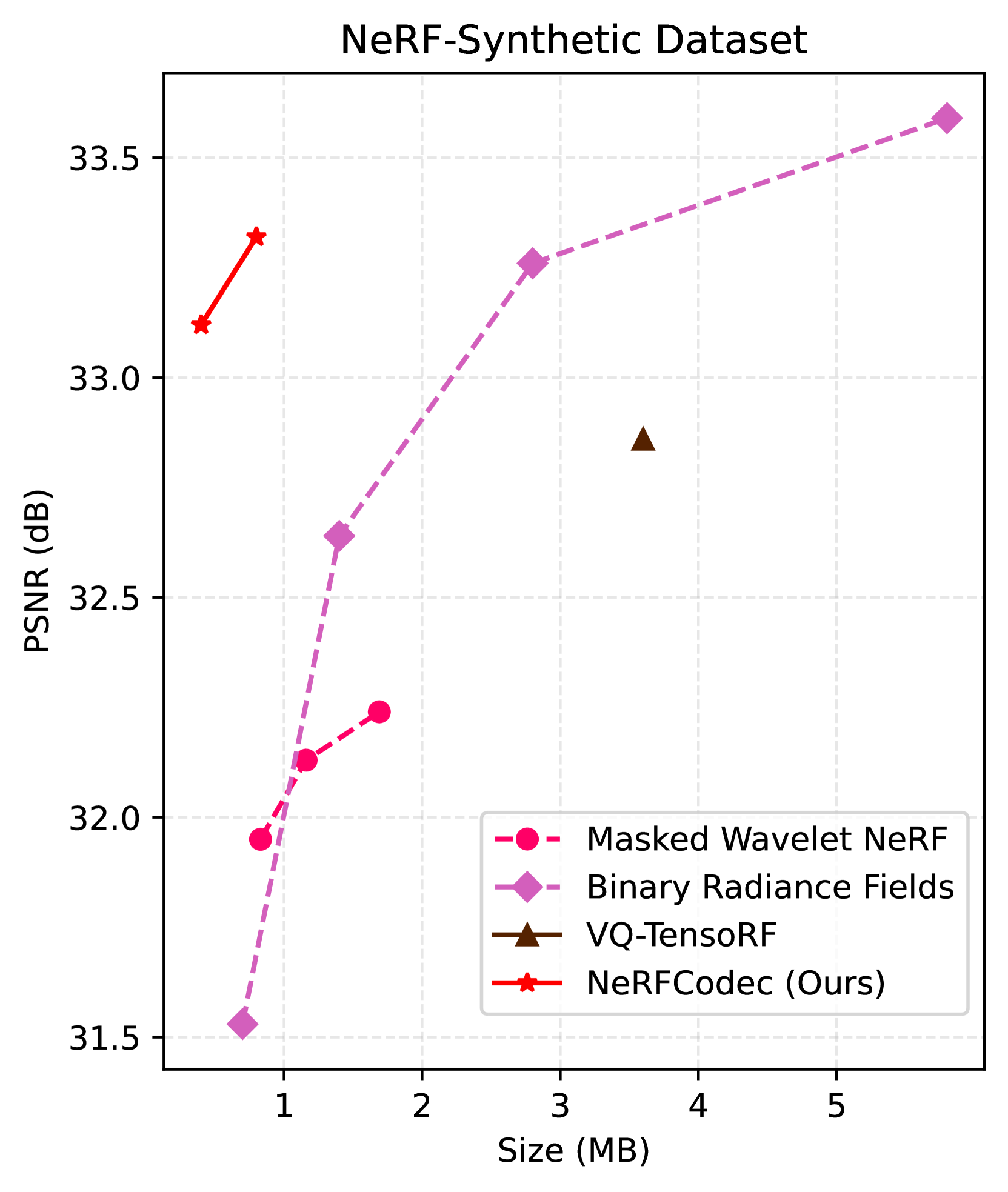
The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis. As a kind of visual media for 3D scene representation, compression with high rate-distortion performance is an eternal target. Motivated by advances in neural compression and neural field representation, we propose NeRFCodec, an end-to-end NeRF compression framework that integrates non-linear transform, quantization, and entropy coding for memory-efficient scene representation. Since training a non-linear transform directly on a large scale of NeRF feature planes is impractical, we discover that pre-trained neural 2D image codec can be utilized for compressing the features when adding content-specific parameters. Specifically, we reuse neural 2D image codec but modify its encoder and decoder heads, while keeping the other parts of the pre-trained decoder frozen. This allows us to train the full pipeline via supervision of rendering loss and entropy loss, yielding the rate-distortion balance by updating the content-specific parameters. At test time, the bitstreams containing latent code, feature decoder head, and other side information are transmitted for communication. Experimental results demonstrate our method outperforms existing NeRF compression methods, enabling high-quality novel view synthesis with a memory budget of 0.5 MB.
Create account to get full access
Overview
- This paper introduces NeRFCodec, a novel approach for memory-efficient scene representation using neural radiance fields (NeRF).
- NeRFCodec combines neural feature compression with NeRF to create a compact representation of 3D scenes that can be efficiently stored and transmitted.
- The key idea is to compress the high-dimensional features used by NeRF models, allowing for significant reductions in memory footprint without sacrificing visual quality.
Plain English Explanation
NeRF is a powerful technique for creating 3D models of real-world scenes by representing them as neural networks. However, these NeRF models can be very large and memory-intensive, making them challenging to use in many real-world applications.
NeRFCodec solves this problem by compressing the internal features of the NeRF model. It does this by training a separate neural network to encode the high-dimensional features into a more compact form, while still preserving the essential information needed to accurately render the 3D scene. This compressed representation can then be stored and transmitted much more efficiently, without losing the visual fidelity of the original NeRF model.
Imagine you have a detailed 3D model of a room, but the file is too large to easily share. NeRFCodec would allow you to compress that model down to a much smaller size, while still retaining the ability to render the room with high quality. This could enable new applications, such as efficiently storing and transmitting 3D content for virtual reality, gaming, or even real estate listings.
Technical Explanation
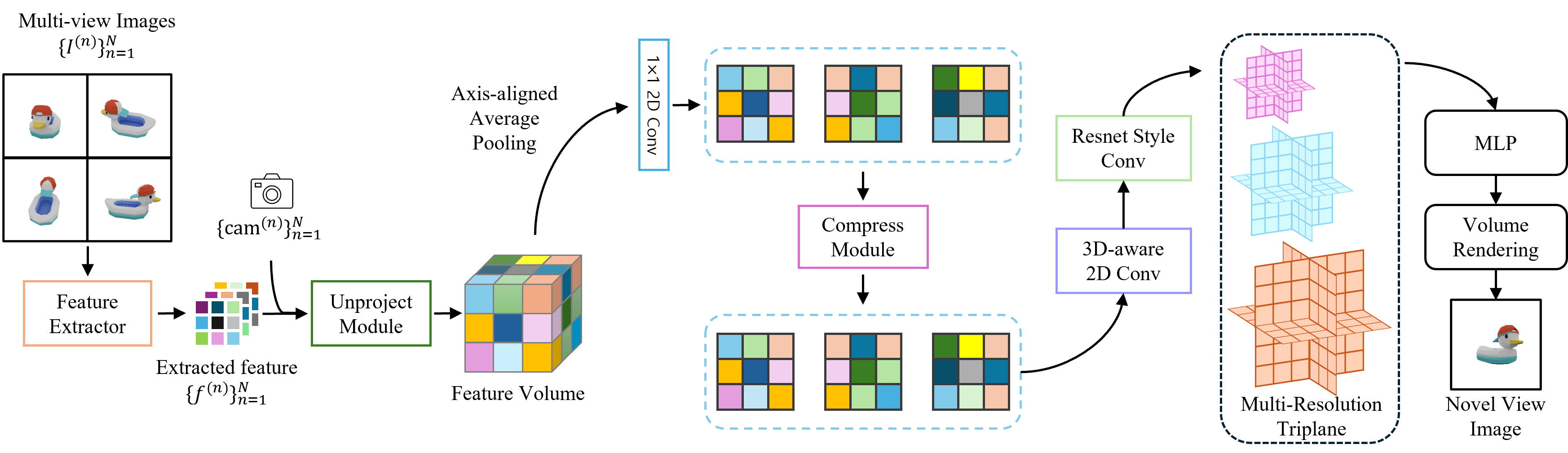
The key components of NeRFCodec are:
- Neural Radiance Field (NeRF): The original NeRF model is used to represent the 3D scene as a neural network that can render views of the scene from arbitrary viewpoints.
- Neural Feature Compression: A separate neural network is trained to encode the high-dimensional features used by the NeRF model into a more compact latent representation. This compression network is trained alongside the NeRF model in an end-to-end fashion.
- Decompression and Rendering: At runtime, the compressed latent representation is decompressed using the decompression network, and then used by the NeRF model to render the final 3D scene.
The authors carefully design the compression and decompression networks to minimize the loss of visual quality, while still achieving significant memory savings. They evaluate NeRFCodec on several benchmark 3D datasets, demonstrating that it can reduce the memory footprint of NeRF models by up to 90% with negligible impact on rendering quality.
Critical Analysis
The paper provides a thorough evaluation of NeRFCodec and demonstrates its effectiveness in compressing NeRF models without sacrificing visual quality. However, there are a few potential limitations and areas for further research:
- The compression and decompression networks add additional computational overhead, which may impact real-time performance in some applications. Further optimizations to these networks could help mitigate this.
- The paper focuses on static scenes, but it would be interesting to see how NeRFCodec could be extended to handle dynamic or time-varying 3D content.
- The compression ratios are impressive, but it's unclear how NeRFCodec would scale to extremely large or complex scenes. Investigating the limits of the compression approach could be a fruitful area for future work.
Overall, NeRFCodec represents a promising step towards more memory-efficient 3D scene representation, with potential applications in virtual reality, gaming, and beyond.
Conclusion
NeRFCodec is a novel technique that combines neural feature compression with neural radiance fields to enable memory-efficient 3D scene representation. By compressing the high-dimensional features used by NeRF models, NeRFCodec can achieve significant reductions in memory footprint without sacrificing visual quality. This could unlock new applications for 3D content, from virtual reality to real estate, by making it easier to store and transmit detailed 3D models. While the paper highlights a few areas for further research, NeRFCodec represents an important advance in the field of 3D scene understanding and representation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Neural NeRF Compression
Tuan Pham, Stephan Mandt
0
0
Neural Radiance Fields (NeRFs) have emerged as powerful tools for capturing detailed 3D scenes through continuous volumetric representations. Recent NeRFs utilize feature grids to improve rendering quality and speed; however, these representations introduce significant storage overhead. This paper presents a novel method for efficiently compressing a grid-based NeRF model, addressing the storage overhead concern. Our approach is based on the non-linear transform coding paradigm, employing neural compression for compressing the model's feature grids. Due to the lack of training data involving many i.i.d scenes, we design an encoder-free, end-to-end optimized approach for individual scenes, using lightweight decoders. To leverage the spatial inhomogeneity of the latent feature grids, we introduce an importance-weighted rate-distortion objective and a sparse entropy model employing a masking mechanism. Our experimental results validate that our proposed method surpasses existing works in terms of grid-based NeRF compression efficacy and reconstruction quality.
6/14/2024
CodecNeRF: Toward Fast Encoding and Decoding, Compact, and High-quality Novel-view Synthesis
Gyeongjin Kang, Younggeun Lee, Seungjun Oh, Eunbyung Park
0
0
Neural Radiance Fields (NeRF) have achieved huge success in effectively capturing and representing 3D objects and scenes. However, several factors have impeded its further proliferation as next-generation 3D media. To establish a ubiquitous presence in everyday media formats, such as images and videos, it is imperative to devise a solution that effectively fulfills three key objectives: fast encoding and decoding time, compact model sizes, and high-quality renderings. Despite significant advancements, a comprehensive algorithm that adequately addresses all objectives has yet to be fully realized. In this work, we present CodecNeRF, a neural codec for NeRF representations, consisting of a novel encoder and decoder architecture that can generate a NeRF representation in a single forward pass. Furthermore, inspired by the recent parameter-efficient finetuning approaches, we develop a novel finetuning method to efficiently adapt the generated NeRF representations to a new test instance, leading to high-quality image renderings and compact code sizes. The proposed CodecNeRF, a newly suggested encoding-decoding-finetuning pipeline for NeRF, achieved unprecedented compression performance of more than 150x and 20x reduction in encoding time while maintaining (or improving) the image quality on widely used 3D object datasets, such as ShapeNet and Objaverse.
5/29/2024
🛠️
JointRF: End-to-End Joint Optimization for Dynamic Neural Radiance Field Representation and Compression
Zihan Zheng, Houqiang Zhong, Qiang Hu, Xiaoyun Zhang, Li Song, Ya Zhang, Yanfeng Wang
0
0
Neural Radiance Field (NeRF) excels in photo-realistically static scenes, inspiring numerous efforts to facilitate volumetric videos. However, rendering dynamic and long-sequence radiance fields remains challenging due to the significant data required to represent volumetric videos. In this paper, we propose a novel end-to-end joint optimization scheme of dynamic NeRF representation and compression, called JointRF, thus achieving significantly improved quality and compression efficiency against the previous methods. Specifically, JointRF employs a compact residual feature grid and a coefficient feature grid to represent the dynamic NeRF. This representation handles large motions without compromising quality while concurrently diminishing temporal redundancy. We also introduce a sequential feature compression subnetwork to further reduce spatial-temporal redundancy. Finally, the representation and compression subnetworks are end-to-end trained combined within the JointRF. Extensive experiments demonstrate that JointRF can achieve superior compression performance across various datasets.
6/11/2024

How Far Can We Compress Instant-NGP-Based NeRF?
Yihang Chen, Qianyi Wu, Mehrtash Harandi, Jianfei Cai
0
0
In recent years, Neural Radiance Field (NeRF) has demonstrated remarkable capabilities in representing 3D scenes. To expedite the rendering process, learnable explicit representations have been introduced for combination with implicit NeRF representation, which however results in a large storage space requirement. In this paper, we introduce the Context-based NeRF Compression (CNC) framework, which leverages highly efficient context models to provide a storage-friendly NeRF representation. Specifically, we excavate both level-wise and dimension-wise context dependencies to enable probability prediction for information entropy reduction. Additionally, we exploit hash collision and occupancy grids as strong prior knowledge for better context modeling. To the best of our knowledge, we are the first to construct and exploit context models for NeRF compression. We achieve a size reduction of 100$times$ and 70$times$ with improved fidelity against the baseline Instant-NGP on Synthesic-NeRF and Tanks and Temples datasets, respectively. Additionally, we attain 86.7% and 82.3% storage size reduction against the SOTA NeRF compression method BiRF. Our code is available here: https://github.com/YihangChen-ee/CNC.
6/7/2024