NeuroCine: Decoding Vivid Video Sequences from Human Brain Activties
2402.01590
0
1
Abstract
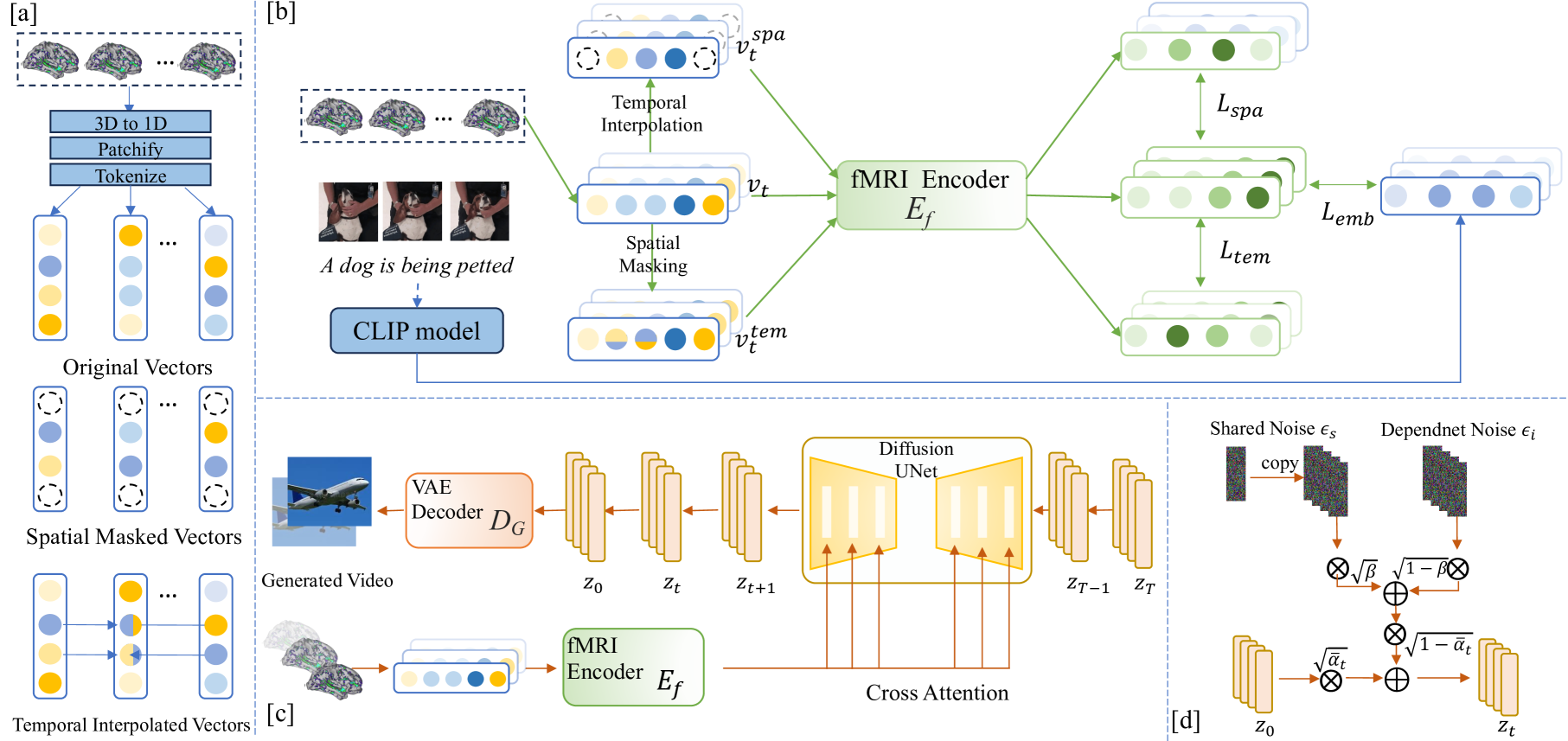
In the pursuit to understand the intricacies of human brain's visual processing, reconstructing dynamic visual experiences from brain activities emerges as a challenging yet fascinating endeavor. While recent advancements have achieved success in reconstructing static images from non-invasive brain recordings, the domain of translating continuous brain activities into video format remains underexplored. In this work, we introduce NeuroCine, a novel dual-phase framework to targeting the inherent challenges of decoding fMRI data, such as noises, spatial redundancy and temporal lags. This framework proposes spatial masking and temporal interpolation-based augmentation for contrastive learning fMRI representations and a diffusion model enhanced by dependent prior noise for video generation. Tested on a publicly available fMRI dataset, our method shows promising results, outperforming the previous state-of-the-art models by a notable margin of ${20.97%}$, ${31.00%}$ and ${12.30%}$ respectively on decoding the brain activities of three subjects in the fMRI dataset, as measured by SSIM. Additionally, our attention analysis suggests that the model aligns with existing brain structures and functions, indicating its biological plausibility and interpretability.
Create account to get full access
Overview
- Researchers developed a deep learning model called "NeuroCine" that can reconstruct vivid video sequences from human brain activity data.
- The model was trained on brain scans of people watching videos, and it was able to accurately generate the original video content.
- This technology could have applications in fields like brain-computer interfaces, neuroscience research, and entertainment.
Plain English Explanation
The researchers behind this study wanted to see if they could use brain activity data to recreate the specific videos that people were watching. To do this, they developed a deep learning model called "NeuroCine" that was trained on brain scans of people as they watched various videos.
The key idea is that when we see something, like a video, our brain activity encodes information about what we're perceiving. By analyzing those brain activity patterns, the NeuroCine model was able to essentially "decode" the video content and reconstruct what the person was seeing, frame by frame.
This is a pretty remarkable feat, as it suggests our brains contain a rich representation of the visual information we experience. If this technology can be further developed, it could lead to all sorts of interesting applications. For example, brain-computer interfaces that allow people to control digital content with their minds, or dream visualization systems that can reconstruct the visual experiences of our dreams.
It's also valuable for advancing our scientific understanding of how the brain processes and encodes visual information, which could have implications for neuroscience research and neural language models that try to bridge the gap between vision and language.
Technical Explanation
The researchers trained the NeuroCine model on functional magnetic resonance imaging (fMRI) data collected from human participants as they watched a set of naturalistic video clips. The model used a convolutional neural network architecture to learn a mapping between the participants' brain activity patterns and the corresponding video frames.
During the training process, the model learned to generate video frames that closely matched the original visual stimuli, based on the input brain activity data. The researchers then tested the model's performance by having it reconstruct video sequences from new brain activity data that it had not seen before.
The results showed that NeuroCine was able to accurately decode and reconstruct the original video content, capturing key visual details and the dynamic flow of the scenes. This suggests the model was able to effectively extract and leverage the rich information about visual experience that is encoded in human brain activity.
Critical Analysis
One of the main limitations of this research is the relatively small and constrained dataset used for training and evaluation. The model was only tested on a limited set of pre-defined video clips, rather than more open-ended or naturalistic visual experiences.
Additionally, the fMRI brain activity data used to train the model has relatively low spatial and temporal resolution compared to other neural recording techniques, such as electroencephalography (EEG). This could limit the model's ability to capture fine-grained details of visual processing in the brain.
Further research is needed to scale up the NeuroCine approach to handle more diverse and complex visual inputs, as well as to explore the model's performance with higher-resolution neural data. Investigating the model's ability to generalize to novel visual experiences, and understanding the specific brain mechanisms it is leveraging, will also be important next steps.
Conclusion
The NeuroCine study represents an exciting advance in the field of brain-computer interfaces and neural decoding of visual experiences. By demonstrating the ability to reconstruct vivid video sequences from human brain activity, the researchers have taken a significant step towards bridging the gap between our internal mental experiences and external digital representations.
This technology could have far-reaching implications, from enabling new forms of human-computer interaction to enhancing our scientific understanding of human cognition and perception. As the field of neural decoding continues to evolve, we can expect to see increasingly sophisticated and powerful tools for unlocking the mysteries of the human mind.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Animate Your Thoughts: Decoupled Reconstruction of Dynamic Natural Vision from Slow Brain Activity
Yizhuo Lu, Changde Du, Chong Wang, Xuanliu Zhu, Liuyun Jiang, Huiguang He
0
0
Reconstructing human dynamic vision from brain activity is a challenging task with great scientific significance. The difficulty stems from two primary issues: (1) vision-processing mechanisms in the brain are highly intricate and not fully revealed, making it challenging to directly learn a mapping between fMRI and video; (2) the temporal resolution of fMRI is significantly lower than that of natural videos. To overcome these issues, this paper propose a two-stage model named Mind-Animator, which achieves state-of-the-art performance on three public datasets. Specifically, during the fMRI-to-feature stage, we decouple semantic, structural, and motion features from fMRI through fMRI-vision-language tri-modal contrastive learning and sparse causal attention. In the feature-to-video stage, these features are merged to videos by an inflated Stable Diffusion. We substantiate that the reconstructed video dynamics are indeed derived from fMRI, rather than hallucinations of the generative model, through permutation tests. Additionally, the visualization of voxel-wise and ROI-wise importance maps confirms the neurobiological interpretability of our model.
5/7/2024
🖼️
Neuro-Vision to Language: Image Reconstruction and Interaction via Non-invasive Brain Recordings
Guobin Shen, Dongcheng Zhao, Xiang He, Linghao Feng, Yiting Dong, Jihang Wang, Qian Zhang, Yi Zeng
0
0
Decoding non-invasive brain recordings is pivotal for advancing our understanding of human cognition but faces challenges due to individual differences and complex neural signal representations. Traditional methods often require customized models and extensive trials, lacking interpretability in visual reconstruction tasks. Our framework integrates 3D brain structures with visual semantics using a Vision Transformer 3D. This unified feature extractor efficiently aligns fMRI features with multiple levels of visual embeddings, eliminating the need for subject-specific models and allowing extraction from single-trial data. The extractor consolidates multi-level visual features into one network, simplifying integration with Large Language Models (LLMs). Additionally, we have enhanced the fMRI dataset with diverse fMRI-image-related textual data to support multimodal large model development. Integrating with LLMs enhances decoding capabilities, enabling tasks such as brain captioning, complex reasoning, concept localization, and visual reconstruction. Our approach demonstrates superior performance across these tasks, precisely identifying language-based concepts within brain signals, enhancing interpretability, and providing deeper insights into neural processes. These advances significantly broaden the applicability of non-invasive brain decoding in neuroscience and human-computer interaction, setting the stage for advanced brain-computer interfaces and cognitive models.
5/24/2024

MindSemantix: Deciphering Brain Visual Experiences with a Brain-Language Model
Ziqi Ren, Jie Li, Xuetong Xue, Xin Li, Fan Yang, Zhicheng Jiao, Xinbo Gao
0
0
Deciphering the human visual experience through brain activities captured by fMRI represents a compelling and cutting-edge challenge in the field of neuroscience research. Compared to merely predicting the viewed image itself, decoding brain activity into meaningful captions provides a higher-level interpretation and summarization of visual information, which naturally enhances the application flexibility in real-world situations. In this work, we introduce MindSemantix, a novel multi-modal framework that enables LLMs to comprehend visually-evoked semantic content in brain activity. Our MindSemantix explores a more ideal brain captioning paradigm by weaving LLMs into brain activity analysis, crafting a seamless, end-to-end Brain-Language Model. To effectively capture semantic information from brain responses, we propose Brain-Text Transformer, utilizing a Brain Q-Former as its core architecture. It integrates a pre-trained brain encoder with a frozen LLM to achieve multi-modal alignment of brain-vision-language and establish a robust brain-language correspondence. To enhance the generalizability of neural representations, we pre-train our brain encoder on a large-scale, cross-subject fMRI dataset using self-supervised learning techniques. MindSemantix provides more feasibility to downstream brain decoding tasks such as stimulus reconstruction. Conditioned by MindSemantix captioning, our framework facilitates this process by integrating with advanced generative models like Stable Diffusion and excels in understanding brain visual perception. MindSemantix generates high-quality captions that are deeply rooted in the visual and semantic information derived from brain activity. This approach has demonstrated substantial quantitative improvements over prior art. Our code will be released.
5/30/2024

BrainChat: Decoding Semantic Information from fMRI using Vision-language Pretrained Models
Wanaiu Huang
0
0
Semantic information is vital for human interaction, and decoding it from brain activity enables non-invasive clinical augmentative and alternative communication. While there has been significant progress in reconstructing visual images, few studies have focused on the language aspect. To address this gap, leveraging the powerful capabilities of the decoder-based vision-language pretrained model CoCa, this paper proposes BrainChat, a simple yet effective generative framework aimed at rapidly accomplishing semantic information decoding tasks from brain activity, including fMRI question answering and fMRI captioning. BrainChat employs the self-supervised approach of Masked Brain Modeling to encode sparse fMRI data, obtaining a more compact embedding representation in the latent space. Subsequently, BrainChat bridges the gap between modalities by applying contrastive loss, resulting in aligned representations of fMRI, image, and text embeddings. Furthermore, the fMRI embeddings are mapped to the generative Brain Decoder via cross-attention layers, where they guide the generation of textual content about fMRI in a regressive manner by minimizing caption loss. Empirically, BrainChat exceeds the performance of existing state-of-the-art methods in the fMRI captioning task and, for the first time, implements fMRI question answering. Additionally, BrainChat is highly flexible and can achieve high performance without image data, making it better suited for real-world scenarios with limited data.
6/13/2024