Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
2310.02980
0
0
🔮
Abstract
Modeling long-range dependencies across sequences is a longstanding goal in machine learning and has led to architectures, such as state space models, that dramatically outperform Transformers on long sequences. However, these impressive empirical gains have been by and large demonstrated on benchmarks (e.g. Long Range Arena), where models are randomly initialized and trained to predict a target label from an input sequence. In this work, we show that random initialization leads to gross overestimation of the differences between architectures and that pretraining with standard denoising objectives, using $textit{only the downstream task data}$, leads to dramatic gains across multiple architectures and to very small gaps between Transformers and state space models (SSMs). In stark contrast to prior works, we find vanilla Transformers to match the performance of S4 on Long Range Arena when properly pretrained, and we improve the best reported results of SSMs on the PathX-256 task by 20 absolute points. Subsequently, we analyze the utility of previously-proposed structured parameterizations for SSMs and show they become mostly redundant in the presence of data-driven initialization obtained through pretraining. Our work shows that, when evaluating different architectures on supervised tasks, incorporation of data-driven priors via pretraining is essential for reliable performance estimation, and can be done efficiently.
Create account to get full access
Overview
- This paper examines the impact of pretraining on the performance of different machine learning architectures, particularly Transformers and state space models (SSMs), on long sequence tasks.
- The authors find that random initialization leads to an overestimation of the differences between these architectures, and that pretraining with standard denoising objectives using only the downstream task data can dramatically improve the performance of all architectures, reducing the gaps between them.
- Surprisingly, the authors show that a vanilla Transformer can match the performance of the S4 model on the Long Range Arena benchmark when properly pretrained, and they improve the best reported results of SSMs on the PathX-256 task by a significant margin.
- The authors also analyze the utility of previously proposed structured parameterizations for SSMs and find them to be mostly redundant in the presence of data-driven initialization obtained through pretraining.
Plain English Explanation
The paper focuses on a longstanding challenge in machine learning: modeling long-range dependencies across sequences. State space models and other architectures have shown impressive empirical gains on this task, outperforming Transformers in benchmark tests. However, the authors argue that these gains are often due to the way the models are initialized, rather than inherent architectural differences.
The key insight is that when models are randomly initialized, as is common in benchmark testing, the differences between architectures appear much larger than they are in reality. But when the models are pretrained on the same data used for the downstream task, using standard denoising objectives, the performance gaps shrink dramatically. In fact, the authors show that a simple Transformer can match the performance of more specialized state space models when both are properly pretrained.
Moreover, the authors find that the structured parameterizations that have been proposed for state space models become largely unnecessary when the models are initialized with data-driven priors through pretraining. This suggests that the key to achieving high performance on long sequence tasks lies not in the architecture itself, but in the way the model is initialized and trained.
Overall, this paper highlights the importance of incorporating data-driven priors through pretraining when evaluating different machine learning architectures, and cautions against drawing conclusions about their relative merits based on randomly initialized benchmark results alone.
Technical Explanation
The paper explores the impact of pretraining on the performance of different machine learning architectures, particularly Transformers and state space models (SSMs), on long sequence tasks.
The authors first demonstrate that random initialization leads to a gross overestimation of the differences between these architectures, as is often the case in benchmark testing. They then show that pretraining with standard denoising objectives, using only the downstream task data, can dramatically improve the performance of all architectures and significantly reduce the gaps between them.
Surprisingly, the authors find that a vanilla Transformer can match the performance of the S4 model, a state-of-the-art SSM, on the Long Range Arena benchmark when properly pretrained. They also improve the best reported results of SSMs on the PathX-256 task by 20 absolute points.
Furthermore, the authors analyze the utility of previously proposed structured parameterizations for SSMs and find them to be mostly redundant in the presence of data-driven initialization obtained through pretraining. This suggests that the key to achieving high performance on long sequence tasks lies not in the architecture itself, but in the way the model is initialized and trained.
The paper's key contribution is the insight that incorporating data-driven priors via pretraining is essential for reliable performance estimation when evaluating different machine learning architectures, and that this can be done efficiently.
Critical Analysis
The paper makes a strong case for the importance of pretraining when evaluating different machine learning architectures, particularly on long sequence tasks. The authors' findings challenge the conventional wisdom that more specialized architectures like state space models are inherently better suited for modeling long-range dependencies.
However, the paper does not explore the potential limitations of this approach. For example, it's not clear how the pretraining strategy would scale to tasks with very limited downstream data, or how it might affect the generalization capabilities of the models. Additionally, the paper does not address the computational and memory requirements of the pretraining process, which could be a practical concern for some applications.
Furthermore, the paper does not delve into the underlying reasons why pretraining has such a dramatic impact on the performance of different architectures. A deeper exploration of the mechanisms at play could provide valuable insights into the nature of long-range dependencies and the best ways to model them.
Despite these potential limitations, the paper's key message is an important one: when evaluating the relative merits of machine learning architectures, it's critical to consider the impact of pretraining and not rely solely on randomly initialized benchmark results. This finding has broader implications for the field of machine learning and the way we assess and compare different models and approaches.
Conclusion
This paper challenges the conventional wisdom in machine learning by showing that the impressive gains of state space models over Transformers on long sequence tasks are largely due to the way the models are initialized, rather than inherent architectural differences. The authors demonstrate that pretraining with standard denoising objectives can dramatically improve the performance of all architectures, often reducing the gaps between them to negligible levels.
The paper's key insight is that incorporating data-driven priors through pretraining is essential for reliable performance estimation when evaluating different machine learning architectures. This finding has important implications for the field, as it suggests that the traditional benchmark-based approach to model evaluation may be biased and lead to misleading conclusions.
By highlighting the critical role of pretraining, this paper opens up new avenues for research and development in long sequence modeling, potentially leading to more efficient and effective architectures that can better capture long-range dependencies. It also raises important questions about the underlying mechanisms driving the success of pretraining and how these insights can be applied to a wide range of machine learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024

Repeat After Me: Transformers are Better than State Space Models at Copying
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, Eran Malach
0
0
Transformers are the dominant architecture for sequence modeling, but there is growing interest in models that use a fixed-size latent state that does not depend on the sequence length, which we refer to as generalized state space models (GSSMs). In this paper we show that while GSSMs are promising in terms of inference-time efficiency, they are limited compared to transformer models on tasks that require copying from the input context. We start with a theoretical analysis of the simple task of string copying and prove that a two layer transformer can copy strings of exponential length while GSSMs are fundamentally limited by their fixed-size latent state. Empirically, we find that transformers outperform GSSMs in terms of efficiency and generalization on synthetic tasks that require copying the context. Finally, we evaluate pretrained large language models and find that transformer models dramatically outperform state space models at copying and retrieving information from context. Taken together, these results suggest a fundamental gap between transformers and GSSMs on tasks of practical interest.
6/5/2024

State-Space Modeling in Long Sequence Processing: A Survey on Recurrence in the Transformer Era
Matteo Tiezzi, Michele Casoni, Alessandro Betti, Marco Gori, Stefano Melacci
0
0
Effectively learning from sequential data is a longstanding goal of Artificial Intelligence, especially in the case of long sequences. From the dawn of Machine Learning, several researchers engaged in the search of algorithms and architectures capable of processing sequences of patterns, retaining information about the past inputs while still leveraging the upcoming data, without losing precious long-term dependencies and correlations. While such an ultimate goal is inspired by the human hallmark of continuous real-time processing of sensory information, several solutions simplified the learning paradigm by artificially limiting the processed context or dealing with sequences of limited length, given in advance. These solutions were further emphasized by the large ubiquity of Transformers, that have initially shaded the role of Recurrent Neural Nets. However, recurrent networks are facing a strong recent revival due to the growing popularity of (deep) State-Space models and novel instances of large-context Transformers, which are both based on recurrent computations to go beyond several limits of currently ubiquitous technologies. In fact, the fast development of Large Language Models enhanced the interest in efficient solutions to process data over time. This survey provides an in-depth summary of the latest approaches that are based on recurrent models for sequential data processing. A complete taxonomy over the latest trends in architectural and algorithmic solutions is reported and discussed, guiding researchers in this appealing research field. The emerging picture suggests that there is room for thinking of novel routes, constituted by learning algorithms which depart from the standard Backpropagation Through Time, towards a more realistic scenario where patterns are effectively processed online, leveraging local-forward computations, opening to further research on this topic.
6/14/2024
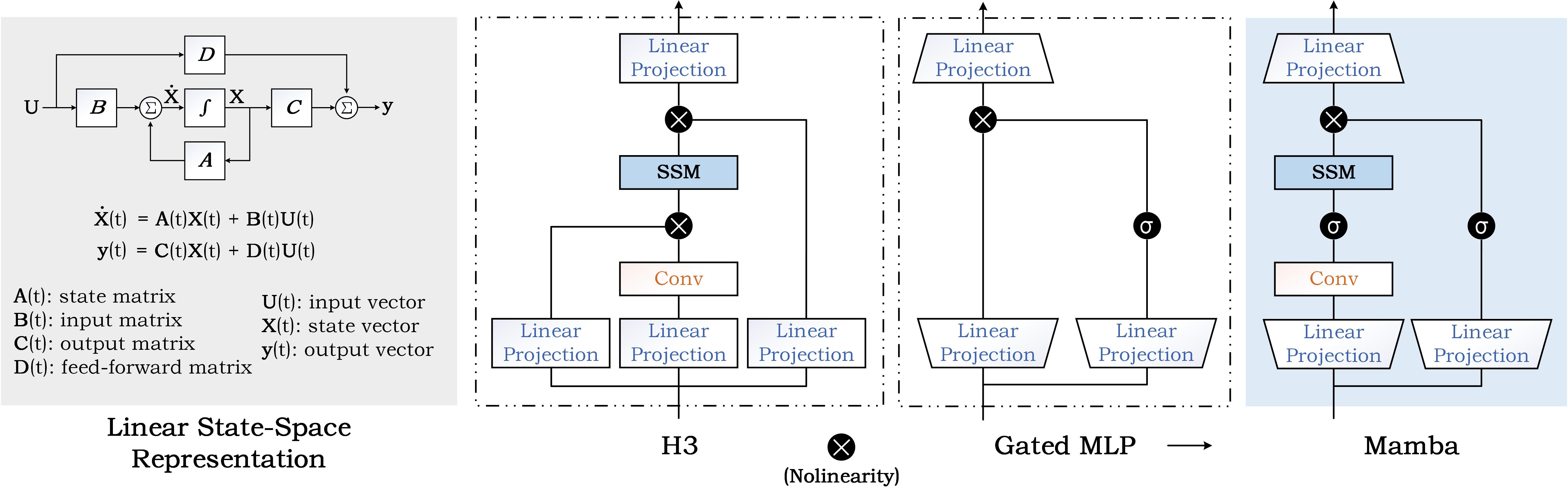
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Xiao Wang, Shiao Wang, Yuhe Ding, Yuehang Li, Wentao Wu, Yao Rong, Weizhe Kong, Ju Huang, Shihao Li, Haoxiang Yang, Ziwen Wang, Bo Jiang, Chenglong Li, Yaowei Wang, Yonghong Tian, Jin Tang
0
0
In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
4/16/2024