Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
2406.08426
0
0
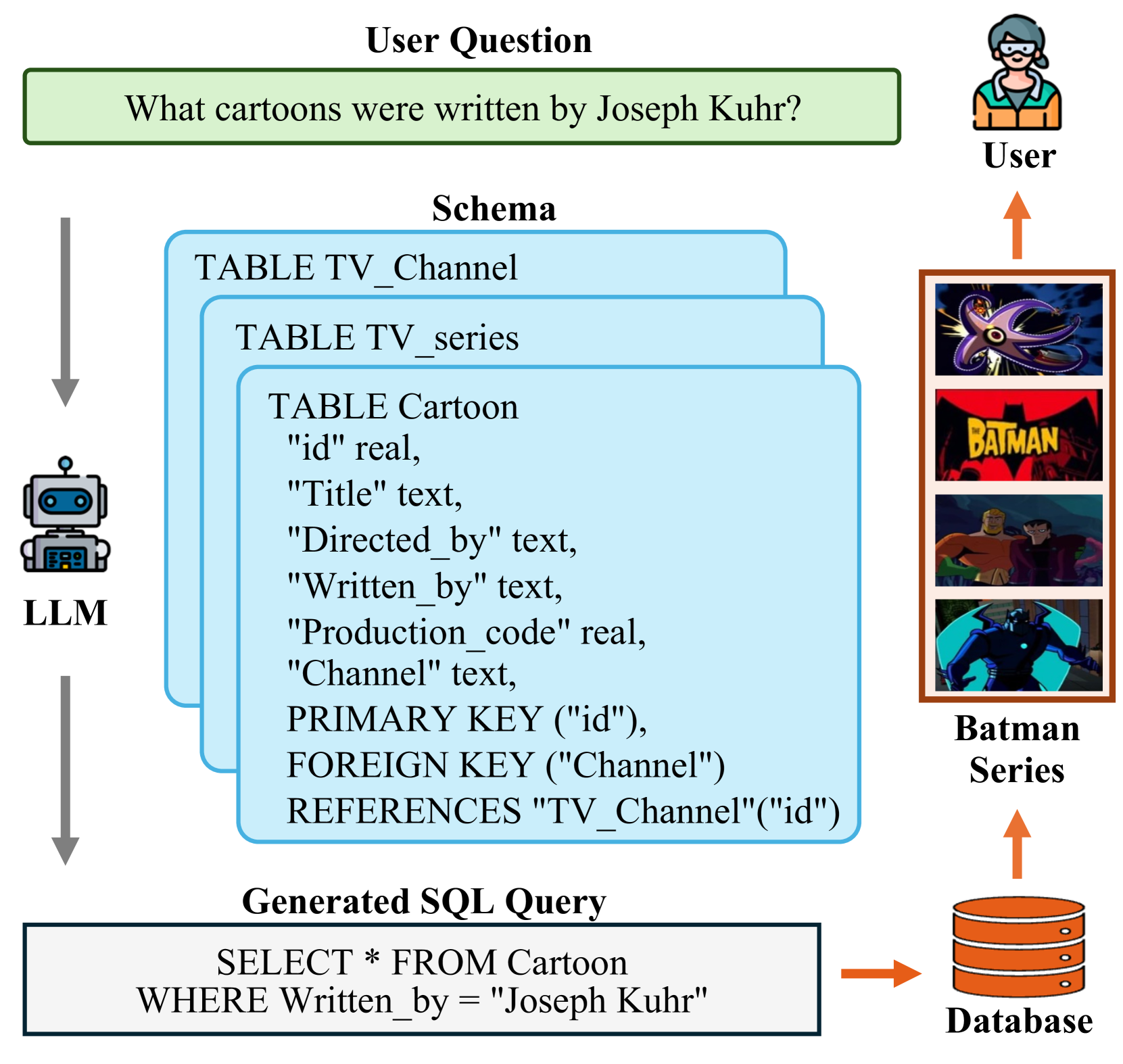
Abstract
Generating accurate SQL according to natural language questions (text-to-SQL) is a long-standing challenge due to the complexities involved in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems, comprising human engineering and deep neural networks, have made substantial progress. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex, the corresponding user questions also grow more challenging, leading PLMs with limited comprehension capabilities to produce incorrect SQL. This necessitates more sophisticated and tailored optimization methods for PLMs, which, in turn, restricts the applications of PLM-based systems. Most recently, large language models (LLMs) have demonstrated significant capabilities in natural language understanding as the model scale remains increasing. Therefore, integrating the LLM-based implementation can bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the technical challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future research directions.
Create account to get full access
Overview
This paper provides a comprehensive survey of large language model (LLM)-based text-to-SQL systems, which aim to allow users to interact with databases using natural language queries. These systems have the potential to significantly improve database accessibility by enabling more intuitive and user-friendly querying. The authors review the current state-of-the-art in this field, covering key architectures, datasets, and benchmarks, as well as highlighting areas for future research and development.
Plain English Explanation
Databases are essential for storing and managing large amounts of information, but traditional ways of querying them can be complex and difficult for non-technical users. This paper explores a new approach that uses powerful language models, known as large language models (LLMs), to bridge the gap between natural language and database queries.
The core idea is to train these LLMs to understand natural language questions and then translate them into the structured language of SQL, which is used to query databases. This allows users to simply ask questions in plain English, rather than having to learn the specific syntax and commands of SQL.
For example, a user could ask "What are the total sales for each product in the last quarter?" and the text-to-SQL system would automatically generate the appropriate SQL query to retrieve that information from the database.
The authors review the latest advancements in this field, examining the different architectures and techniques that researchers have developed to make these text-to-SQL systems more accurate, efficient, and user-friendly. They also discuss the datasets and benchmarks used to evaluate the performance of these systems, and highlight areas where further research and development is needed.
Overall, the goal of this work is to make databases more accessible and useful for a wider range of users, by leveraging the power of modern language models to bridge the gap between natural language and the technical world of databases.
Technical Explanation
The paper begins by providing an overview of the text-to-SQL problem and the motivations for developing LLM-based approaches. The authors then review the key architectural components of these systems, which typically include:
-
Natural Language Understanding (NLU): The LLM-based component responsible for parsing the user's natural language query and extracting the relevant semantic information.
-
SQL Generation: The component that takes the output of the NLU module and generates the corresponding SQL query.
-
Database Interface: The component that interacts with the underlying database to execute the generated SQL query and return the results to the user.
The authors also discuss the various datasets and benchmarks that have been developed to evaluate the performance of text-to-SQL systems, such as Spider, WikiSQL, and CHESS. They highlight the strengths and limitations of these datasets, and how they have shaped the development of the field.
Furthermore, the paper covers the key technical innovations that have driven progress in LLM-based text-to-SQL, such as the use of program synthesis techniques to generate SQL queries, knowledge-enhanced approaches that leverage external information sources, and context-aware models that can handle more complex, multi-turn interactions.
The authors also discuss the potential applications of these text-to-SQL systems, such as enabling more accessible and intuitive data querying and visualization for non-technical users, as well as integrating them into task-oriented dialogue systems to enhance user productivity and decision-making.
Critical Analysis
The paper provides a thorough and well-researched overview of the current state-of-the-art in LLM-based text-to-SQL systems. The authors do a commendable job of highlighting the key technical advancements and the various datasets and benchmarks used to evaluate these systems.
One potential area for improvement is the discussion of the limitations and challenges faced by these text-to-SQL systems. While the paper does touch on some of these, such as the need for better handling of complex queries and domain-specific knowledge integration, a more in-depth analysis of these issues and potential solutions could have been beneficial.
Additionally, the paper does not delve into the ethical and societal implications of these technologies, such as the potential for bias and fairness issues, or the impact on the job market for database administrators and other technical roles. These are important considerations that should be addressed as the field continues to develop.
Conclusion
Overall, this paper provides a comprehensive survey of the latest advancements in LLM-based text-to-SQL systems, highlighting the significant progress that has been made in this field and the promising future applications of these technologies. The authors' thorough review of the technical details and the state of the art in the field makes this paper a valuable resource for researchers and practitioners working in this area.
As these text-to-SQL systems continue to evolve and become more sophisticated, they have the potential to revolutionize the way users interact with databases, making them more accessible and user-friendly for a wider range of applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Knowledge-to-SQL: Enhancing SQL Generation with Data Expert LLM
Zijin Hong, Zheng Yuan, Hao Chen, Qinggang Zhang, Feiran Huang, Xiao Huang
0
0
Generating accurate SQL queries for user questions (text-to-SQL) has been a long-standing challenge since it requires a deep understanding of both the user's question and the corresponding database schema in order to retrieve the desired content accurately. Existing methods rely on the comprehensive capability of large language models (LLMs) to generate the SQL. However, some necessary knowledge is not explicitly included in the database schema and user question or has been learned by LLMs. Thus, the generated SQL of the knowledge-insufficient questions may be inaccurate, negatively influencing the text-to-SQL models' performance and robustness. To address this challenge, we propose the Knowledge-to-SQL framework, which employs tailored Data Expert LLM (DELLM) to provide helpful knowledge for all text-to-SQL models. Specifically, we introduce the detailed implementation of DELLM regarding table reading and the basic fine-tuning process. We further propose a Preference Learning via Database Feedback (PLDBF) strategy, refining the DELLM to generate more helpful knowledge for LLMs. Extensive experiments verify that DELLM can enhance the state-of-the-art approaches for text-to-SQL tasks. The corresponding code of DELLM is released for further research.
6/7/2024
📊
Evaluating the Data Model Robustness of Text-to-SQL Systems Based on Real User Queries
Jonathan Furst, Catherine Kosten, Farhard Nooralahzadeh, Yi Zhang, Kurt Stockinger
0
0
Text-to-SQL systems (also known as NL-to-SQL systems) have become an increasingly popular solution for bridging the gap between user capabilities and SQL-based data access. These systems translate user requests in natural language to valid SQL statements for a specific database. Recent Text-to-SQL systems have benefited from the rapid improvement of transformer-based language models. However, while Text-to-SQL systems that incorporate such models continuously reach new high scores on -- often synthetic -- benchmark datasets, a systematic exploration of their robustness towards different data models in a real-world, realistic scenario is notably missing. This paper provides the first in-depth evaluation of the data model robustness of Text-to-SQL systems in practice based on a multi-year international project focused on Text-to-SQL interfaces. Our evaluation is based on a real-world deployment of FootballDB, a system that was deployed over a 9 month period in the context of the FIFA World Cup 2022, during which about 6K natural language questions were asked and executed. All of our data is based on real user questions that were asked live to the system. We manually labeled and translated a subset of these questions for three different data models. For each data model, we explore the performance of representative Text-to-SQL systems and language models. We further quantify the impact of training data size, pre-, and post-processing steps as well as language model inference time. Our comprehensive evaluation sheds light on the design choices of real-world Text-to-SQL systems and their impact on moving from research prototypes to real deployments. Last, we provide a new benchmark dataset to the community, which is the first to enable the evaluation of different data models for the same dataset and is substantially more challenging than most previous datasets in terms of query complexity.
6/19/2024

End-to-end Text-to-SQL Generation within an Analytics Insight Engine
Karime Maamari, Amine Mhedhbi
0
0
Recent advancements in Text-to-SQL have pushed database management systems towards greater democratization of data access. Today's language models are at the core of these advancements. They enable impressive Text-to-SQL generation as experienced in the development of Distyl AI's Analytics Insight Engine. Its early deployment with enterprise customers has highlighted three core challenges. First, data analysts expect support with authoring SQL queries of very high complexity. Second, requests are ad-hoc and, as such, require low latency. Finally, generation requires an understanding of domain-specific terminology and practices. The design and implementation of our Text-to-SQL generation pipeline, powered by large language models, tackles these challenges. The core tenants of our approach rely on external knowledge that we extract in a pre-processing phase, on retrieving the appropriate external knowledge at query generation time, and on decomposing SQL query generation following a hierarchical CTE-based structure. Finally, an adaptation framework leverages feedback to update the external knowledge, in turn improving query generation over time. We give an overview of our end-to-end approach and highlight the operators generating SQL during inference.
6/19/2024
Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models
Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, Min Yang
0
0
Despite the success of large language models (LLMs) in Text-to-SQL tasks, open-source LLMs encounter challenges in contextual understanding and response coherence. To tackle these issues, we present ours, a systematic methodology tailored for Text-to-SQL with open-source LLMs. Our contributions include a comprehensive evaluation of open-source LLMs in Text-to-SQL tasks, the openprompt strategy for effective question representation, and novel strategies for supervised fine-tuning. We explore the benefits of Chain-of-Thought in step-by-step inference and propose the openexample method for enhanced few-shot learning. Additionally, we introduce token-efficient techniques, such as textbf{Variable-length Open DB Schema}, textbf{Target Column Truncation}, and textbf{Example Column Truncation}, addressing challenges in large-scale databases. Our findings emphasize the need for further investigation into the impact of supervised fine-tuning on contextual learning capabilities. Remarkably, our method significantly improved Llama2-7B from 2.54% to 41.04% and Code Llama-7B from 14.54% to 48.24% on the BIRD-Dev dataset. Notably, the performance of Code Llama-7B surpassed GPT-4 (46.35%) on the BIRD-Dev dataset.
5/14/2024