One Thousand and One Pairs: A novel challenge for long-context language models
2406.16264
0
0
Abstract
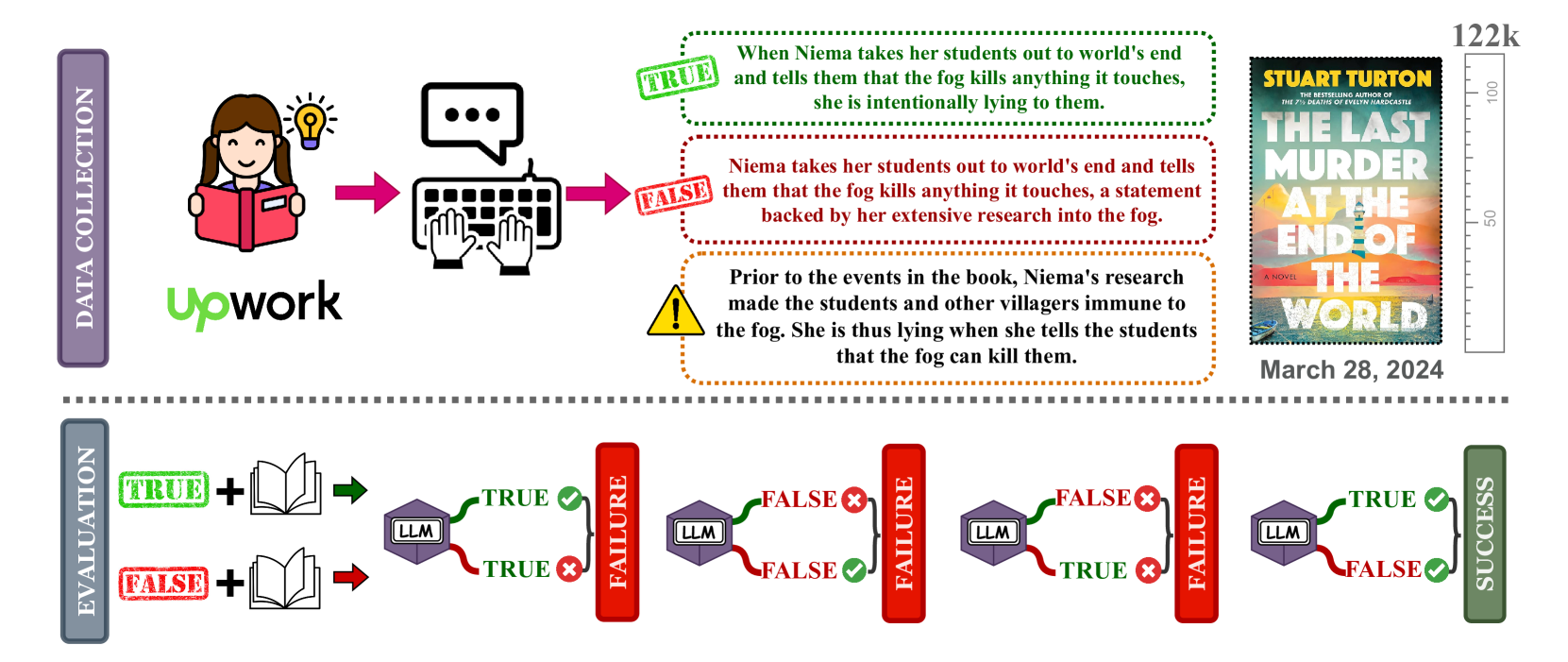
Synthetic long-context LLM benchmarks (e.g., needle-in-the-haystack) test only surface-level retrieval capabilities, but how well can long-context LLMs retrieve, synthesize, and reason over information across book-length inputs? We address this question by creating NoCha, a dataset of 1,001 minimally different pairs of true and false claims about 67 recently-published English fictional books, written by human readers of those books. In contrast to existing long-context benchmarks, our annotators confirm that the largest share of pairs in NoCha require global reasoning over the entire book to verify. Our experiments show that while human readers easily perform this task, it is enormously challenging for all ten long-context LLMs that we evaluate: no open-weight model performs above random chance (despite their strong performance on synthetic benchmarks), while GPT-4o achieves the highest accuracy at 55.8%. Further analysis reveals that (1) on average, models perform much better on pairs that require only sentence-level retrieval vs. global reasoning; (2) model-generated explanations for their decisions are often inaccurate even for correctly-labeled claims; and (3) models perform substantially worse on speculative fiction books that contain extensive world-building. The methodology proposed in NoCha allows for the evolution of the benchmark dataset and the easy analysis of future models.
Create account to get full access
Overview
- This paper introduces a new challenge called "One Thousand and One Pairs" (1001P) for evaluating the ability of long-context language models to understand and reason about extended narratives.
- The 1001P challenge involves generating a coherent continuation of a story given a long, multi-paragraph prompt, with the goal of matching a human-written reference continuation.
- The authors create a large dataset of over 1,000 such story prompt-continuation pairs, drawing from a variety of genres and domains, to serve as a benchmark for this task.
Plain English Explanation
The researchers have developed a new test to see how well AI language models can understand and continue long stories. Current AI models are often limited to processing just a few sentences at a time, but many real-world tasks involve comprehending and building upon extended narratives.
The "One Thousand and One Pairs" (1001P) challenge presents language models with a paragraph-length story prompt and asks them to generate a coherent continuation that matches a human-written reference. The dataset includes over 1,000 of these prompt-continuation pairs, covering a diverse range of genres and topics. This provides a comprehensive benchmark to evaluate the long-context understanding capabilities of AI systems.
The goal is to push the boundaries of what language models can do, moving beyond their typical short-range processing to tackle more complex, open-ended storytelling. By creating this challenging new test, the researchers aim to spur progress in developing AI systems that can engage with and build upon extended pieces of text, just as humans do.
Technical Explanation
The authors introduce the "One Thousand and One Pairs" (1001P) challenge to assess the ability of long-context language models to understand and generate coherent continuations of extended narratives. The 1001P dataset consists of over 1,000 prompt-continuation pairs, where each prompt is a multi-paragraph text and the continuation is a human-written response intended to naturally follow the prompt.
The prompts are drawn from a variety of sources, including books, articles, and creative writing, spanning genres such as fiction, non-fiction, and poetry. The continuations are generated by human authors to provide high-quality reference texts that language models can be evaluated against.
To complete the 1001P challenge, a language model must read the given prompt, which can be hundreds or even thousands of tokens long, and then generate a continuation that is both coherent and semantically consistent with the original text. This requires the model to maintain a long-term understanding of the narrative and use that context to produce a plausible next step in the story.
The authors propose several evaluation metrics to assess the performance of language models on the 1001P task, including measures of semantic similarity, coherence, and factual consistency between the model's output and the human-written reference. By providing this benchmark, the researchers aim to drive progress in developing AI systems capable of engaging with and building upon extended pieces of text, a key capability for many real-world applications.
Critical Analysis
The 1001P challenge represents an important step forward in evaluating the long-context understanding capabilities of language models. By focusing on extended narratives rather than just short passages, the benchmark addresses a crucial limitation of current AI systems, which often struggle to maintain coherence and consistency over long stretches of text.
However, the authors acknowledge that the 1001P task is still relatively narrow in scope, focusing primarily on story continuation. There may be other types of long-context reasoning, such as question answering or summarization, that require different capabilities and should also be explored.
Additionally, the evaluation metrics used in the 1001P challenge, while comprehensive, may not capture all aspects of what constitutes a "good" continuation. Subjective factors like creativity, emotional resonance, and literary merit could also be important considerations, but are difficult to quantify.
Future research could explore ways to expand the 1001P benchmark or develop complementary tests to push the boundaries of long-context understanding even further. Combining the 1001P challenge with other long-context benchmarks or conversational QA tasks could provide a more comprehensive assessment of a language model's abilities.
Conclusion
The "One Thousand and One Pairs" (1001P) challenge represents an important step forward in evaluating the long-context understanding capabilities of language models. By focusing on the task of generating coherent continuations for extended narratives, the benchmark pushes AI systems beyond their typical short-range processing and towards more human-like comprehension of extended pieces of text.
The large, diverse dataset of prompt-continuation pairs provides a comprehensive test bed for assessing language models' ability to maintain coherence, consistency, and plausibility over long stretches of discourse. This advance could have significant implications for a wide range of real-world applications, from interactive storytelling to long-form question answering and beyond.
While the 1001P challenge is a valuable contribution, there is still room for further research to expand the scope of long-context evaluation and develop even more demanding benchmarks. By continuing to push the boundaries of what language models can do, the field of AI can make steady progress towards systems that can engage with and reason about the world in ways that more closely resemble human cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

NovelQA: Benchmarking Question Answering on Documents Exceeding 200K Tokens
Cunxiang Wang, Ruoxi Ning, Boqi Pan, Tonghui Wu, Qipeng Guo, Cheng Deng, Guangsheng Bao, Xiangkun Hu, Zheng Zhang, Qian Wang, Yue Zhang
0
0
The rapid advancement of Large Language Models (LLMs) has introduced a new frontier in natural language processing, particularly in understanding and processing long-context information. However, the evaluation of these models' long-context abilities remains a challenge due to the limitations of current benchmarks. To address this gap, we introduce NovelQA, a benchmark specifically designed to test the capabilities of LLMs with extended texts. Constructed from English novels, NovelQA offers a unique blend of complexity, length, and narrative coherence, making it an ideal tool for assessing deep textual understanding in LLMs. This paper presents the design and construction of NovelQA, highlighting its manual annotation, and diverse question types. Our evaluation of Long-context LLMs on NovelQA reveals significant insights into the models' performance, particularly emphasizing the challenges they face with multi-hop reasoning, detail-oriented questions, and extremely long input with an average length more than 200,000 tokens. The results underscore the necessity for further advancements in LLMs to improve their long-context comprehension.
6/18/2024
🛸
Long-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
Bernd Bohnet, Kevin Swersky, Rosanne Liu, Pranjal Awasthi, Azade Nova, Javier Snaider, Hanie Sedghi, Aaron T Parisi, Michael Collins, Angeliki Lazaridou, Orhan Firat, Noah Fiedel
0
0
We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
6/4/2024
🤔
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, Juanzi Li
0
0
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending context windows and more sophisticated memory mechanisms. However, comprehensive benchmarks tailored for evaluating long context understanding are lacking. In this paper, we introduce LongBench, the first bilingual, multi-task benchmark for long context understanding, enabling a more rigorous evaluation of long context understanding. LongBench comprises 21 datasets across 6 task categories in both English and Chinese, with an average length of 6,711 words (English) and 13,386 characters (Chinese). These tasks cover key long-text application areas including single-doc QA, multi-doc QA, summarization, few-shot learning, synthetic tasks, and code completion. All datasets in LongBench are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Upon comprehensive evaluation of 8 LLMs on LongBench, we find that: (1) Commercial model (GPT-3.5-Turbo-16k) outperforms other open-sourced models, but still struggles on longer contexts. (2) Scaled position embedding and fine-tuning on longer sequences lead to substantial improvement on long context understanding. (3) Context compression technique such as retrieval brings improvement for model with weak ability on long contexts, but the performance still lags behind models that have strong long context understanding capability. The code and datasets are available at https://github.com/THUDM/LongBench.
6/21/2024

BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, Mikhail Burtsev
0
0
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
6/17/2024