Optimizing the Deployment of Tiny Transformers on Low-Power MCUs
2404.02945
0
0
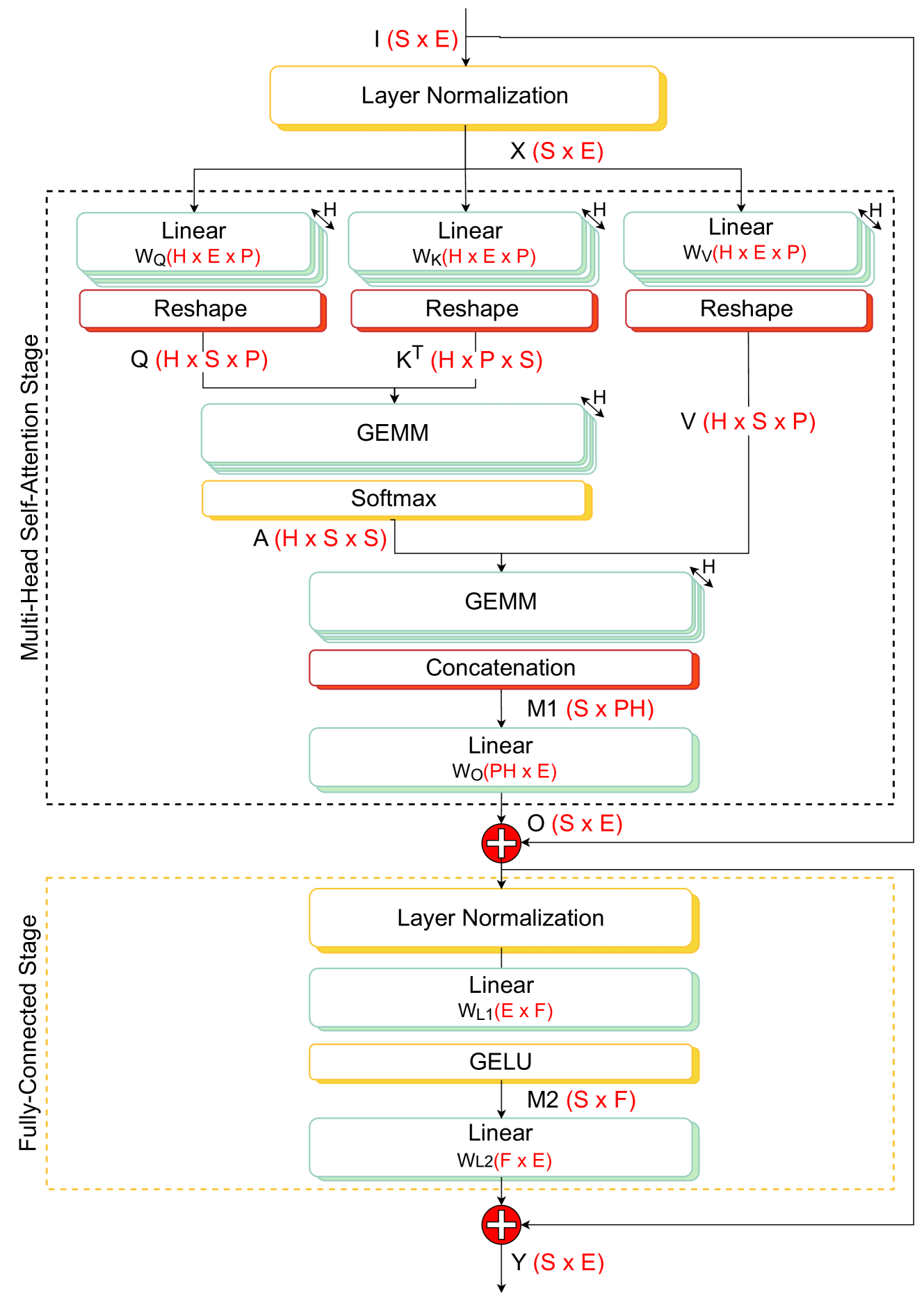
Abstract
Transformer networks are rapidly becoming SotA in many fields, such as NLP and CV. Similarly to CNN, there is a strong push for deploying Transformer models at the extreme edge, ultimately fitting the tiny power budget and memory footprint of MCUs. However, the early approaches in this direction are mostly ad-hoc, platform, and model-specific. This work aims to enable and optimize the flexible, multi-platform deployment of encoder Tiny Transformers on commercial MCUs. We propose a complete framework to perform end-to-end deployment of Transformer models onto single and multi-core MCUs. Our framework provides an optimized library of kernels to maximize data reuse and avoid unnecessary data marshaling operations into the crucial attention block. A novel MHSA inference schedule, named Fused-Weight Self-Attention, is introduced, fusing the linear projection weights offline to further reduce the number of operations and parameters. Furthermore, to mitigate the memory peak reached by the computation of the attention map, we present a Depth-First Tiling scheme for MHSA. We evaluate our framework on three different MCU classes exploiting ARM and RISC-V ISA, namely the STM32H7, the STM32L4, and GAP9 (RV32IMC-XpulpV2). We reach an average of 4.79x and 2.0x lower latency compared to SotA libraries CMSIS-NN (ARM) and PULP-NN (RISC-V), respectively. Moreover, we show that our MHSA depth-first tiling scheme reduces the memory peak by up to 6.19x, while the fused-weight attention can reduce the runtime by 1.53x, and number of parameters by 25%. We report significant improvements across several Tiny Transformers: for instance, when executing a transformer block for the task of radar-based hand-gesture recognition on GAP9, we achieve a latency of 0.14ms and energy consumption of 4.92 micro-joules, 2.32x lower than the SotA PULP-NN library on the same platform.
Create account to get full access
Overview
- This paper explores optimizing the deployment of tiny transformer models on low-power microcontroller units (MCUs) for edge computing applications.
- Tiny transformer models are small neural network architectures that can run efficiently on resource-constrained devices like MCUs.
- The researchers investigate methods to further improve the performance and efficiency of these tiny transformer models when deployed on low-power MCUs.
Plain English Explanation
Transformer models are a powerful type of artificial intelligence that have revolutionized many areas of technology, from natural language processing to computer vision. However, these models are typically large and complex, making them challenging to run on small, low-power devices like the microcontrollers found in many everyday products.
The researchers in this paper looked at ways to take these powerful transformer models and shrink them down to "tiny" versions that can still perform well while using much less memory and computing power. Tiny transformer models could enable all sorts of exciting new applications on resource-constrained devices at the "edge" of the network, closer to where data is generated, rather than relying on sending data to far-away cloud servers.
The key is finding the right balance - how can you maintain the beneficial capabilities of transformers while also drastically reducing their size and power requirements? The researchers explore various optimization techniques, like pruning away unnecessary parts of the model and quantizing the numerical representations to use less memory. They then test these optimized tiny transformer models on real low-power MCU hardware to measure the improvements in speed, efficiency, and accuracy.
Technical Explanation
The paper begins by providing background on the rise of transformer models and their increasing use in edge computing applications. However, deploying large, complex transformer models on resource-constrained MCU platforms remains challenging.
The researchers propose a framework for optimizing the deployment of "tiny transformers" on low-power MCUs. They explore several key techniques:
-
Model Pruning - Identifying and removing the least important parts of the transformer model to reduce its size and complexity without significantly impacting accuracy.
-
Weight Quantization - Reducing the numerical precision of the model's weight parameters, allowing for more compact storage and faster computation on the MCU.
-
Layer Fusion - Combining adjacent transformer layers to further decrease the model's footprint.
-
Hardware-aware Design - Tailoring the model architecture and optimizations to take advantage of the specific hardware capabilities of the target MCU platform.
The researchers implement these optimization techniques and evaluate the resulting tiny transformer models on real MCU hardware, measuring metrics like inference latency, energy consumption, and accuracy. They demonstrate significant improvements in efficiency while maintaining high performance, paving the way for powerful AI capabilities on low-power edge devices.
Critical Analysis
The paper provides a thorough and well-designed study of optimizing tiny transformer models for MCU deployment. The researchers cover a comprehensive set of optimization techniques and rigorously evaluate their approaches on real hardware.
One potential limitation is that the study is focused on a single target MCU platform (the Arm Cortex-M7). While this allows for deep hardware-specific optimizations, the generalizability of the findings to other MCU architectures is not fully addressed. Further exploration of the techniques across a wider range of low-power MCU platforms could strengthen the broader applicability of the research.
Additionally, the paper does not delve into the potential privacy and security implications of deploying increasingly powerful AI models at the network edge. As these capabilities become more ubiquitous in consumer devices, important questions around data privacy, model security, and potential misuse will need to be carefully considered.
Overall, this work represents an important advancement in enabling the deployment of efficient, high-performing transformer models on low-power embedded systems. The insights and techniques presented could have significant impact on the development of intelligent edge devices across a wide range of application domains.
Conclusion
This paper addresses a critical challenge in the field of edge computing - how to effectively deploy powerful deep learning models, like transformers, on resource-constrained microcontroller platforms. Through a comprehensive set of optimization techniques, the researchers demonstrate significant improvements in the efficiency and performance of "tiny transformer" models running on low-power MCUs.
The ability to run advanced AI capabilities directly on edge devices, rather than relying on cloud connectivity, opens up a wealth of new possibilities for intelligent, autonomous systems. This research represents an important step towards realizing the full potential of edge computing and bringing cutting-edge machine learning to a wide range of everyday applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
TinyTrain: Resource-Aware Task-Adaptive Sparse Training of DNNs at the Data-Scarce Edge
Young D. Kwon, Rui Li, Stylianos I. Venieris, Jagmohan Chauhan, Nicholas D. Lane, Cecilia Mascolo
0
0
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCUs), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss (>10%). In this paper, we propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel to update based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0% in accuracy, while reducing the backward-pass memory and computation cost by up to 1,098x and 7.68x, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5x faster and 3.5x more energy-efficient training over status-quo approaches, and 2.23x smaller memory footprint than SOTA methods, while remaining within the 1 MB memory envelope of MCU-grade platforms.
6/12/2024

Optimizing Foundation Model Inference on a Many-tiny-core Open-source RISC-V Platform
Viviane Potocnik, Luca Colagrande, Tim Fischer, Luca Bertaccini, Daniele Jahier Pagliari, Alessio Burrello, Luca Benini
0
0
Transformer-based foundation models have become crucial for various domains, most notably natural language processing (NLP) or computer vision (CV). These models are predominantly deployed on high-performance GPUs or hardwired accelerators with highly customized, proprietary instruction sets. Until now, limited attention has been given to RISC-V-based general-purpose platforms. In our work, we present the first end-to-end inference results of transformer models on an open-source many-tiny-core RISC-V platform implementing distributed Softmax primitives and leveraging ISA extensions for SIMD floating-point operand streaming and instruction repetition, as well as specialized DMA engines to minimize costly main memory accesses and to tolerate their latency. We focus on two foundational transformer topologies, encoder-only and decoder-only models. For encoder-only models, we demonstrate a speedup of up to 12.8x between the most optimized implementation and the baseline version. We reach over 79% FPU utilization and 294 GFLOPS/W, outperforming State-of-the-Art (SoA) accelerators by more than 2x utilizing the HW platform while achieving comparable throughput per computational unit. For decoder-only topologies, we achieve 16.1x speedup in the Non-Autoregressive (NAR) mode and up to 35.6x speedup in the Autoregressive (AR) mode compared to the baseline implementation. Compared to the best SoA dedicated accelerator, we achieve 2.04x higher FPU utilization.
5/30/2024
🤖
On TinyML and Cybersecurity: Electric Vehicle Charging Infrastructure Use Case
Fatemeh Dehrouyeh, Li Yang, Firouz Badrkhani Ajaei, Abdallah Shami
0
0
As technology advances, the use of Machine Learning (ML) in cybersecurity is becoming increasingly crucial to tackle the growing complexity of cyber threats. While traditional ML models can enhance cybersecurity, their high energy and resource demands limit their applications, leading to the emergence of Tiny Machine Learning (TinyML) as a more suitable solution for resource-constrained environments. TinyML is widely applied in areas such as smart homes, healthcare, and industrial automation. TinyML focuses on optimizing ML algorithms for small, low-power devices, enabling intelligent data processing directly on edge devices. This paper provides a comprehensive review of common challenges of TinyML techniques, such as power consumption, limited memory, and computational constraints; it also explores potential solutions to these challenges, such as energy harvesting, computational optimization techniques, and transfer learning for privacy preservation. On the other hand, this paper discusses TinyML's applications in advancing cybersecurity for Electric Vehicle Charging Infrastructures (EVCIs) as a representative use case. It presents an experimental case study that enhances cybersecurity in EVCI using TinyML, evaluated against traditional ML in terms of reduced delay and memory usage, with a slight trade-off in accuracy. Additionally, the study includes a practical setup using the ESP32 microcontroller in the PlatformIO environment, which provides a hands-on assessment of TinyML's application in cybersecurity for EVCI.
5/1/2024
📈
TinySeg: Model Optimizing Framework for Image Segmentation on Tiny Embedded Systems
Byungchul Chae, Jiae Kim, Seonyeong Heo
0
0
Image segmentation is one of the major computer vision tasks, which is applicable in a variety of domains, such as autonomous navigation of an unmanned aerial vehicle. However, image segmentation cannot easily materialize on tiny embedded systems because image segmentation models generally have high peak memory usage due to their architectural characteristics. This work finds that image segmentation models unnecessarily require large memory space with an existing tiny machine learning framework. That is, the existing framework cannot effectively manage the memory space for the image segmentation models. This work proposes TinySeg, a new model optimizing framework that enables memory-efficient image segmentation for tiny embedded systems. TinySeg analyzes the lifetimes of tensors in the target model and identifies long-living tensors. Then, TinySeg optimizes the memory usage of the target model mainly with two methods: (i) tensor spilling into local or remote storage and (ii) fused fetching of spilled tensors. This work implements TinySeg on top of the existing tiny machine learning framework and demonstrates that TinySeg can reduce the peak memory usage of an image segmentation model by 39.3% for tiny embedded systems.
5/6/2024