ORLM: Training Large Language Models for Optimization Modeling
2405.17743
0
0
Abstract
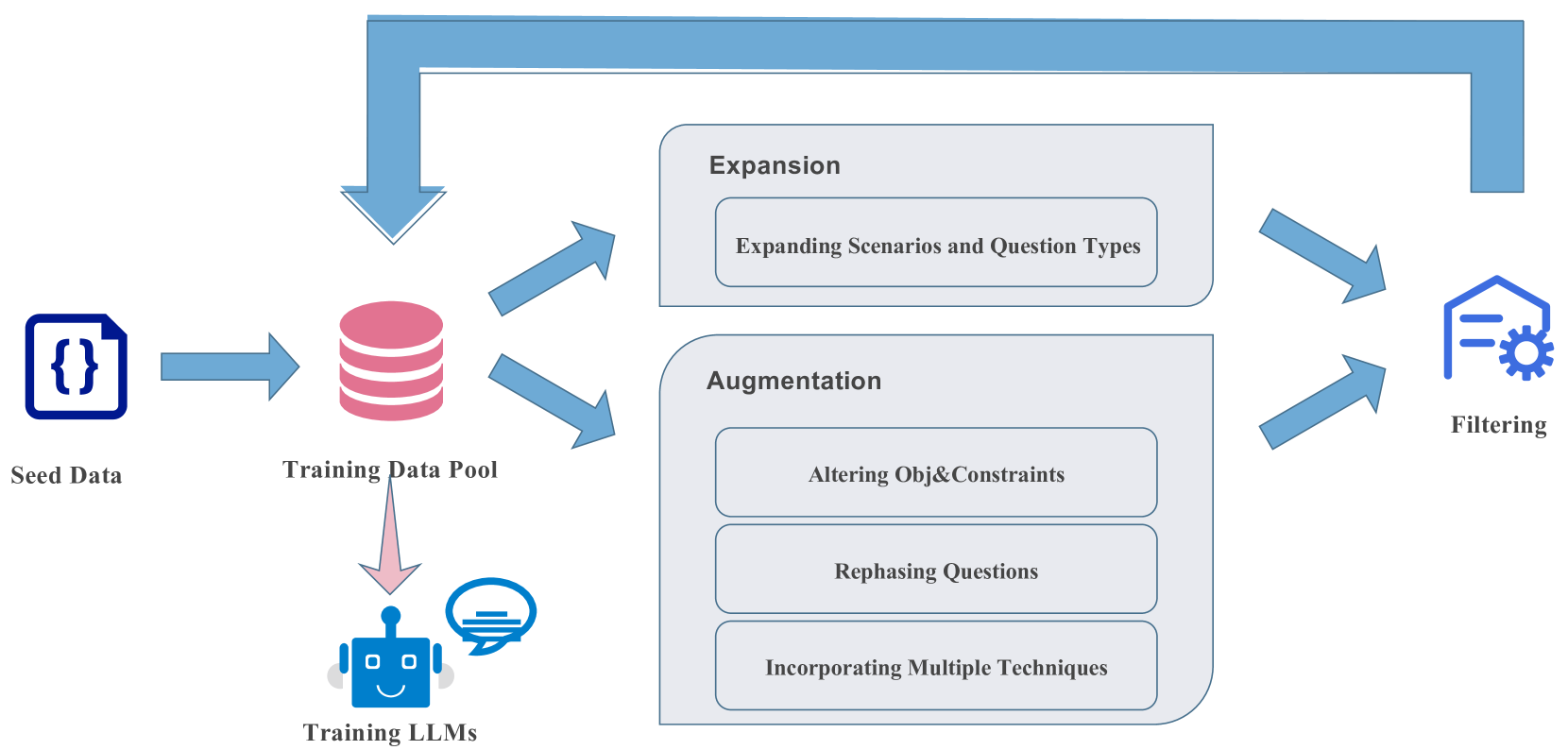
Large Language Models (LLMs) have emerged as powerful tools for tackling complex Operations Research (OR) problem by providing the capacity in automating optimization modeling. However, current methodologies heavily rely on prompt engineering (e.g., multi-agent cooperation) with proprietary LLMs, raising data privacy concerns that could be prohibitive in industry applications. To tackle this issue, we propose training open-source LLMs for optimization modeling. We identify four critical requirements for the training dataset of OR LLMs, design and implement OR-Instruct, a semi-automated process for creating synthetic data tailored to specific requirements. We also introduce the IndustryOR benchmark, the first industrial benchmark for testing LLMs on solving real-world OR problems. We apply the data from OR-Instruct to various open-source LLMs of 7b size (termed as ORLMs), resulting in a significantly improved capability for optimization modeling. Our best-performing ORLM achieves state-of-the-art performance on the NL4OPT, MAMO, and IndustryOR benchmarks. Our code and data are available at url{https://github.com/Cardinal-Operations/ORLM}.
Create account to get full access
Overview
- This paper introduces ORLM, a new approach to training large language models (LLMs) for optimization modeling tasks.
- The researchers aim to develop LLMs that can effectively assist humans with complex optimization problems, such as scheduling, resource allocation, and decision-making.
- Key aspects of the ORLM approach include incorporating domain-specific knowledge, leveraging reinforcement learning, and introducing a novel loss function to better align the LLM's outputs with optimal solutions.
Plain English Explanation
The paper presents a new way to train large language models (LLMs) so they can help people solve complex optimization problems. Optimization problems involve finding the best solution from many possible choices, like scheduling tasks, allocating resources, or making decisions. The researchers wanted to create LLMs that could assist humans with these types of challenges.
To do this, they developed a training approach called ORLM that has several key features. First, it incorporates domain-specific knowledge, which means the LLM is trained on information relevant to the optimization problems it will be tackling. Second, it uses reinforcement learning, a technique where the model is rewarded for generating outputs that are closer to the optimal solution. And third, it introduces a new loss function, which is a way to measure how well the model's outputs align with the best possible answers.
The goal of this research is to create LLMs that can be genuinely useful for real-world optimization tasks, rather than just generating generic text. By training the models in this specialized way, the researchers hope to develop a powerful tool that can assist humans in making complex decisions and solving intricate problems.
Technical Explanation
The paper introduces ORLM, a new approach to training large language models (LLMs) for optimization modeling tasks. The key elements of the ORLM approach include:
-
Incorporating Domain-Specific Knowledge: The researchers incorporate domain-specific information into the training of the LLM, such as problem constraints, objective functions, and solution structures. This helps the model develop a deeper understanding of the optimization problems it will be tackling.
-
Leveraging Reinforcement Learning: The training process uses reinforcement learning, where the model is rewarded for generating outputs that are closer to the optimal solution. This helps the LLM learn to produce outputs that are well-aligned with the desired outcomes.
-
Introducing a Novel Loss Function: The researchers introduce a new loss function that is designed to better align the LLM's outputs with the optimal solutions to the optimization problems. This loss function captures both the semantic similarity between the model's outputs and the optimal solutions, as well as the structural and constraint-aware properties of the solutions.
Through these innovations, the ORLM approach aims to develop LLMs that can effectively assist humans with complex optimization tasks, such as scheduling, resource allocation, and decision-making. The researchers evaluate the performance of ORLM-trained LLMs on a range of optimization benchmarks and demonstrate significant improvements over standard LLM training approaches.
Critical Analysis
The paper presents a promising approach to training LLMs for optimization tasks, but it also acknowledges several caveats and areas for further research. One potential limitation is the reliance on domain-specific knowledge, which may make the ORLM approach less adaptable to new problem domains. Additionally, the researchers note that the reinforcement learning component of the training process can be computationally expensive and may require careful hyperparameter tuning.
Another area for further exploration is the evaluation of the ORLM-trained LLMs in more realistic, end-to-end optimization scenarios. The paper focuses on benchmark tasks, but it would be valuable to understand how these models perform when integrated into complete optimization workflows, where they may need to handle uncertainty, incomplete information, and interactive decision-making.
Finally, the paper does not directly address potential ethical concerns around the use of LLMs for optimization tasks, such as the potential for bias, fairness issues, or the implications of automating complex decision-making processes. As the research in this area progresses, it will be important to consider these broader societal implications.
Conclusion
The ORLM paper presents a novel approach to training large language models (LLMs) for optimization modeling tasks. By incorporating domain-specific knowledge, leveraging reinforcement learning, and introducing a specialized loss function, the researchers aim to develop LLMs that can effectively assist humans in solving complex optimization problems.
The technical innovations demonstrated in this work represent an important step towards creating more capable and trustworthy LLMs for real-world optimization challenges. As the field of optimization modeling continues to evolve, tools like ORLM-trained LLMs may become invaluable for supporting human decision-making and problem-solving in a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
When Large Language Model Meets Optimization
Sen Huang, Kaixiang Yang, Sheng Qi, Rui Wang
0
0
Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.
5/17/2024

Towards Optimizing with Large Language Models
Pei-Fu Guo, Ying-Hsuan Chen, Yun-Da Tsai, Shou-De Lin
0
0
In this work, we conduct an assessment of the optimization capabilities of LLMs across various tasks and data sizes. Each of these tasks corresponds to unique optimization domains, and LLMs are required to execute these tasks with interactive prompting. That is, in each optimization step, the LLM generates new solutions from the past generated solutions with their values, and then the new solutions are evaluated and considered in the next optimization step. Additionally, we introduce three distinct metrics for a comprehensive assessment of task performance from various perspectives. These metrics offer the advantage of being applicable for evaluating LLM performance across a broad spectrum of optimization tasks and are less sensitive to variations in test samples. By applying these metrics, we observe that LLMs exhibit strong optimization capabilities when dealing with small-sized samples. However, their performance is significantly influenced by factors like data size and values, underscoring the importance of further research in the domain of optimization tasks for LLMs.
5/28/2024
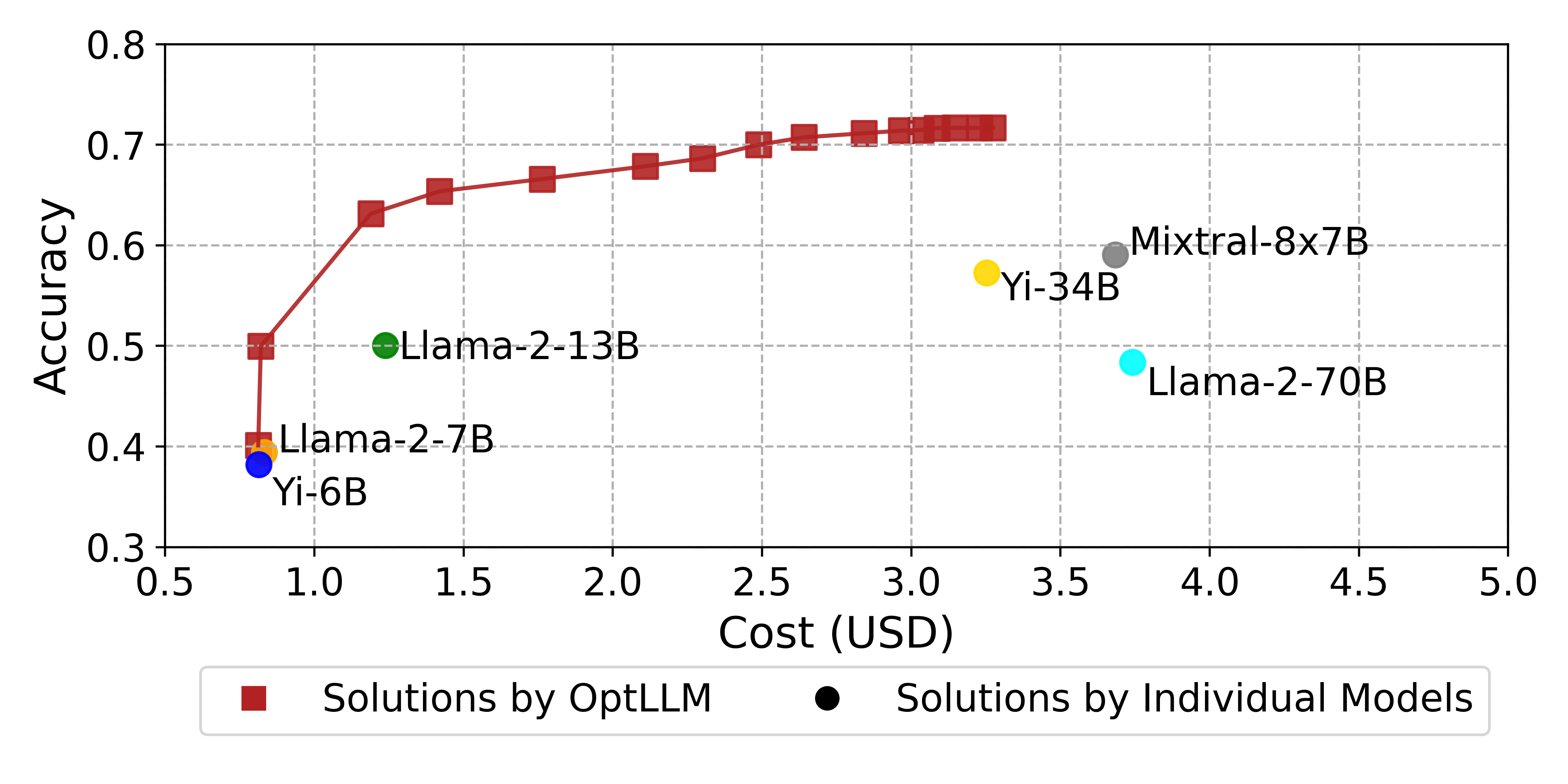
OptLLM: Optimal Assignment of Queries to Large Language Models
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
0
0
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
5/27/2024
⚙️
OpenLLM-Ro -- Technical Report on Open-source Romanian LLMs trained starting from Llama 2
Mihai Masala, Denis C. Ilie-Ablachim, Dragos Corlatescu, Miruna Zavelca, Marius Leordeanu, Horia Velicu, Marius Popescu, Mihai Dascalu, Traian Rebedea
0
0
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English. Hence, their performance in English greatly exceeds their performance in other languages. This document presents our approach to training and evaluating the first foundational and chat LLM specialized for Romanian.
5/20/2024