Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs
2405.20835
0
0
Abstract
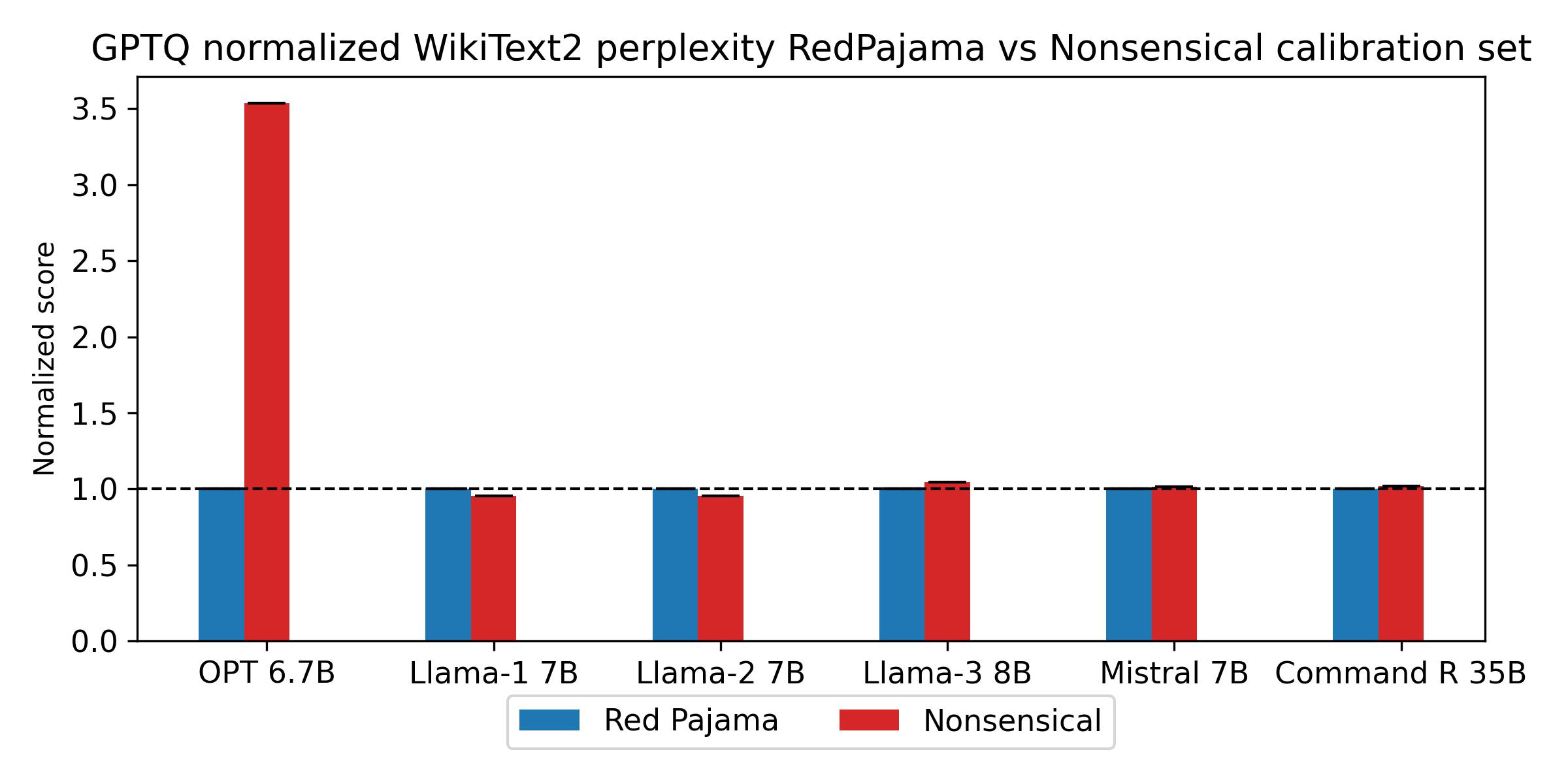
Post-Training Quantization (PTQ) enhances the efficiency of Large Language Models (LLMs) by enabling faster operation and compatibility with more accessible hardware through reduced memory usage, at the cost of small performance drops. We explore the role of calibration sets in PTQ, specifically their effect on hidden activations in various notable open-source LLMs. Calibration sets are crucial for evaluating activation magnitudes and identifying outliers, which can distort the quantization range and negatively impact performance. Our analysis reveals a marked contrast in quantization effectiveness across models. The older OPT model, upon which much of the quantization literature is based, shows significant performance deterioration and high susceptibility to outliers with varying calibration sets. In contrast, newer models like Llama-2 7B, Llama-3 8B, Command-R 35B, and Mistral 7B demonstrate strong robustness, with Mistral 7B showing near-immunity to outliers and stable activations. These findings suggest a shift in PTQ strategies might be needed. As advancements in pre-training methods reduce the relevance of outliers, there is an emerging need to reassess the fundamentals of current quantization literature. The emphasis should pivot towards optimizing inference speed, rather than primarily focusing on outlier preservation, to align with the evolving characteristics of state-of-the-art LLMs.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Quantized Large Language Models
Shiyao Li, Xuefei Ning, Luning Wang, Tengxuan Liu, Xiangsheng Shi, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
0
0
Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions. The code can be found in https://github.com/thu-nics/qllm-eval.
6/7/2024
🏋️
AdpQ: A Zero-shot Calibration Free Adaptive Post Training Quantization Method for LLMs
Alireza Ghaffari, Sharareh Younesian, Vahid Partovi Nia, Boxing Chen, Masoud Asgharian
0
0
The ever-growing computational complexity of Large Language Models (LLMs) necessitates efficient deployment strategies. The current state-of-the-art approaches for Post-training Quantization (PTQ) often require calibration to achieve the desired accuracy. This paper presents AdpQ, a novel zero-shot adaptive PTQ method for LLMs that achieves the state-of-the-art performance in low-precision quantization (e.g. 3-bit) without requiring any calibration data. Inspired by Adaptive LASSO regression model, our proposed approach tackles the challenge of outlier activations by separating salient weights using an adaptive soft-thresholding method. Guided by Adaptive LASSO, this method ensures that the quantized weights distribution closely follows the originally trained weights and eliminates the need for calibration data entirely, setting our method apart from popular approaches such as SpQR and AWQ. Furthermore, our method offers an additional benefit in terms of privacy preservation by eliminating any calibration or training data. We also delve deeper into the information-theoretic underpinnings of the proposed method. We demonstrate that it leverages the Adaptive LASSO to minimize the Kullback-Leibler divergence between the quantized weights and the originally trained weights. This minimization ensures the quantized model retains the Shannon information content of the original model to a great extent, guaranteeing efficient deployment without sacrificing accuracy or information. Our results achieve the same accuracy as the existing methods on various LLM benchmarks while the quantization time is reduced by at least 10x, solidifying our contribution to efficient and privacy-preserving LLM deployment.
5/24/2024
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Yunchen Zhang, Xianglong Liu, Dacheng Tao
0
0
Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
5/13/2024