Pathological Primitive Segmentation Based on Visual Foundation Model with Zero-Shot Mask Generation
2404.08584
0
0

Abstract
Medical image processing usually requires a model trained with carefully crafted datasets due to unique image characteristics and domain-specific challenges, especially in pathology. Primitive detection and segmentation in digitized tissue samples are essential for objective and automated diagnosis and prognosis of cancer. SAM (Segment Anything Model) has recently been developed to segment general objects from natural images with high accuracy, but it requires human prompts to generate masks. In this work, we present a novel approach that adapts pre-trained natural image encoders of SAM for detection-based region proposals. Regions proposed by a pre-trained encoder are sent to cascaded feature propagation layers for projection. Then, local semantic and global context is aggregated from multi-scale for bounding box localization and classification. Finally, the SAM decoder uses the identified bounding boxes as essential prompts to generate a comprehensive primitive segmentation map. The entire base framework, SAM, requires no additional training or fine-tuning but could produce an end-to-end result for two fundamental segmentation tasks in pathology. Our method compares with state-of-the-art models in F1 score for nuclei detection and binary/multiclass panoptic(bPQ/mPQ) and mask quality(dice) for segmentation quality on the PanNuke dataset while offering end-to-end efficiency. Our model also achieves remarkable Average Precision (+4.5%) on the secondary dataset (HuBMAP Kidney) compared to Faster RCNN. The code is publicly available at https://github.com/learner-codec/autoprom_sam.
Create account to get full access
Overview
- This paper proposes a novel approach for pathological primitive segmentation using a visual foundation model with zero-shot mask generation.
- The method leverages the capabilities of a pre-trained visual foundation model to perform segmentation on pathological images without the need for task-specific training.
- The key innovation is a zero-shot mask generation technique that allows the model to produce segmentation masks for unseen pathological primitives.
Plain English Explanation
The researchers have developed a new way to automatically identify and outline different structures or "primitives" in medical images, even if those structures have never been seen before. This is important because medical images can contain a wide variety of complex and unusual features, and it's challenging for existing AI models to accurately segment all of them.
The researchers' approach uses a powerful "foundation" AI model that has been trained on a massive amount of general visual data. This foundation model is then adapted to work on medical images without requiring any additional training on specific pathological features. A key part of the method is the "zero-shot" mask generation, which allows the model to produce accurate segmentation outlines for new types of structures that it has never encountered before.
By leveraging the general visual understanding of the foundation model and combining it with this zero-shot capability, the researchers have developed a versatile system that can handle the diverse range of features found in medical images. This could be very helpful for tasks like disease diagnosis, treatment planning, and monitoring disease progression, where being able to precisely identify different anatomical structures is crucial.
Technical Explanation
The paper introduces a [object Object] method that builds upon the [object Object] and [object Object] architectures. The key innovation is a zero-shot mask generation technique that allows the model to produce segmentation masks for unseen pathological primitives.
The approach first fine-tunes the SAM model on a dataset of pathological images. It then introduces a Pathological Primitive Segmentation Head that takes the SAM features and generates segmentation masks in a zero-shot manner. This leverages the powerful visual understanding of the pre-trained SAM model to perform segmentation without the need for additional task-specific training.
The authors also explore [object Object] techniques to [object Object], further improving the model's performance on unseen pathological primitives.
Critical Analysis
The paper presents a compelling approach that addresses an important challenge in medical image analysis - the ability to accurately segment a wide range of pathological primitives without the need for extensive task-specific training. The zero-shot mask generation is a particularly novel and promising aspect of the work.
However, the paper does not provide detailed analysis of the limitations or potential failure modes of the proposed method. It would be helpful to understand the types of pathological primitives that the model struggles with, as well as the impact of factors like image quality, modality, and anatomical complexity on the segmentation performance.
Additionally, the authors could have delved deeper into the potential clinical applications and real-world implications of their work. While the technical contributions are significant, a more thorough discussion of how this technology could benefit medical practitioners and patients would strengthen the paper.
Conclusion
This paper introduces a novel Pathological Primitive Segmentation method that leverages a visual foundation model and zero-shot mask generation to enable accurate segmentation of diverse pathological features in medical images. By adapting the powerful Segment Anything Model and introducing a specialized segmentation head, the researchers have developed a versatile system that can handle a wide range of unseen pathological primitives.
The zero-shot mask generation capability is a particularly notable contribution, as it addresses a key challenge in medical image analysis. If further developed and validated, this technology could have significant implications for disease diagnosis, treatment planning, and monitoring, by providing clinicians with detailed and accurate segmentations of relevant anatomical structures and pathological features.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Zero-Shot Segmentation of Eye Features Using the Segment Anything Model (SAM)
Virmarie Maquiling, Sean Anthony Byrne, Diederick C. Niehorster, Marcus Nystrom, Enkelejda Kasneci
0
0
The advent of foundation models signals a new era in artificial intelligence. The Segment Anything Model (SAM) is the first foundation model for image segmentation. In this study, we evaluate SAM's ability to segment features from eye images recorded in virtual reality setups. The increasing requirement for annotated eye-image datasets presents a significant opportunity for SAM to redefine the landscape of data annotation in gaze estimation. Our investigation centers on SAM's zero-shot learning abilities and the effectiveness of prompts like bounding boxes or point clicks. Our results are consistent with studies in other domains, demonstrating that SAM's segmentation effectiveness can be on-par with specialized models depending on the feature, with prompts improving its performance, evidenced by an IoU of 93.34% for pupil segmentation in one dataset. Foundation models like SAM could revolutionize gaze estimation by enabling quick and easy image segmentation, reducing reliance on specialized models and extensive manual annotation.
4/9/2024

Boosting Medical Image Classification with Segmentation Foundation Model
Pengfei Gu, Zihan Zhao, Hongxiao Wang, Yaopeng Peng, Yizhe Zhang, Nishchal Sapkota, Chaoli Wang, Danny Z. Chen
0
0
The Segment Anything Model (SAM) exhibits impressive capabilities in zero-shot segmentation for natural images. Recently, SAM has gained a great deal of attention for its applications in medical image segmentation. However, to our best knowledge, no studies have shown how to harness the power of SAM for medical image classification. To fill this gap and make SAM a true ``foundation model'' for medical image analysis, it is highly desirable to customize SAM specifically for medical image classification. In this paper, we introduce SAMAug-C, an innovative augmentation method based on SAM for augmenting classification datasets by generating variants of the original images. The augmented datasets can be used to train a deep learning classification model, thereby boosting the classification performance. Furthermore, we propose a novel framework that simultaneously processes raw and SAMAug-C augmented image input, capitalizing on the complementary information that is offered by both. Experiments on three public datasets validate the effectiveness of our new approach.
6/18/2024
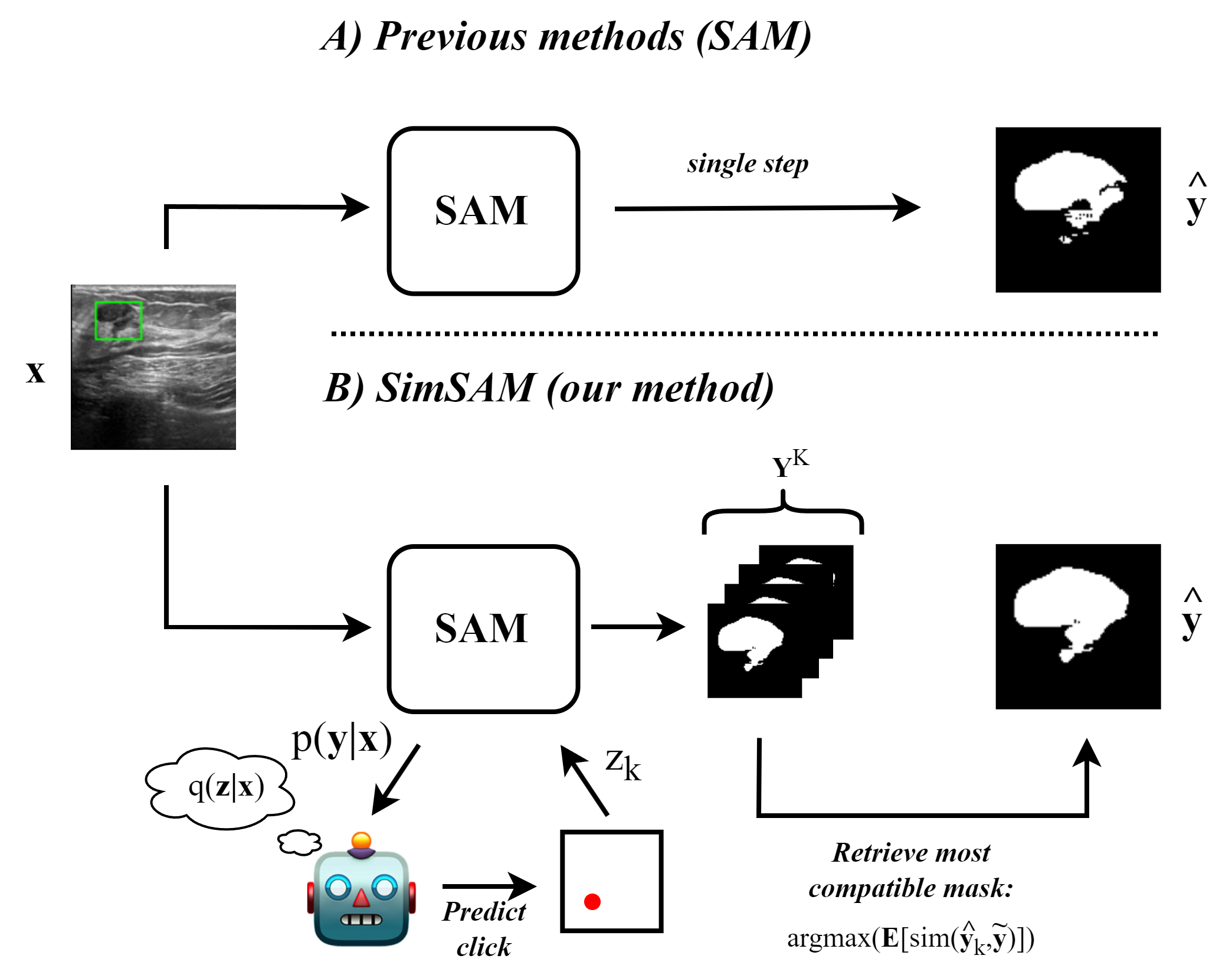
SimSAM: Zero-shot Medical Image Segmentation via Simulated Interaction
Benjamin Towle, Xin Chen, Ke Zhou
0
0
The recently released Segment Anything Model (SAM) has shown powerful zero-shot segmentation capabilities through a semi-automatic annotation setup in which the user can provide a prompt in the form of clicks or bounding boxes. There is growing interest around applying this to medical imaging, where the cost of obtaining expert annotations is high, privacy restrictions may limit sharing of patient data, and model generalisation is often poor. However, there are large amounts of inherent uncertainty in medical images, due to unclear object boundaries, low-contrast media, and differences in expert labelling style. Currently, SAM is known to struggle in a zero-shot setting to adequately annotate the contours of the structure of interest in medical images, where the uncertainty is often greatest, thus requiring significant manual correction. To mitigate this, we introduce textbf{Sim}ulated Interaction for textbf{S}egment textbf{A}nything textbf{M}odel (textsc{textbf{SimSAM}}), an approach that leverages simulated user interaction to generate an arbitrary number of candidate masks, and uses a novel aggregation approach to output the most compatible mask. Crucially, our method can be used during inference directly on top of SAM, without any additional training requirement. Quantitatively, we evaluate our method across three publicly available medical imaging datasets, and find that our approach leads to up to a 15.5% improvement in contour segmentation accuracy compared to zero-shot SAM. Our code is available at url{https://github.com/BenjaminTowle/SimSAM}.
6/4/2024
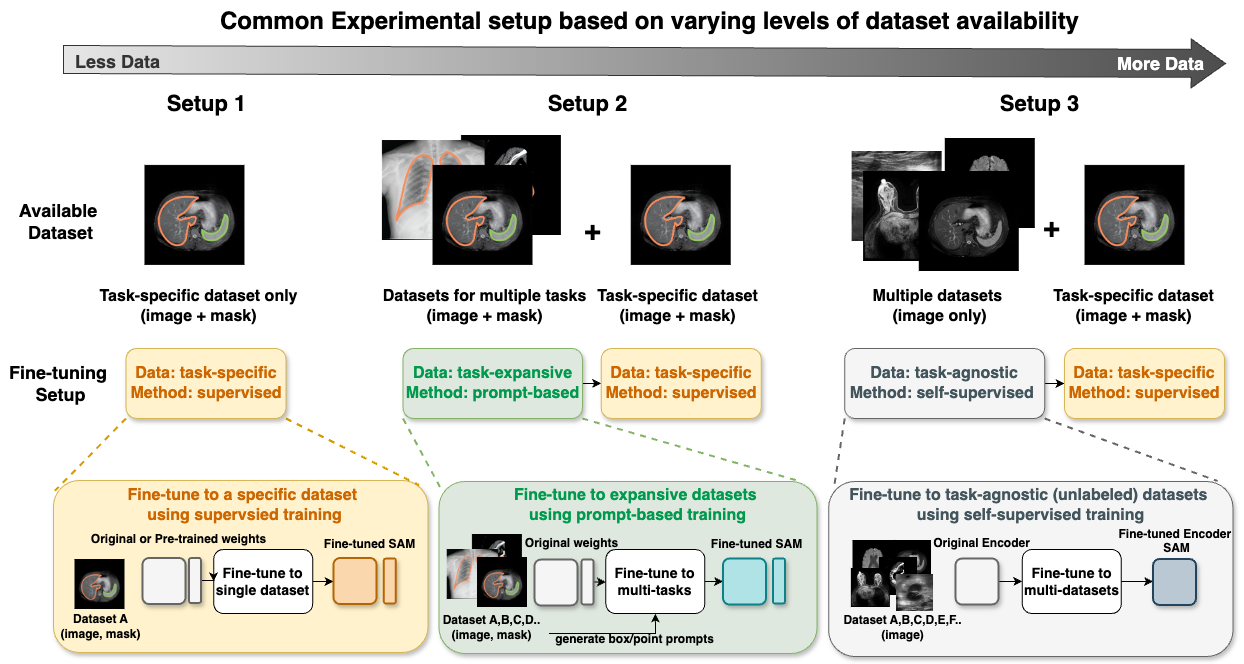
How to build the best medical image segmentation algorithm using foundation models: a comprehensive empirical study with Segment Anything Model
Hanxue Gu, Haoyu Dong, Jichen Yang, Maciej A. Mazurowski
0
0
Automated segmentation is a fundamental medical image analysis task, which enjoys significant advances due to the advent of deep learning. While foundation models have been useful in natural language processing and some vision tasks for some time, the foundation model developed with image segmentation in mind - Segment Anything Model (SAM) - has been developed only recently and has shown similar promise. However, there are still no systematic analyses or best-practice guidelines for optimal fine-tuning of SAM for medical image segmentation. This work summarizes existing fine-tuning strategies with various backbone architectures, model components, and fine-tuning algorithms across 18 combinations, and evaluates them on 17 datasets covering all common radiology modalities. Our study reveals that (1) fine-tuning SAM leads to slightly better performance than previous segmentation methods, (2) fine-tuning strategies that use parameter-efficient learning in both the encoder and decoder are superior to other strategies, (3) network architecture has a small impact on final performance, (4) further training SAM with self-supervised learning can improve final model performance. We also demonstrate the ineffectiveness of some methods popular in the literature and further expand our experiments into few-shot and prompt-based settings. Lastly, we released our code and MRI-specific fine-tuned weights, which consistently obtained superior performance over the original SAM, at https://github.com/mazurowski-lab/finetune-SAM.
5/14/2024