Perturbing the Gradient for Alleviating Meta Overfitting
2405.12299
0
0
👁️
Abstract
The reason for Meta Overfitting can be attributed to two factors: Mutual Non-exclusivity and the Lack of diversity, consequent to which a single global function can fit the support set data of all the meta-training tasks and fail to generalize to new unseen tasks. This issue is evidenced by low error rates on the meta-training tasks, but high error rates on new tasks. However, there can be a number of novel solutions to this problem keeping in mind any of the two objectives to be attained, i.e. to increase diversity in the tasks and to reduce the confidence of the model for some of the tasks. In light of the above, this paper proposes a number of solutions to tackle meta-overfitting on few-shot learning settings, such as few-shot sinusoid regression and few shot classification. Our proposed approaches demonstrate improved generalization performance compared to state-of-the-art baselines for learning in a non-mutually exclusive task setting. Overall, this paper aims to provide insights into tackling overfitting in meta-learning and to advance the field towards more robust and generalizable models.
Create account to get full access
Overview
- Meta-overfitting is a problem in few-shot learning settings where a model can fit the training data well but fail to generalize to new tasks
- This issue is caused by two factors: mutual non-exclusivity and lack of diversity in the training tasks
- The paper proposes several solutions to address meta-overfitting, focusing on increasing task diversity and reducing model confidence for certain tasks
Plain English Explanation
In few-shot learning, models are trained on a variety of related tasks and then expected to apply what they've learned to new, unseen tasks. However, the paper explains that this can lead to a problem called "meta-overfitting." The model may do very well on the training tasks, but then perform poorly when faced with new tasks.
This happens for two main reasons. First, the training tasks may not be mutually exclusive - a single global function can fit the data from all the training tasks. Second, there may be a lack of diversity in the training tasks, meaning the model doesn't learn a broad enough set of skills.
To address this, the paper proposes several novel solutions. Some focus on increasing the diversity of the training tasks, so the model has to learn a wider range of capabilities. Others aim to reduce the model's confidence in its performance on certain tasks, preventing it from overfitting to the training data.
The key idea is to find ways to train models that are more robust and can generalize better to new, unseen tasks. This is an important challenge in the field of meta-learning, where the goal is to develop AI systems that can quickly adapt to new problems by building on previous experience.
Technical Explanation
The paper identifies two primary causes of meta-overfitting in few-shot learning:
-
Mutual Non-exclusivity: The training tasks may not be mutually exclusive, meaning a single global function can fit the support set data of all the meta-training tasks. This leads to the model failing to generalize to new, unseen tasks.
-
Lack of Diversity: The set of meta-training tasks may lack diversity, again resulting in the model learning a function that fits the training data well but does not generalize.
To address these issues, the paper proposes several novel solutions, focusing on two key objectives:
-
Increasing Task Diversity: Approaches that aim to increase the diversity of the meta-training tasks, such that the model is forced to learn a broader range of capabilities.
-
Reducing Model Confidence: Techniques that reduce the model's confidence in its performance on certain tasks, preventing it from overfitting to the training data.
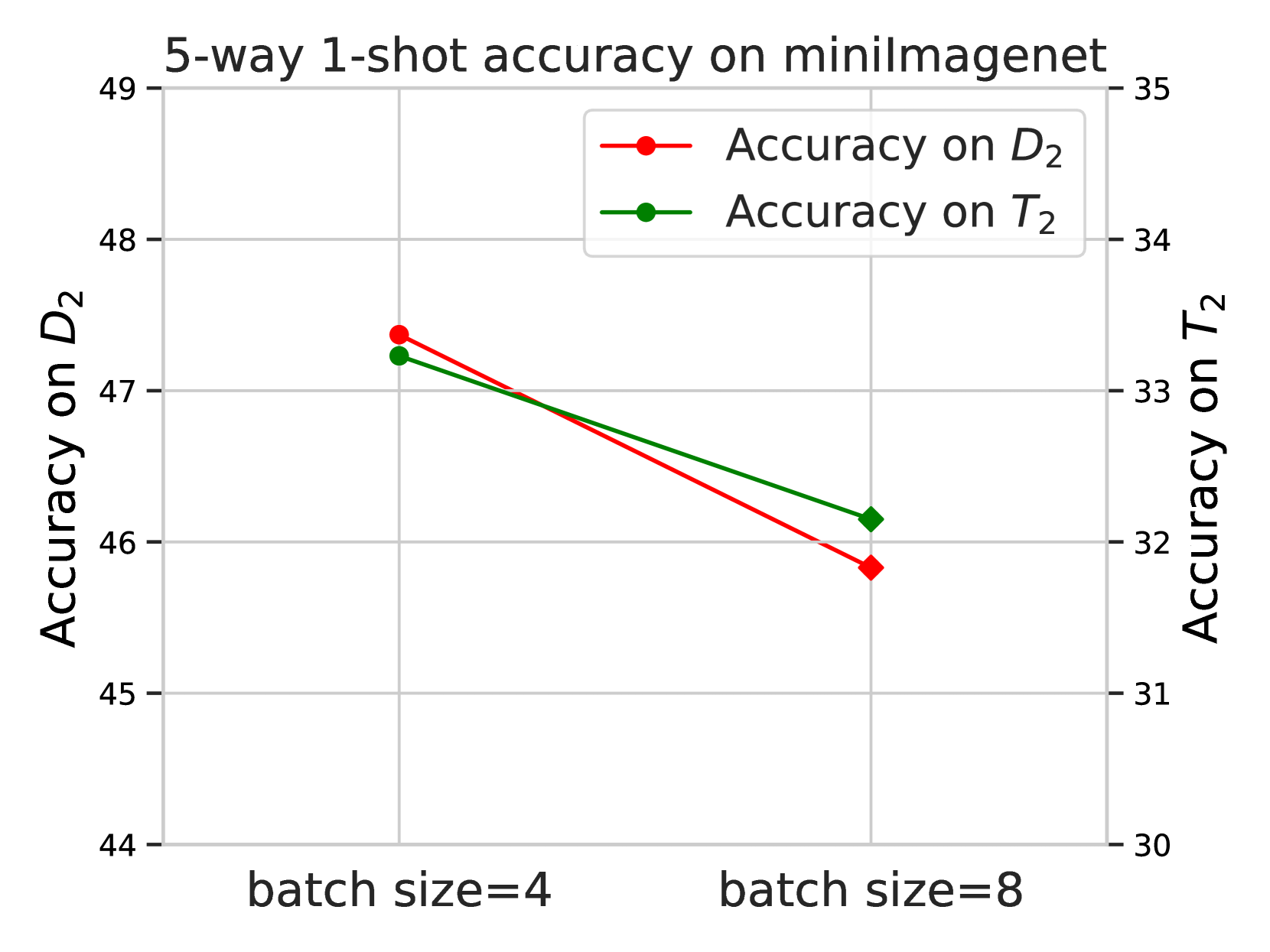
The paper evaluates these proposed solutions on few-shot learning benchmarks, such as few-shot sinusoid regression and few-shot classification. The results demonstrate improved generalization performance compared to state-of-the-art baselines, particularly in settings where the meta-training tasks are not mutually exclusive.
Critical Analysis
The paper provides valuable insights into the problem of meta-overfitting and proposes promising solutions. However, some potential limitations and areas for further research are worth considering:
- The paper focuses on two specific causes of meta-overfitting (mutual non-exclusivity and lack of diversity), but there may be other factors that contribute to the problem that are not addressed.
- The proposed solutions, while effective, may have their own limitations or trade-offs that are not fully explored. For example, increasing task diversity could come at the cost of computational efficiency or task similarity.
- The paper evaluates the solutions on a limited set of benchmarks, and it would be interesting to see how they perform on a wider range of few-shot learning tasks and domains, including real-world applications.
- Further research could explore the theoretical underpinnings of meta-overfitting and the generalization properties of meta-learning algorithms more broadly, as discussed in related work.
Overall, the paper presents valuable contributions to the field of meta-learning and highlights the importance of addressing meta-overfitting for developing more robust and generalizable AI systems.
Conclusion
This paper tackles the critical problem of meta-overfitting in few-shot learning settings, where models can excel on training tasks but struggle to generalize to new, unseen tasks. The proposed solutions focus on increasing the diversity of the training tasks and reducing the model's confidence in certain tasks, demonstrating improved generalization performance.
By addressing meta-overfitting, the research advances the field of meta-learning towards more robust and adaptable AI systems that can quickly learn and apply new skills. This is a crucial step in the development of versatile and capable AI agents that can thrive in complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Meta-Learning Loss Functions for Deep Neural Networks
Christian Raymond
0
0
Humans can often quickly and efficiently solve complex new learning tasks given only a small set of examples. In contrast, modern artificially intelligent systems often require thousands or millions of observations in order to solve even the most basic tasks. Meta-learning aims to resolve this issue by leveraging past experiences from similar learning tasks to embed the appropriate inductive biases into the learning system. Historically methods for meta-learning components such as optimizers, parameter initializations, and more have led to significant performance increases. This thesis aims to explore the concept of meta-learning to improve performance, through the often-overlooked component of the loss function. The loss function is a vital component of a learning system, as it represents the primary learning objective, where success is determined and quantified by the system's ability to optimize for that objective successfully.
7/2/2024

Domain Generalization through Meta-Learning: A Survey
Arsham Gholamzadeh Khoee, Yinan Yu, Robert Feldt
0
0
Deep neural networks (DNNs) have revolutionized artificial intelligence but often lack performance when faced with out-of-distribution (OOD) data, a common scenario due to the inevitable domain shifts in real-world applications. This limitation stems from the common assumption that training and testing data share the same distribution-an assumption frequently violated in practice. Despite their effectiveness with large amounts of data and computational power, DNNs struggle with distributional shifts and limited labeled data, leading to overfitting and poor generalization across various tasks and domains. Meta-learning presents a promising approach by employing algorithms that acquire transferable knowledge across various tasks for fast adaptation, eliminating the need to learn each task from scratch. This survey paper delves into the realm of meta-learning with a focus on its contribution to domain generalization. We first clarify the concept of meta-learning for domain generalization and introduce a novel taxonomy based on the feature extraction strategy and the classifier learning methodology, offering a granular view of methodologies. Through an exhaustive review of existing methods and underlying theories, we map out the fundamentals of the field. Our survey provides practical insights and an informed discussion on promising research directions, paving the way for future innovation in meta-learning for domain generalization.
4/4/2024
Hacking Task Confounder in Meta-Learning
Jingyao Wang, Yi Ren, Zeen Song, Jianqi Zhang, Changwen Zheng, Wenwen Qiang
0
0
Meta-learning enables rapid generalization to new tasks by learning knowledge from various tasks. It is intuitively assumed that as the training progresses, a model will acquire richer knowledge, leading to better generalization performance. However, our experiments reveal an unexpected result: there is negative knowledge transfer between tasks, affecting generalization performance. To explain this phenomenon, we conduct Structural Causal Models (SCMs) for causal analysis. Our investigation uncovers the presence of spurious correlations between task-specific causal factors and labels in meta-learning. Furthermore, the confounding factors differ across different batches. We refer to these confounding factors as Task Confounders. Based on these findings, we propose a plug-and-play Meta-learning Causal Representation Learner (MetaCRL) to eliminate task confounders. It encodes decoupled generating factors from multiple tasks and utilizes an invariant-based bi-level optimization mechanism to ensure their causality for meta-learning. Extensive experiments on various benchmark datasets demonstrate that our work achieves state-of-the-art (SOTA) performance.
5/30/2024

Meta-Learning Neural Procedural Biases
Christian Raymond, Qi Chen, Bing Xue, Mengjie Zhan
0
0
The goal of few-shot learning is to generalize and achieve high performance on new unseen learning tasks, where each task has only a limited number of examples available. Gradient-based meta-learning attempts to address this challenging task by learning how to learn new tasks by embedding inductive biases informed by prior learning experiences into the components of the learning algorithm. In this work, we build upon prior research and propose Neural Procedural Bias Meta-Learning (NPBML), a novel framework designed to meta-learn task-adaptive procedural biases. Our approach aims to consolidate recent advancements in meta-learned initializations, optimizers, and loss functions by learning them simultaneously and making them adapt to each individual task to maximize the strength of the learned inductive biases. This imbues each learning task with a unique set of procedural biases which is specifically designed and selected to attain strong learning performance in only a few gradient steps. The experimental results show that by meta-learning the procedural biases of a neural network, we can induce strong inductive biases towards a distribution of learning tasks, enabling robust learning performance across many well-established few-shot learning benchmarks.
6/13/2024