Predictive Uncertainty Quantification via Risk Decompositions for Strictly Proper Scoring Rules
2402.10727
0
0
👀
Abstract
Uncertainty quantification in predictive modeling often relies on ad hoc methods as there is no universally accepted formal framework for that. This paper introduces a theoretical approach to understanding uncertainty through statistical risks, distinguishing between aleatoric (data-related) and epistemic (model-related) uncertainties. We explain how to split pointwise risk into Bayes risk and excess risk. In particular, we show that excess risk, related to epistemic uncertainty, aligns with Bregman divergences. To turn considered risk measures into actual uncertainty estimates, we suggest using the Bayesian approach by approximating the risks with the help of posterior distributions. We tested our method on image datasets, evaluating its performance in detecting out-of-distribution and misclassified data using the AUROC metric. Our results confirm the effectiveness of the considered approach and offer practical guidance for estimating uncertainty in real-world applications.
Create account to get full access
Overview
- Introduces a theoretical approach to understanding uncertainty in predictive modeling by distinguishing between aleatoric (data-related) and epistemic (model-related) uncertainties.
- Explains how to split pointwise risk into Bayes risk and excess risk, where excess risk aligns with Bregman divergences and is related to epistemic uncertainty.
- Suggests using the Bayesian approach to turn risk measures into actual uncertainty estimates by approximating the risks with the help of posterior distributions.
- Evaluates the method's performance in detecting out-of-distribution and misclassified data on image datasets using the AUROC metric.
Plain English Explanation
When building predictive models, it's important to understand the different types of uncertainty that can arise. This paper proposes a new way to think about uncertainty by splitting it into two categories:
- Aleatoric uncertainty: This is the uncertainty that comes from the data itself, like noise or variability in the measurements.
- Epistemic uncertainty: This is the uncertainty that comes from the model, like how well it's able to capture the underlying patterns in the data.
The researchers show that the "excess risk" (the extra risk beyond the best possible model) is related to the epistemic uncertainty, and they can use this to estimate the different types of uncertainty. To do this, they use a Bayesian approach, which means they look at the probability distributions of the model's outputs.
The researchers tested their method on image datasets and found that it was effective at detecting when the model was making mistakes or seeing data that was very different from what it was trained on. This could be useful in real-world applications where you want to know when to trust your model's predictions and when to be more cautious.
Technical Explanation
The paper introduces a theoretical framework for understanding uncertainty in predictive modeling. It distinguishes between aleatoric uncertainty, which is related to the inherent variability in the data, and epistemic uncertainty, which is related to limitations in the model's ability to capture the underlying patterns.
The key idea is to split the overall pointwise risk into two components: Bayes risk, which is the lowest possible risk given the true underlying distribution, and excess risk, which is the additional risk due to epistemic uncertainty. The researchers show that this excess risk is closely related to Bregman divergences, a family of distance metrics that can be used to measure the difference between probability distributions.
To turn these risk measures into actual uncertainty estimates, the paper suggests using a Bayesian approach. By approximating the risks using the posterior distributions of the model's outputs, the researchers can quantify both the aleatoric and epistemic uncertainties associated with the model's predictions.
The proposed method was evaluated on image classification tasks, where it demonstrated the ability to detect out-of-distribution and misclassified data using the AUROC metric. These results suggest that the framework can provide practical guidance for estimating uncertainty in real-world applications of predictive modeling.
Critical Analysis
The paper presents a promising theoretical approach to understanding and quantifying uncertainty in predictive modeling, but there are a few potential limitations and areas for further research:
-
Computational Complexity: The Bayesian approach used to approximate the risk measures may be computationally intensive, especially for large-scale models. Exploring more efficient approximation techniques could improve the practical applicability of the method.
-
Sensitivity to Priors: The Bayesian framework relies on the choice of prior distributions, which can have a significant impact on the resulting uncertainty estimates. Further investigation is needed to understand the sensitivity of the method to different prior choices.
-
Generalization to Other Domains: The evaluation in the paper was limited to image classification tasks. Assessing the method's performance on a wider range of predictive modeling problems, such as time series forecasting or natural language processing, would help demonstrate its broader applicability.
-
Interpretability of Uncertainty Estimates: While the paper provides a theoretical foundation for understanding uncertainty, the practical interpretation of the aleatoric and epistemic uncertainty estimates could be challenging for domain experts. Developing more intuitive visualizations or explanations of the uncertainty measures could enhance their usefulness in real-world applications.
Overall, the paper introduces an innovative approach to quantifying uncertainty in predictive models and offers a solid theoretical framework for further research and development in this area.
Conclusion
This paper presents a novel theoretical approach to understanding and quantifying uncertainty in predictive modeling. By distinguishing between aleatoric (data-related) and epistemic (model-related) uncertainties, the researchers introduce a framework for splitting pointwise risk into Bayes risk and excess risk, where the latter is closely related to Bregman divergences and epistemic uncertainty.
The proposed method, which uses a Bayesian approach to approximate the risks with posterior distributions, has been shown to be effective in detecting out-of-distribution and misclassified data on image datasets. This suggests that the framework can provide practical guidance for estimating uncertainty in real-world applications of predictive modeling, potentially leading to more robust and trustworthy AI systems.
While the paper offers a solid theoretical foundation, further research is needed to address potential limitations, such as computational complexity, sensitivity to priors, and interpretability of the uncertainty estimates. Exploring these areas could help unlock the full potential of this approach and advance the field of uncertainty quantification in predictive modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
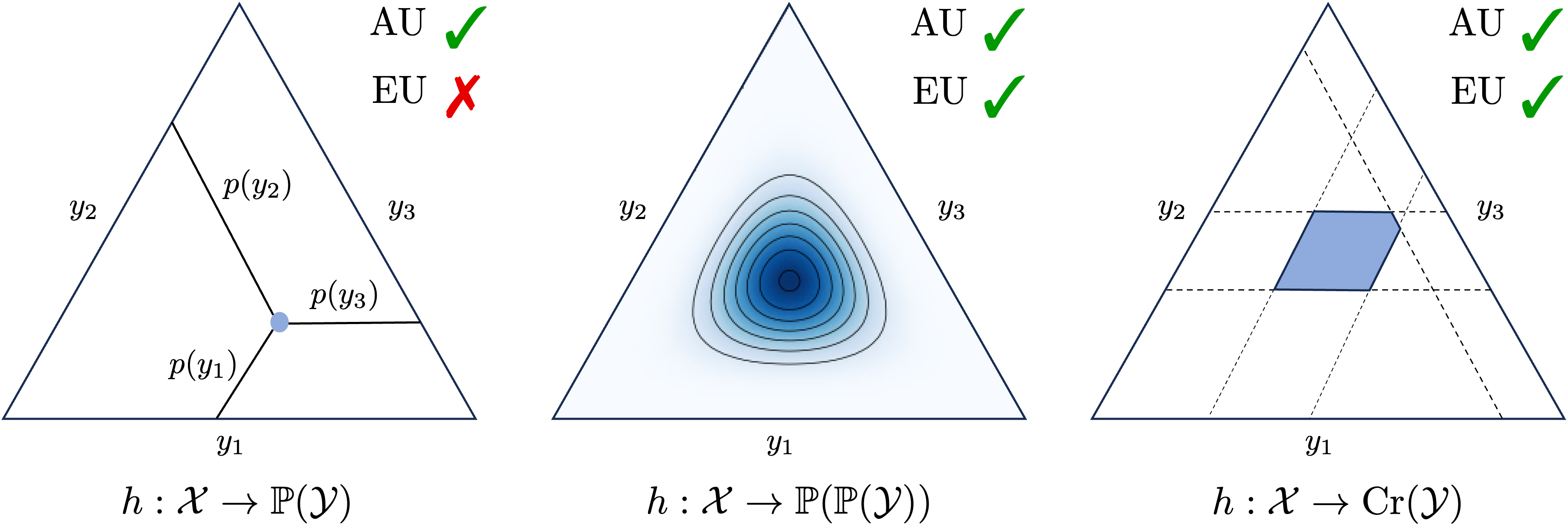
Quantifying Aleatoric and Epistemic Uncertainty with Proper Scoring Rules
Paul Hofman, Yusuf Sale, Eyke Hullermeier
0
0
Uncertainty representation and quantification are paramount in machine learning and constitute an important prerequisite for safety-critical applications. In this paper, we propose novel measures for the quantification of aleatoric and epistemic uncertainty based on proper scoring rules, which are loss functions with the meaningful property that they incentivize the learner to predict ground-truth (conditional) probabilities. We assume two common representations of (epistemic) uncertainty, namely, in terms of a credal set, i.e. a set of probability distributions, or a second-order distribution, i.e., a distribution over probability distributions. Our framework establishes a natural bridge between these representations. We provide a formal justification of our approach and introduce new measures of epistemic and aleatoric uncertainty as concrete instantiations.
4/22/2024

Label-wise Aleatoric and Epistemic Uncertainty Quantification
Yusuf Sale, Paul Hofman, Timo Lohr, Lisa Wimmer, Thomas Nagler, Eyke Hullermeier
0
0
We present a novel approach to uncertainty quantification in classification tasks based on label-wise decomposition of uncertainty measures. This label-wise perspective allows uncertainty to be quantified at the individual class level, thereby improving cost-sensitive decision-making and helping understand the sources of uncertainty. Furthermore, it allows to define total, aleatoric, and epistemic uncertainty on the basis of non-categorical measures such as variance, going beyond common entropy-based measures. In particular, variance-based measures address some of the limitations associated with established methods that have recently been discussed in the literature. We show that our proposed measures adhere to a number of desirable properties. Through empirical evaluation on a variety of benchmark data sets -- including applications in the medical domain where accurate uncertainty quantification is crucial -- we establish the effectiveness of label-wise uncertainty quantification.
6/5/2024
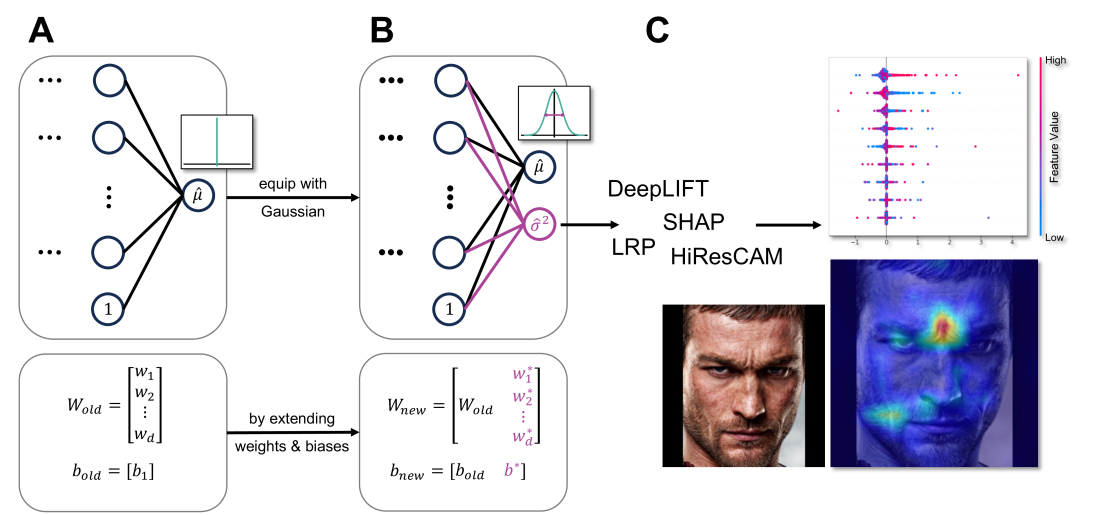
Identifying Drivers of Predictive Aleatoric Uncertainty
Pascal Iversen, Simon Witzke, Katharina Baum, Bernhard Y. Renard
0
0
Explainability and uncertainty quantification are two pillars of trustable artificial intelligence. However, the reasoning behind uncertainty estimates is generally left unexplained. Identifying the drivers of uncertainty complements explanations of point predictions in recognizing model limitations and enhances trust in decisions and their communication. So far, explanations of uncertainties have been rarely studied. The few exceptions rely on Bayesian neural networks or technically intricate approaches, such as auxiliary generative models, thereby hindering their broad adoption. We present a simple approach to explain predictive aleatoric uncertainties. We estimate uncertainty as predictive variance by adapting a neural network with a Gaussian output distribution. Subsequently, we apply out-of-the-box explainers to the model's variance output. This approach can explain uncertainty influences more reliably than literature baselines, which we evaluate in a synthetic setting with a known data-generating process. We further adapt multiple metrics from conventional XAI research to uncertainty explanations. We quantify our findings with a nuanced benchmark analysis that includes real-world datasets. Finally, we apply our approach to an age regression model and discover reasonable sources of uncertainty. Overall, we explain uncertainty estimates with little modifications to the model architecture and demonstrate that our approach competes effectively with more intricate methods.
5/31/2024
👨🏫
Score-based generative models are provably robust: an uncertainty quantification perspective
Nikiforos Mimikos-Stamatopoulos, Benjamin J. Zhang, Markos A. Katsoulakis
0
0
Through an uncertainty quantification (UQ) perspective, we show that score-based generative models (SGMs) are provably robust to the multiple sources of error in practical implementation. Our primary tool is the Wasserstein uncertainty propagation (WUP) theorem, a model-form UQ bound that describes how the $L^2$ error from learning the score function propagates to a Wasserstein-1 ($mathbf{d}_1$) ball around the true data distribution under the evolution of the Fokker-Planck equation. We show how errors due to (a) finite sample approximation, (b) early stopping, (c) score-matching objective choice, (d) score function parametrization expressiveness, and (e) reference distribution choice, impact the quality of the generative model in terms of a $mathbf{d}_1$ bound of computable quantities. The WUP theorem relies on Bernstein estimates for Hamilton-Jacobi-Bellman partial differential equations (PDE) and the regularizing properties of diffusion processes. Specifically, PDE regularity theory shows that stochasticity is the key mechanism ensuring SGM algorithms are provably robust. The WUP theorem applies to integral probability metrics beyond $mathbf{d}_1$, such as the total variation distance and the maximum mean discrepancy. Sample complexity and generalization bounds in $mathbf{d}_1$ follow directly from the WUP theorem. Our approach requires minimal assumptions, is agnostic to the manifold hypothesis and avoids absolute continuity assumptions for the target distribution. Additionally, our results clarify the trade-offs among multiple error sources in SGMs.
5/27/2024