PTQ4ViT: Post-training quantization for vision transformers with twin uniform quantization
2111.12293
0
0
👀
Abstract
Quantization is one of the most effective methods to compress neural networks, which has achieved great success on convolutional neural networks (CNNs). Recently, vision transformers have demonstrated great potential in computer vision. However, previous post-training quantization methods performed not well on vision transformer, resulting in more than 1% accuracy drop even in 8-bit quantization. Therefore, we analyze the problems of quantization on vision transformers. We observe the distributions of activation values after softmax and GELU functions are quite different from the Gaussian distribution. We also observe that common quantization metrics, such as MSE and cosine distance, are inaccurate to determine the optimal scaling factor. In this paper, we propose the twin uniform quantization method to reduce the quantization error on these activation values. And we propose to use a Hessian guided metric to evaluate different scaling factors, which improves the accuracy of calibration at a small cost. To enable the fast quantization of vision transformers, we develop an efficient framework, PTQ4ViT. Experiments show the quantized vision transformers achieve near-lossless prediction accuracy (less than 0.5% drop at 8-bit quantization) on the ImageNet classification task.
Create account to get full access
Overview
- Quantization is a method to compress neural networks, which has been successful for convolutional neural networks (CNNs).
- Vision transformers have shown great potential in computer vision, but previous post-training quantization methods performed poorly on them, causing significant accuracy drops.
- This paper analyzes the problems of quantization on vision transformers and proposes solutions to address them.
Plain English Explanation
Quantization is a technique used to make neural networks smaller and more efficient by reducing the precision of the numbers they use. This has worked well for a type of neural network called convolutional neural networks (CNNs), which are commonly used for computer vision tasks.
Recently, a new type of neural network called vision transformers has been developed, and it has shown a lot of promise in computer vision applications. However, when researchers tried to use the previous quantization methods on vision transformers, they found that it caused the networks to lose a lot of accuracy, sometimes more than 1% even when quantizing to just 8-bit precision.
The researchers in this paper set out to understand why quantization was not working well for vision transformers. They observed that the distribution of the activation values (the numbers flowing through the network) after certain mathematical functions were quite different from the normal distribution that the previous quantization methods were designed for. They also found that the common ways of measuring quantization error, like mean squared error and cosine distance, were not accurate for determining the best scaling factors to use when quantizing vision transformers.
To address these problems, the researchers propose a new quantization method called "twin uniform quantization" that is better suited for the unique characteristics of vision transformer activations. They also introduce a new metric based on the Hessian (a mathematical concept) to more accurately evaluate different scaling factors during the quantization process.
By using these new techniques, the researchers were able to quantize vision transformers to 8-bit precision with less than 0.5% drop in accuracy on the ImageNet image classification task. This is a significant improvement over the previous methods.
Technical Explanation
The paper proposes a post-training quantization (PTQ) framework called PTQ4ViT to efficiently quantize vision transformers. The key innovations include:
-
Twin Uniform Quantization: The researchers observe that the distributions of activation values after the softmax and GELU functions in vision transformers are quite different from the Gaussian distribution assumed by previous quantization methods. To address this, they propose a "twin uniform quantization" scheme that uses separate scaling factors for positive and negative activation values.
-
Hessian-Guided Metric: The common quantization metrics like mean squared error (MSE) and cosine distance were found to be inaccurate in determining the optimal scaling factors for vision transformers. The paper introduces a new Hessian-guided metric that better captures the quantization error and improves the calibration accuracy at a small computational cost.
The proposed PTQ4ViT framework is evaluated on the ImageNet classification task and is shown to achieve near-lossless performance (less than 0.5% drop) when quantizing vision transformers to 8-bit precision. This represents a significant improvement over previous post-training quantization methods for vision transformers, which suffered from more than 1% accuracy drop.
Critical Analysis
The paper provides a thorough analysis of the challenges in quantizing vision transformers and proposes effective solutions to address them. The twin uniform quantization and Hessian-guided metric are novel contributions that demonstrate the importance of understanding the unique characteristics of different neural network architectures when developing quantization techniques.
However, the paper does not provide much discussion on the potential limitations or areas for further research. For example, it would be interesting to see how the proposed methods perform on other vision transformer architectures or tasks beyond image classification. Additionally, the computational overhead of the Hessian-guided metric is not extensively analyzed, and there may be opportunities to further optimize the quantization process.
Overall, the PTQ4ViT framework represents an important step forward in making vision transformers more efficient and accessible for real-world applications. The insights and techniques presented in this paper could also inspire further research in quantization for other emerging neural network architectures.
Conclusion
This paper addresses a critical challenge in the deployment of vision transformers: efficiently quantizing them without significant accuracy loss. By proposing the twin uniform quantization method and the Hessian-guided metric, the researchers were able to achieve near-lossless 8-bit quantization of vision transformers on the ImageNet classification task.
These advancements in post-training quantization for vision transformers could have far-reaching implications. By making these models more compact and efficient, they can be more easily deployed on resource-constrained devices, expanding the reach of powerful vision transformer models. This could lead to improved computer vision capabilities in a wide range of applications, from autonomous vehicles to medical imaging.
The techniques and insights presented in this paper also serve as a valuable contribution to the broader field of neural network compression and efficiency optimization. As new neural network architectures continue to emerge, the ability to effectively quantize them will be crucial for unlocking their full potential in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, Hwanjun Song
0
0
Recently, vision transformers (ViTs) have superseded convolutional neural networks in numerous applications, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers with optimized attention computation of linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. For mobile devices, achieving optimal acceleration for ViTs necessitates the strategic integration of quantization techniques and efficient hybrid transformer structures. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, we discover that applying existing post-training quantization (PTQ) methods for ViTs to efficient hybrid transformers leads to a drastic accuracy drop, attributed to the four following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters ($<$5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid ViTs (MobileViTv1, MobileViTv2, Mobile-Former, EfficientFormerV1, EfficientFormerV2). We achieve a significant improvement of 17.73% for 8-bit and 29.75% for 6-bit on average, respectively, compared with existing PTQ methods (EasyQuant, FQ-ViT, PTQ4ViT, and RepQ-ViT)}. We plan to release our code at https://gitlab.com/ones-ai/q-hyvit.
5/20/2024

PTQ4DiT: Post-training Quantization for Diffusion Transformers
Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, Yan Yan
0
0
The recent introduction of Diffusion Transformers (DiTs) has demonstrated exceptional capabilities in image generation by using a different backbone architecture, departing from traditional U-Nets and embracing the scalable nature of transformers. Despite their advanced capabilities, the wide deployment of DiTs, particularly for real-time applications, is currently hampered by considerable computational demands at the inference stage. Post-training Quantization (PTQ) has emerged as a fast and data-efficient solution that can significantly reduce computation and memory footprint by using low-bit weights and activations. However, its applicability to DiTs has not yet been explored and faces non-trivial difficulties due to the unique design of DiTs. In this paper, we propose PTQ4DiT, a specifically designed PTQ method for DiTs. We discover two primary quantization challenges inherent in DiTs, notably the presence of salient channels with extreme magnitudes and the temporal variability in distributions of salient activation over multiple timesteps. To tackle these challenges, we propose Channel-wise Salience Balancing (CSB) and Spearmen's $rho$-guided Salience Calibration (SSC). CSB leverages the complementarity property of channel magnitudes to redistribute the extremes, alleviating quantization errors for both activations and weights. SSC extends this approach by dynamically adjusting the balanced salience to capture the temporal variations in activation. Additionally, to eliminate extra computational costs caused by PTQ4DiT during inference, we design an offline re-parameterization strategy for DiTs. Experiments demonstrate that our PTQ4DiT successfully quantizes DiTs to 8-bit precision (W8A8) while preserving comparable generation ability and further enables effective quantization to 4-bit weight precision (W4A8) for the first time.
5/28/2024
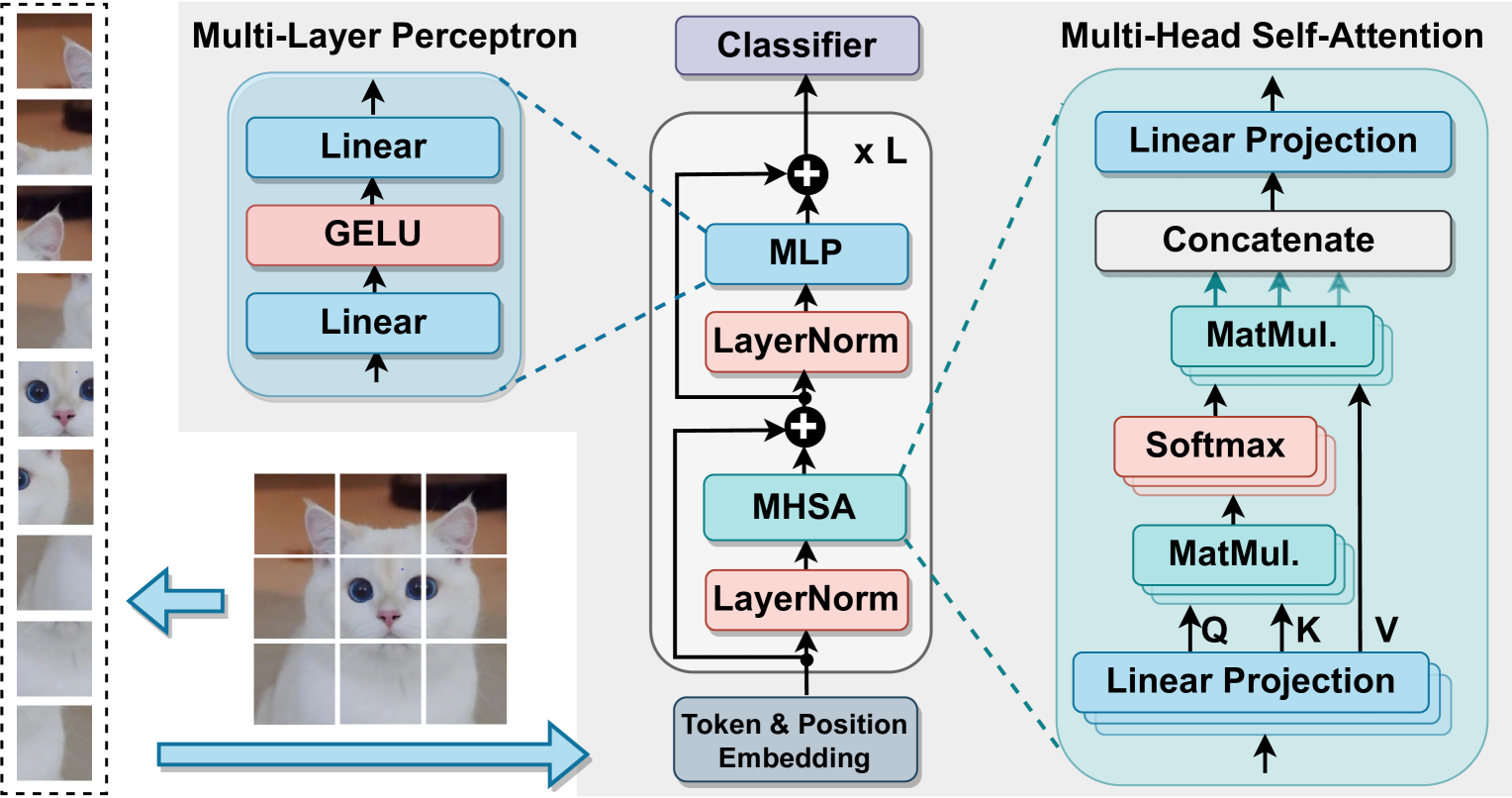
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
Huihong Shi, Haikuo Shao, Wendong Mao, Zhongfeng Wang
0
0
Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with textit{standard ViTs}, we focus our attention towards the quantization and acceleration for textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose emph{Trio-ViT} accordingly. Specifically, at the algorithm level, we develop a {tailored post-training quantization engine} taking the unique activation distributions of Softmax-free efficient ViTs into full consideration, aiming to boost quantization accuracy. Furthermore, at the hardware level, we build an accelerator dedicated to the specific Convolution-Transformer hybrid architecture of efficient ViTs, thereby enhancing hardware efficiency. Extensive experimental results consistently prove the effectiveness of our Trio-ViT framework. {Particularly, we can gain up to $uparrow$$mathbf{7.2}times$ and $uparrow$$mathbf{14.6}times$ FPS under comparable accuracy over state-of-the-art ViT accelerators, as well as $uparrow$$mathbf{5.9}times$ and $uparrow$$mathbf{2.0}times$ DSP efficiency.} Codes will be released publicly upon acceptance.
5/8/2024
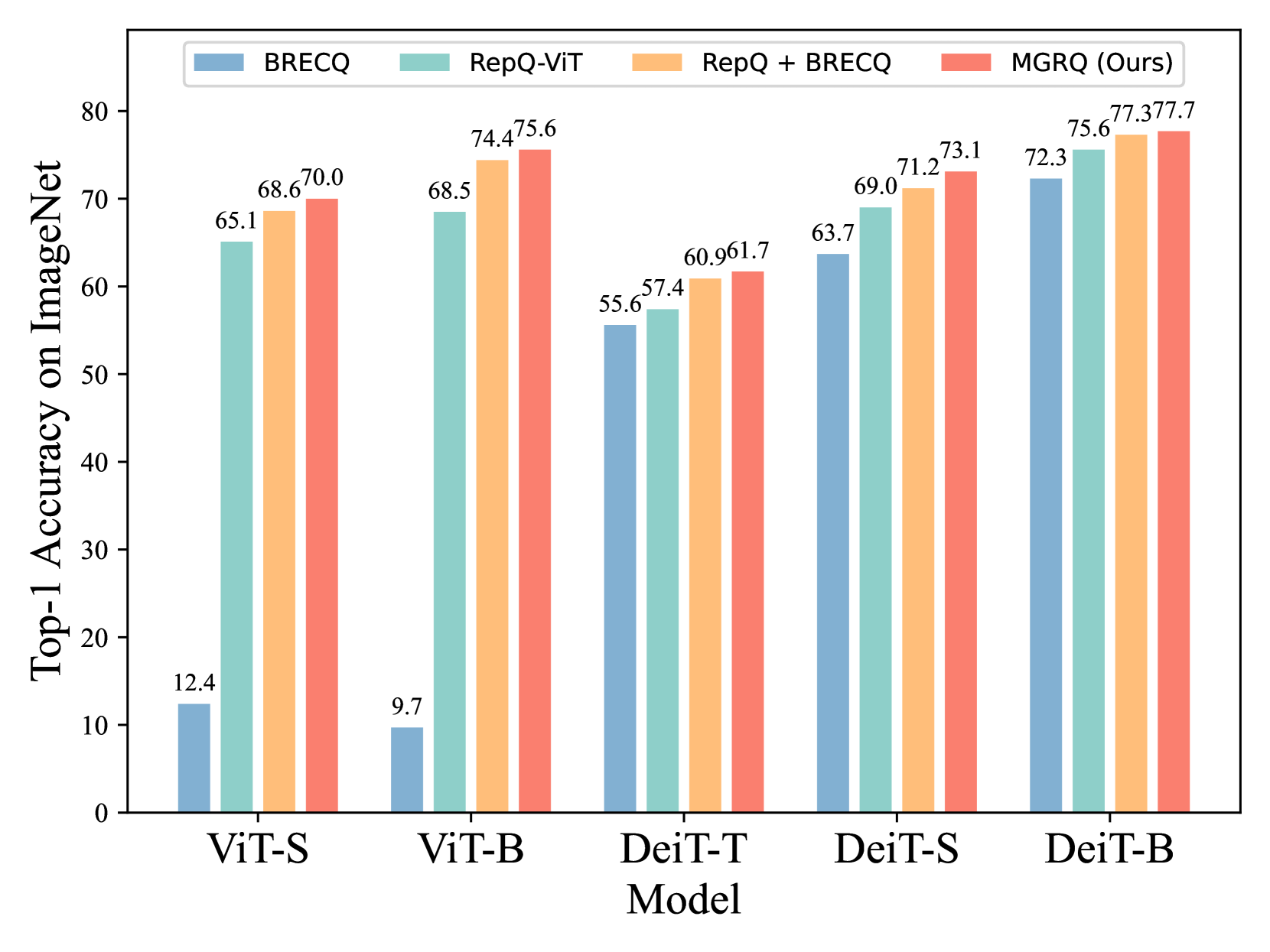
MGRQ: Post-Training Quantization For Vision Transformer With Mixed Granularity Reconstruction
Lianwei Yang, Zhikai Li, Junrui Xiao, Haisong Gong, Qingyi Gu
0
0
Post-training quantization (PTQ) efficiently compresses vision models, but unfortunately, it accompanies a certain degree of accuracy degradation. Reconstruction methods aim to enhance model performance by narrowing the gap between the quantized model and the full-precision model, often yielding promising results. However, efforts to significantly improve the performance of PTQ through reconstruction in the Vision Transformer (ViT) have shown limited efficacy. In this paper, we conduct a thorough analysis of the reasons for this limited effectiveness and propose MGRQ (Mixed Granularity Reconstruction Quantization) as a solution to address this issue. Unlike previous reconstruction schemes, MGRQ introduces a mixed granularity reconstruction approach. Specifically, MGRQ enhances the performance of PTQ by introducing Extra-Block Global Supervision and Intra-Block Local Supervision, building upon Optimized Block-wise Reconstruction. Extra-Block Global Supervision considers the relationship between block outputs and the model's output, aiding block-wise reconstruction through global supervision. Meanwhile, Intra-Block Local Supervision reduces generalization errors by aligning the distribution of outputs at each layer within a block. Subsequently, MGRQ is further optimized for reconstruction through Mixed Granularity Loss Fusion. Extensive experiments conducted on various ViT models illustrate the effectiveness of MGRQ. Notably, MGRQ demonstrates robust performance in low-bit quantization, thereby enhancing the practicality of the quantized model.
6/14/2024