PUAL: A Classifier on Trifurcate Positive-Unlabeled Data
2405.20970
0
0

Abstract
Positive-unlabeled (PU) learning aims to train a classifier using the data containing only labeled-positive instances and unlabeled instances. However, existing PU learning methods are generally hard to achieve satisfactory performance on trifurcate data, where the positive instances distribute on both sides of the negative instances. To address this issue, firstly we propose a PU classifier with asymmetric loss (PUAL), by introducing a structure of asymmetric loss on positive instances into the objective function of the global and local learning classifier. Then we develop a kernel-based algorithm to enable PUAL to obtain non-linear decision boundary. We show that, through experiments on both simulated and real-world datasets, PUAL can achieve satisfactory classification on trifurcate data.
Create account to get full access
Overview
- This paper introduces PUAL, a new classifier for handling trifurcate positive-unlabeled (PU) data.
- Trifurcate PU data refers to a scenario where the unlabeled dataset is further split into two subsets: positively-relevant and negatively-relevant.
- The proposed PUAL framework leverages this additional information to improve the performance of PU learning.
Plain English Explanation
The paper discusses a new machine learning technique called PUAL, which is designed to work with a specific type of data called trifurcate positive-unlabeled (PU) data. In a typical PU learning scenario, you have a dataset with some labeled positive examples and a larger set of unlabeled examples, which may contain both positive and negative instances.
The key innovation in this paper is that the unlabeled data is further divided into two subsets: positively-relevant and negatively-relevant. This additional information can be valuable for improving the performance of the PU learning algorithm. The PUAL framework effectively leverages this trifurcate structure to build a more accurate classifier compared to standard PU learning approaches.
The paper provides a technical description of the PUAL algorithm and demonstrates its effectiveness through experiments on several real-world datasets. Overall, the PUAL method represents an important advance in PU learning, which has applications in areas like text classification, anomaly detection, and semi-supervised learning.
Technical Explanation
The paper introduces a new classifier called PUAL (Positive-Unlabeled Adversarial Learning) for handling trifurcate positive-unlabeled (PU) data. In a trifurcate PU setting, the unlabeled dataset is further divided into two subsets: positively-relevant and negatively-relevant. This additional information can be leveraged to improve the performance of PU learning.
The PUAL framework consists of two key components: a classifier network and an adversarial network. The classifier network is trained to predict the probability of a sample being positive, while the adversarial network aims to distinguish between the positively-relevant and negatively-relevant unlabeled subsets. By jointly optimizing these two networks, PUAL can effectively utilize the trifurcate structure of the PU data to learn a more accurate classifier.
The paper evaluates PUAL on several benchmark datasets, including text classification, anomaly detection, and graph-based PU learning. The results demonstrate that PUAL outperforms state-of-the-art PU learning methods, particularly when the additional positively-relevant and negatively-relevant unlabeled subsets are informative.
Critical Analysis
The paper presents a novel and promising approach to PU learning, but there are a few caveats to consider:
-
Reliance on Trifurcate Data: The PUAL method relies on the availability of trifurcate PU data, which may not always be feasible in real-world scenarios. Obtaining the additional positively-relevant and negatively-relevant unlabeled subsets can be challenging, limiting the practical applicability of the method.
-
Sensitivity to Unlabeled Subset Quality: The performance of PUAL is heavily dependent on the quality of the positively-relevant and negatively-relevant unlabeled subsets. If these subsets are not well-separated or contain significant noise, the adversarial training component may not be effective, potentially leading to suboptimal classifier performance.
-
Computational Complexity: The joint optimization of the classifier and adversarial networks can be computationally expensive, especially for large-scale datasets. This may limit the scalability of the PUAL method in some applications.
Despite these limitations, the PUAL framework represents an interesting and valuable contribution to the field of PU learning. Future research could explore ways to relax the trifurcate data assumption or develop techniques to more robustly handle noisy or imperfect unlabeled subsets.
Conclusion
The PUAL paper introduces a novel classifier for handling trifurcate positive-unlabeled data, a challenging scenario where the unlabeled dataset is further divided into positively-relevant and negatively-relevant subsets. By leveraging this additional information, the PUAL framework can learn a more accurate classifier compared to standard PU learning methods.
While the reliance on trifurcate data and sensitivity to unlabeled subset quality are potential limitations, the PUAL approach represents an important advancement in PU learning, with applications in various domains such as text classification, anomaly detection, and semi-supervised learning. As the field of PU learning continues to evolve, the insights and techniques presented in this paper can serve as a foundation for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
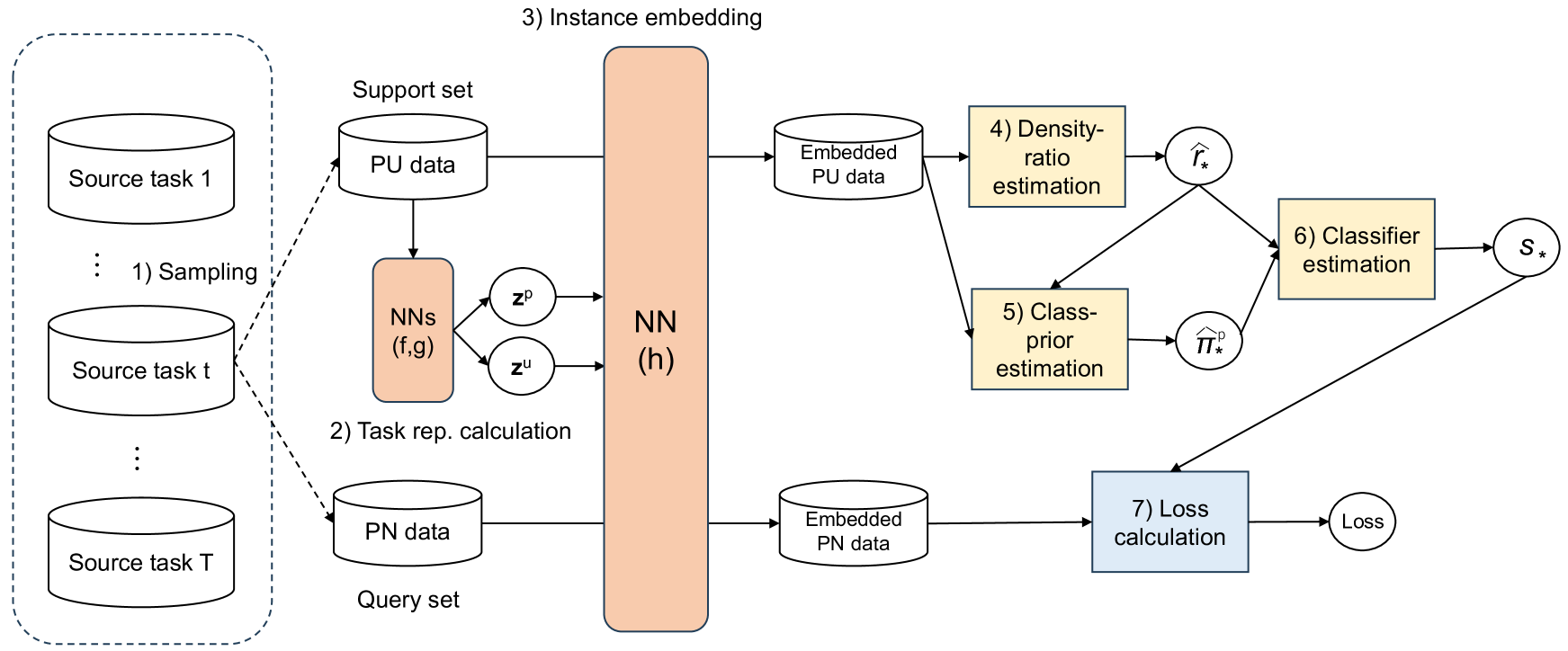
Meta-learning for Positive-unlabeled Classification
Atsutoshi Kumagai, Tomoharu Iwata, Yasuhiro Fujiwara
0
0
We propose a meta-learning method for positive and unlabeled (PU) classification, which improves the performance of binary classifiers obtained from only PU data in unseen target tasks. PU learning is an important problem since PU data naturally arise in real-world applications such as outlier detection and information retrieval. Existing PU learning methods require many PU data, but sufficient data are often unavailable in practice. The proposed method minimizes the test classification risk after the model is adapted to PU data by using related tasks that consist of positive, negative, and unlabeled data. We formulate the adaptation as an estimation problem of the Bayes optimal classifier, which is an optimal classifier to minimize the classification risk. The proposed method embeds each instance into a task-specific space using neural networks. With the embedded PU data, the Bayes optimal classifier is estimated through density-ratio estimation of PU densities, whose solution is obtained as a closed-form solution. The closed-form solution enables us to efficiently and effectively minimize the test classification risk. We empirically show that the proposed method outperforms existing methods with one synthetic and three real-world datasets.
6/7/2024
⛏️
Positive Unlabeled Contrastive Learning
Anish Acharya, Sujay Sanghavi, Li Jing, Bhargav Bhushanam, Dhruv Choudhary, Michael Rabbat, Inderjit Dhillon
0
0
Self-supervised pretraining on unlabeled data followed by supervised fine-tuning on labeled data is a popular paradigm for learning from limited labeled examples. We extend this paradigm to the classical positive unlabeled (PU) setting, where the task is to learn a binary classifier given only a few labeled positive samples, and (often) a large amount of unlabeled samples (which could be positive or negative). We first propose a simple extension of standard infoNCE family of contrastive losses, to the PU setting; and show that this learns superior representations, as compared to existing unsupervised and supervised approaches. We then develop a simple methodology to pseudo-label the unlabeled samples using a new PU-specific clustering scheme; these pseudo-labels can then be used to train the final (positive vs. negative) classifier. Our method handily outperforms state-of-the-art PU methods over several standard PU benchmark datasets, while not requiring a-priori knowledge of any class prior (which is a common assumption in other PU methods). We also provide a simple theoretical analysis that motivates our methods.
4/1/2024
📶
Soft Label PU Learning
Puning Zhao, Jintao Deng, Xu Cheng
0
0
PU learning refers to the classification problem in which only part of positive samples are labeled. Existing PU learning methods treat unlabeled samples equally. However, in many real tasks, from common sense or domain knowledge, some unlabeled samples are more likely to be positive than others. In this paper, we propose soft label PU learning, in which unlabeled data are assigned soft labels according to their probabilities of being positive. Considering that the ground truth of TPR, FPR, and AUC are unknown, we then design PU counterparts of these metrics to evaluate the performances of soft label PU learning methods within validation data. We show that these new designed PU metrics are good substitutes for the real metrics. After that, a method that optimizes such metrics is proposed. Experiments on public datasets and real datasets for anti-cheat services from Tencent games demonstrate the effectiveness of our proposed method.
5/6/2024
👁️
Positive Unlabeled Learning Selected Not At Random (PULSNAR): class proportion estimation when the SCAR assumption does not hold
Praveen Kumar, Christophe G. Lambert
0
0
Positive and Unlabeled (PU) learning is a type of semi-supervised binary classification where the machine learning algorithm differentiates between a set of positive instances (labeled) and a set of both positive and negative instances (unlabeled). PU learning has broad applications in settings where confirmed negatives are unavailable or difficult to obtain, and there is value in discovering positives among the unlabeled (e.g., viable drugs among untested compounds). Most PU learning algorithms make the emph{selected completely at random} (SCAR) assumption, namely that positives are selected independently of their features. However, in many real-world applications, such as healthcare, positives are not SCAR (e.g., severe cases are more likely to be diagnosed), leading to a poor estimate of the proportion, $alpha$, of positives among unlabeled examples and poor model calibration, resulting in an uncertain decision threshold for selecting positives. PU learning algorithms vary; some estimate only the proportion, $alpha$, of positives in the unlabeled set, while others calculate the probability that each specific unlabeled instance is positive, and some can do both. We propose two PU learning algorithms to estimate $alpha$, calculate calibrated probabilities for PU instances, and improve classification metrics: i) PULSCAR (positive unlabeled learning selected completely at random), and ii) PULSNAR (positive unlabeled learning selected not at random). PULSNAR employs a divide-and-conquer approach to cluster SNAR positives into subtypes and estimates $alpha$ for each subtype by applying PULSCAR to positives from each cluster and all unlabeled. In our experiments, PULSNAR outperformed state-of-the-art approaches on both synthetic and real-world benchmark datasets.
5/7/2024