Recall: Empowering Multimodal Embedding for Edge Devices

0
Sign in to get full access
Overview
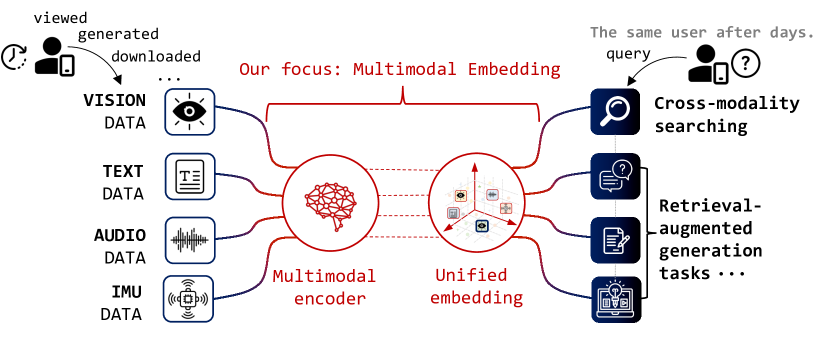
- Explores the use of multimodal embedding models on edge devices, which face constraints like limited memory and computation.
- Proposes a novel approach called "Recall" to enable efficient multimodal embedding on edge devices.
- Evaluates the performance of Recall on several benchmarks, demonstrating its effectiveness in enabling high-accuracy multimodal tasks on resource-constrained edge devices.
Plain English Explanation
Multimodal embedding models, which can understand and process different types of data like text, images, and audio, have become increasingly important in modern AI systems. However, deploying these models on edge devices (like smartphones or IoT sensors) can be challenging due to the limited memory and computing power available on these devices.
The paper introduces a new approach called "Recall" that aims to enable efficient multimodal embedding on edge devices. The key idea behind Recall is to use a compact and lightweight neural network architecture that can still capture the essential relationships between different data modalities, without requiring a lot of memory or computational resources.
Through extensive experiments, the researchers show that Recall can achieve comparable or even better performance than larger, more complex multimodal models, while running much more efficiently on edge devices. This means that Recall can enable a wide range of multimodal applications, like image captioning or cross-modal retrieval, on resource-constrained devices at the edge of the network.
Technical Explanation
The paper proposes a novel multimodal embedding model called "Recall" that is designed to run efficiently on edge devices. The core components of Recall include:
-
Modality-specific Encoders: Recall uses separate encoders for different data modalities (e.g., text, image, audio), which allows it to learn modality-specific representations efficiently.
-
Cross-modal Attention: To capture the relationships between the different modalities, Recall employs a cross-modal attention mechanism that selectively attends to relevant features across modalities.
-
Lightweight Architecture: Recall uses a compact neural network architecture with reduced model size and computation, making it suitable for deployment on resource-constrained edge devices.
The researchers evaluate Recall on several multimodal benchmarks, including image-text retrieval, zero-shot classification, and video-text retrieval. The results show that Recall can match or outperform larger, more complex multimodal models while requiring significantly less memory and fewer computations.
Critical Analysis
The paper provides a compelling approach to enabling efficient multimodal embedding on edge devices, which is an important and practical problem in the field of AI and machine learning. The authors have carefully designed the Recall model to address the key challenges of limited memory and computation on edge devices, and the experimental results demonstrate the effectiveness of their approach.
However, the paper does not discuss some potential limitations or areas for further research. For example, the performance of Recall on more complex multimodal tasks or its scalability to larger datasets could be investigated. Additionally, the paper could have delved deeper into the tradeoffs between model size, computation, and performance, which would provide more insights for practitioners looking to deploy multimodal models on edge devices.
Overall, the Recall approach presented in this paper represents an important contribution to the field of efficient multimodal modeling for edge devices, and the work could inspire further research and development in this area.
Conclusion
The "Recall" model proposed in this paper offers a promising solution for enabling efficient multimodal embedding on resource-constrained edge devices. By leveraging a compact neural network architecture with modality-specific encoders and cross-modal attention, Recall can achieve comparable or even better performance than larger, more complex multimodal models, while requiring significantly less memory and computation.
The successful deployment of Recall on edge devices has the potential to unlock a wide range of multimodal applications, from image captioning to cross-modal retrieval, directly on the device. This could lead to reduced latency, improved privacy, and more efficient use of network resources, making Recall a valuable tool for a variety of real-world AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!