Reducing Bias in Federated Class-Incremental Learning with Hierarchical Generative Prototypes
2406.02447
0
0

Abstract
Federated Learning (FL) aims at unburdening the training of deep models by distributing computation across multiple devices (clients) while safeguarding data privacy. On top of that, Federated Continual Learning (FCL) also accounts for data distribution evolving over time, mirroring the dynamic nature of real-world environments. In this work, we shed light on the Incremental and Federated biases that naturally emerge in FCL. While the former is a known problem in Continual Learning, stemming from the prioritization of recently introduced classes, the latter (i.e., the bias towards local distributions) remains relatively unexplored. Our proposal constrains both biases in the last layer by efficiently fine-tuning a pre-trained backbone using learnable prompts, resulting in clients that produce less biased representations and more biased classifiers. Therefore, instead of solely relying on parameter aggregation, we also leverage generative prototypes to effectively balance the predictions of the global model. Our method improves on the current State Of The Art, providing an average increase of +7.9% in accuracy.
Create account to get full access
Overview
- This paper proposes a new approach called Hierarchical Generative Prototypes (HGP) to address the problem of bias in federated class-incremental learning.
- Federated learning allows training models on decentralized data, but can lead to biased models due to data heterogeneity across clients.
- HGP uses a hierarchical generative model to capture the relationships between classes and generate class prototypes, reducing bias during incremental learning.
Plain English Explanation
Federated learning is a technique where multiple devices or organizations collaborate to train a shared machine learning model without directly sharing their private data. This is useful when data is distributed across many locations and cannot be centralized.
However, one challenge with federated learning is that the data on different devices or organizations may be quite different, leading to biased models. For example, if one group of users mostly uses a product for one purpose, and another group uses it for a different purpose, the final model might be better at one use case than the other.
The authors of this paper propose a new approach called Hierarchical Generative Prototypes (HGP) to address this bias problem in federated class-incremental learning. Class-incremental learning means adding new classes to a model over time, without forgetting previous ones.
The key idea behind HGP is to use a hierarchical generative model to capture the relationships between different classes. This allows the model to generate "prototypes" or examples of each class, which can be used to reduce bias during the incremental learning process. By understanding how the classes are related, the model can better adapt to new classes without forgetting old ones.
Technical Explanation
The authors propose a Hierarchical Generative Prototypes (HGP) framework to address bias in federated class-incremental learning. HGP uses a hierarchical generative model to capture the relationships between classes and generate class prototypes, which are then used to guide the incremental learning process and mitigate bias.
The HGP framework consists of three main components:
-
Hierarchical Generative Model: This is a generative model that learns a hierarchical representation of the class relationships. It can generate prototype examples for each class, which are used to guide the incremental learning.
-
Federated Prototype Aggregation: The generative prototypes from each client are aggregated in a federated manner, allowing the model to learn from diverse data sources while maintaining privacy.
-
Federated Class-Incremental Learning: The aggregated prototypes are used to regularize the incremental learning process, ensuring that new classes are learned without forgetting previous ones and reducing the impact of data heterogeneity across clients.
The authors evaluate HGP on several benchmark datasets and show that it outperforms state-of-the-art federated class-incremental learning methods in terms of accuracy and forgetting, demonstrating the effectiveness of the hierarchical generative approach in mitigating bias.
Critical Analysis
The authors present a compelling approach to address the bias problem in federated class-incremental learning. The use of a hierarchical generative model to capture class relationships and generate prototypes is a novel and promising idea.
One potential limitation is the complexity of the hierarchical generative model, which may require more computational resources and training time compared to simpler approaches. The authors acknowledge this and suggest exploring ways to make the model more efficient.
Additionally, the paper does not explore the sensitivity of HGP to different types of data heterogeneity across clients. It would be interesting to see how the approach performs in scenarios with more extreme distribution shifts or imbalances in the data.
Overall, the research presented in this paper represents an important step forward in addressing the challenges of federated learning, and the HGP framework could have significant implications for a wide range of applications where data privacy and bias are critical concerns.
Conclusion
This paper introduces a novel Hierarchical Generative Prototypes (HGP) framework to address the problem of bias in federated class-incremental learning. By using a hierarchical generative model to capture class relationships and generate class prototypes, HGP is able to mitigate the impact of data heterogeneity across clients and improve the performance of incremental learning.
The authors' experimental results demonstrate the effectiveness of HGP in maintaining high accuracy and reducing forgetting compared to state-of-the-art methods. This work represents an important contribution to the field of federated learning, with potential applications in a wide range of domains where data privacy and bias are critical concerns.
As the use of federated learning continues to grow, addressing issues like bias and forgetting will be crucial for deploying these techniques in real-world scenarios. The HGP framework proposed in this paper is a promising step in that direction, and the authors' insights could inspire further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Data-Free Federated Class Incremental Learning with Diffusion-Based Generative Memory
Naibo Wang, Yuchen Deng, Wenjie Feng, Jianwei Yin, See-Kiong Ng
0
0
Federated Class Incremental Learning (FCIL) is a critical yet largely underexplored issue that deals with the dynamic incorporation of new classes within federated learning (FL). Existing methods often employ generative adversarial networks (GANs) to produce synthetic images to address privacy concerns in FL. However, GANs exhibit inherent instability and high sensitivity, compromising the effectiveness of these methods. In this paper, we introduce a novel data-free federated class incremental learning framework with diffusion-based generative memory (DFedDGM) to mitigate catastrophic forgetting by generating stable, high-quality images through diffusion models. We design a new balanced sampler to help train the diffusion models to alleviate the common non-IID problem in FL, and introduce an entropy-based sample filtering technique from an information theory perspective to enhance the quality of generative samples. Finally, we integrate knowledge distillation with a feature-based regularization term for better knowledge transfer. Our framework does not incur additional communication costs compared to the baseline FedAvg method. Extensive experiments across multiple datasets demonstrate that our method significantly outperforms existing baselines, e.g., over a 4% improvement in average accuracy on the Tiny-ImageNet dataset.
5/29/2024
A Systematic Review of Federated Generative Models
Ashkan Vedadi Gargary, Emiliano De Cristofaro
0
0
Federated Learning (FL) has emerged as a solution for distributed systems that allow clients to train models on their data and only share models instead of local data. Generative Models are designed to learn the distribution of a dataset and generate new data samples that are similar to the original data. Many prior works have tried proposing Federated Generative Models. Using Federated Learning and Generative Models together can be susceptible to attacks, and designing the optimal architecture remains challenging. This survey covers the growing interest in the intersection of FL and Generative Models by comprehensively reviewing research conducted from 2019 to 2024. We systematically compare nearly 100 papers, focusing on their FL and Generative Model methods and privacy considerations. To make this field more accessible to newcomers, we highlight the state-of-the-art advancements and identify unresolved challenges, offering insights for future research in this evolving field.
5/28/2024

Federated Generative Learning with Foundation Models
Jie Zhang, Xiaohua Qi, Bo Zhao
0
0
Existing approaches in Federated Learning (FL) mainly focus on sending model parameters or gradients from clients to a server. However, these methods are plagued by significant inefficiency, privacy, and security concerns. Thanks to the emerging foundation generative models, we propose a novel federated learning framework, namely Federated Generative Learning. In this framework, each client can create text embeddings that are tailored to their local data, and send embeddings to the server. Then the informative training data can be synthesized remotely on the server using foundation generative models with these embeddings, which can benefit FL tasks. Our proposed framework offers several advantages, including increased communication efficiency, robustness to data heterogeneity, substantial performance improvements, and enhanced privacy protection. We validate these benefits through extensive experiments conducted on 12 datasets. For example, on the ImageNet100 dataset with a highly skewed data distribution, our method outperforms FedAvg by 12% in a single communication round, compared to FedAvg's performance over 200 communication rounds. We have released the code for all experiments conducted in this study.
6/4/2024
Federated Continual Learning Goes Online: Leveraging Uncertainty for Modality-Agnostic Class-Incremental Learning
Giuseppe Serra, Florian Buettner
0
0
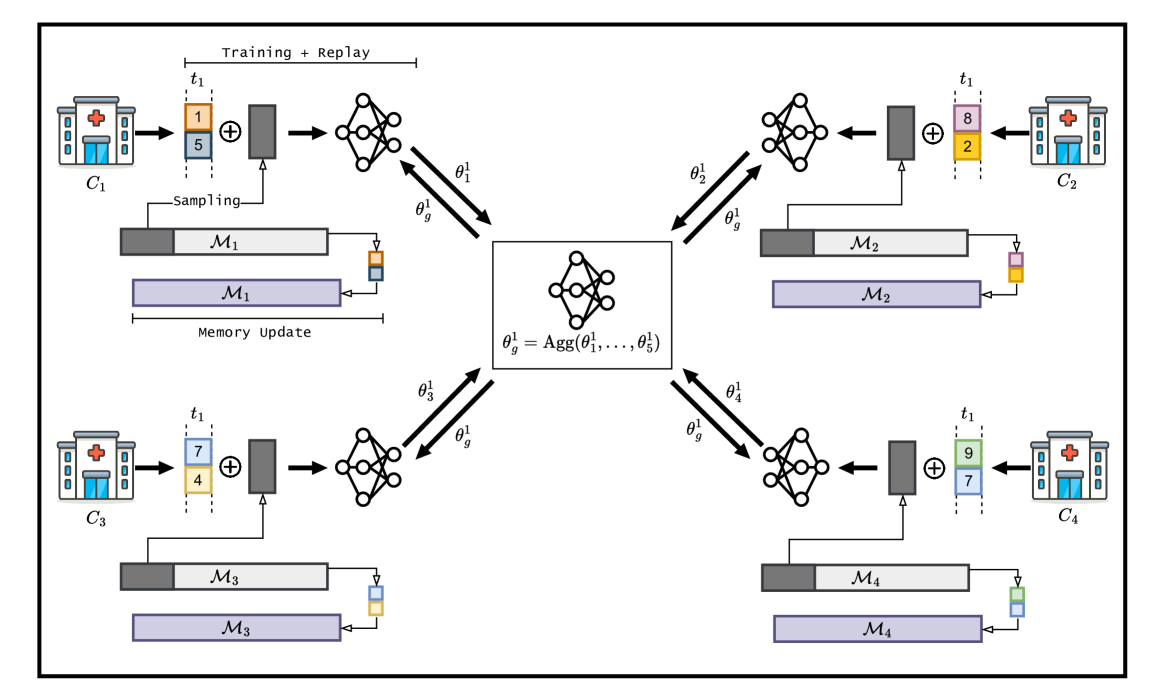
Given the ability to model more realistic and dynamic problems, Federated Continual Learning (FCL) has been increasingly investigated recently. A well-known problem encountered in this setting is the so-called catastrophic forgetting, for which the learning model is inclined to focus on more recent tasks while forgetting the previously learned knowledge. The majority of the current approaches in FCL propose generative-based solutions to solve said problem. However, this setting requires multiple training epochs over the data, implying an offline setting where datasets are stored locally and remain unchanged over time. Furthermore, the proposed solutions are tailored for vision tasks solely. To overcome these limitations, we propose a new modality-agnostic approach to deal with the online scenario where new data arrive in streams of mini-batches that can only be processed once. To solve catastrophic forgetting, we propose an uncertainty-aware memory-based approach. In particular, we suggest using an estimator based on the Bregman Information (BI) to compute the model's variance at the sample level. Through measures of predictive uncertainty, we retrieve samples with specific characteristics, and - by retraining the model on such samples - we demonstrate the potential of this approach to reduce the forgetting effect in realistic settings.
5/30/2024