Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
2405.12981
0
0
🔮
Abstract
Key-value (KV) caching plays an essential role in accelerating decoding for transformer-based autoregressive large language models (LLMs). However, the amount of memory required to store the KV cache can become prohibitive at long sequence lengths and large batch sizes. Since the invention of the transformer, two of the most effective interventions discovered for reducing the size of the KV cache have been Multi-Query Attention (MQA) and its generalization, Grouped-Query Attention (GQA). MQA and GQA both modify the design of the attention block so that multiple query heads can share a single key/value head, reducing the number of distinct key/value heads by a large factor while only minimally degrading accuracy. In this paper, we show that it is possible to take Multi-Query Attention a step further by also sharing key and value heads between adjacent layers, yielding a new attention design we call Cross-Layer Attention (CLA). With CLA, we find that it is possible to reduce the size of the KV cache by another 2x while maintaining nearly the same accuracy as unmodified MQA. In experiments training 1B- and 3B-parameter models from scratch, we demonstrate that CLA provides a Pareto improvement over the memory/accuracy tradeoffs which are possible with traditional MQA, enabling inference with longer sequence lengths and larger batch sizes than would otherwise be possible
Create account to get full access
Overview
- Key-value (KV) caching is essential for accelerating decoding in transformer-based autoregressive large language models (LLMs).
- The memory required for the KV cache can become prohibitive at long sequence lengths and large batch sizes.
- Two effective interventions for reducing the KV cache size are Multi-Query Attention (MQA) and Grouped-Query Attention (GQA).
- This paper introduces a new approach called Cross-Layer Attention (CLA) that further reduces the KV cache size while maintaining accuracy.
Plain English Explanation
Large language models (LLMs) are artificial intelligences that can generate human-like text. To make these models run efficiently, researchers use a technique called key-value (KV) caching. This caching stores important information that the model needs to access repeatedly, which speeds up the text generation process.
However, the amount of memory required for this KV cache can become very large, especially when the model is generating long sequences of text or processing large batches of input. This can make the model too resource-intensive to run on many devices.
Previous research has found two effective ways to reduce the size of the KV cache: Multi-Query Attention (MQA) and Grouped-Query Attention (GQA). These methods modify the attention mechanism in the model to use fewer distinct key and value heads, which reduces the overall size of the KV cache.
This new paper takes this idea a step further by also sharing key and value heads between adjacent layers of the model, a technique they call Cross-Layer Attention (CLA). The authors show that CLA can reduce the KV cache size by another 2x while maintaining nearly the same accuracy as the original MQA approach. This allows the model to run more efficiently, especially on long sequences and large batches.
Technical Explanation
The paper introduces a new attention mechanism called Cross-Layer Attention (CLA) that builds on previous work in Multi-Query Attention (MQA) and Grouped-Query Attention (GQA).
In a standard transformer model, the attention mechanism uses a separate set of key and value heads for each query head. This results in a large KV cache that can become prohibitive for long sequences and large batch sizes. MQA and GQA address this by having multiple query heads share a single key/value head, reducing the number of distinct key/value heads.
The key innovation in CLA is to take this sharing a step further by also sharing key and value heads between adjacent layers of the model. This additional level of weight sharing allows CLA to reduce the KV cache size by another 2x compared to MQA, while maintaining nearly the same model accuracy.
The authors evaluate CLA by training 1B- and 3B-parameter models from scratch and comparing the memory/accuracy tradeoffs to traditional MQA. They find that CLA provides a Pareto improvement, enabling inference with longer sequence lengths and larger batch sizes than would otherwise be possible.
Critical Analysis
The paper presents a compelling technique for reducing the memory requirements of key-value caching in large language models. The authors provide a thorough technical explanation and rigorous empirical evaluation to support their claims.
One potential limitation is that the paper only considers the memory efficiency of the KV cache, without analyzing the full computational or energy efficiency of the CLA approach. It's possible that the additional complexity of the CLA mechanism could offset some of the memory savings in practice.
Additionally, the paper does not explore the impact of CLA on other aspects of model performance, such as inference latency or response quality. While the authors demonstrate maintained accuracy, further research is needed to fully characterize the tradeoffs involved.
Finally, the paper is somewhat narrow in scope, focusing only on the KV cache optimization. It would be interesting to see how CLA could be combined with other memory-saving techniques, such as SqueezeAttention or SnapKV, to further push the boundaries of efficient LLM inference.
Overall, the Cross-Layer Attention approach presented in this paper represents a valuable contribution to the ongoing effort to make large language models more resource-efficient and accessible. The authors have provided a solid foundation for future research in this area.
Conclusion
This paper introduces a new technique called Cross-Layer Attention (CLA) that builds on previous work in Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) to further reduce the memory requirements of the key-value (KV) cache in transformer-based autoregressive large language models (LLMs).
By sharing key and value heads not only between query heads but also across adjacent layers, CLA is able to achieve a 2x reduction in KV cache size compared to MQA, while maintaining nearly the same model accuracy. This allows for more efficient inference, especially on long sequences and large batches, which can be crucial for deploying LLMs in resource-constrained environments.
The paper provides a solid technical foundation and empirical evaluation of the CLA approach, paving the way for future research on memory-efficient techniques for large language models. As these models continue to grow in size and capability, innovations like CLA will play an increasingly important role in making them more accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
QCQA: Quality and Capacity-aware grouped Query Attention
Vinay Joshi, Prashant Laddha, Shambhavi Sinha, Om Ji Omer, Sreenivas Subramoney
0
0
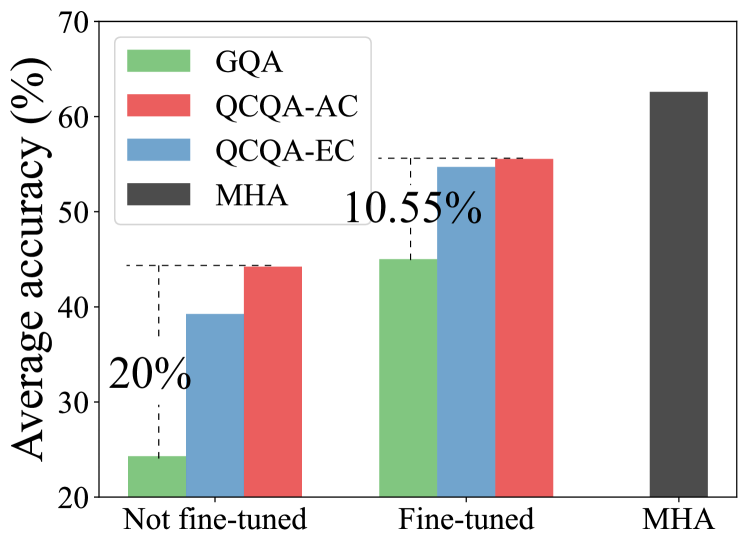
Excessive memory requirements of key and value features (KV-cache) present significant challenges in the autoregressive inference of large language models (LLMs), restricting both the speed and length of text generation. Approaches such as Multi-Query Attention (MQA) and Grouped Query Attention (GQA) mitigate these challenges by grouping query heads and consequently reducing the number of corresponding key and value heads. However, MQA and GQA decrease the KV-cache size requirements at the expense of LLM accuracy (quality of text generation). These methods do not ensure an optimal tradeoff between KV-cache size and text generation quality due to the absence of quality-aware grouping of query heads. To address this issue, we propose Quality and Capacity-Aware Grouped Query Attention (QCQA), which identifies optimal query head groupings using an evolutionary algorithm with a computationally efficient and inexpensive fitness function. We demonstrate that QCQA achieves a significantly better tradeoff between KV-cache capacity and LLM accuracy compared to GQA. For the Llama2 $7,$B model, QCQA achieves $mathbf{20}$% higher accuracy than GQA with similar KV-cache size requirements in the absence of fine-tuning. After fine-tuning both QCQA and GQA, for a similar KV-cache size, QCQA provides $mathbf{10.55},$% higher accuracy than GQA. Furthermore, QCQA requires $40,$% less KV-cache size than GQA to attain similar accuracy. The proposed quality and capacity-aware grouping of query heads can serve as a new paradigm for KV-cache optimization in autoregressive LLM inference.
6/18/2024

MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
Zayd Muhammad Kawakibi Zuhri, Muhammad Farid Adilazuarda, Ayu Purwarianti, Alham Fikri Aji
0
0
Auto-regressive inference of transformers benefit greatly from Key-Value (KV) caching, but can lead to major memory bottlenecks as model size, batch size, and sequence length grow at scale. We introduce Multi-Layer Key-Value (MLKV) sharing, a novel approach extending KV sharing across transformer layers to reduce memory usage beyond what was possible with Multi-Query Attention (MQA) and Grouped-Query Attention (GQA). Evaluations on various NLP benchmarks and inference metrics using uptrained Pythia-160M variants demonstrate that MLKV significantly reduces memory usage with minimal performance loss, reducing KV cache size down to a factor of 6x compared to MQA. These results highlight MLKV's potential for efficient deployment of transformer models at scale. We provide code at https://github.com/zaydzuhri/pythia-mlkv
6/18/2024

Effectively Compress KV Heads for LLM
Hao Yu, Zelan Yang, Shen Li, Yong Li, Jianxin Wu
0
0
The advent of pre-trained large language models (LLMs) has revolutionized various natural language processing tasks. These models predominantly employ an auto-regressive decoding mechanism that utilizes Key-Value (KV) caches to eliminate redundant calculations for previous tokens. Nevertheless, as context lengths and batch sizes increase, the linear expansion in memory footprint of KV caches becomes a key bottleneck of LLM deployment, which decreases generation speeds significantly. To mitigate this issue, previous techniques like multi-query attention (MQA) and grouped-query attention (GQA) have been developed, in order to reduce KV heads to accelerate inference with comparable accuracy to multi-head attention (MHA). Despite their effectiveness, existing strategies for compressing MHA often overlook the intrinsic properties of the KV caches. In this work, we explore the low-rank characteristics of the KV caches and propose a novel approach for compressing KV heads. In particular, we carefully optimize the MHA-to-GQA transformation to minimize compression error, and to remain compatible with rotary position embeddings (RoPE), we also introduce specialized strategies for key caches with RoPE. We demonstrate that our method can compress half or even three-quarters of KV heads while maintaining performance comparable to the original LLMs, which presents a promising direction for more efficient LLM deployment in resource-constrained environments.
6/12/2024
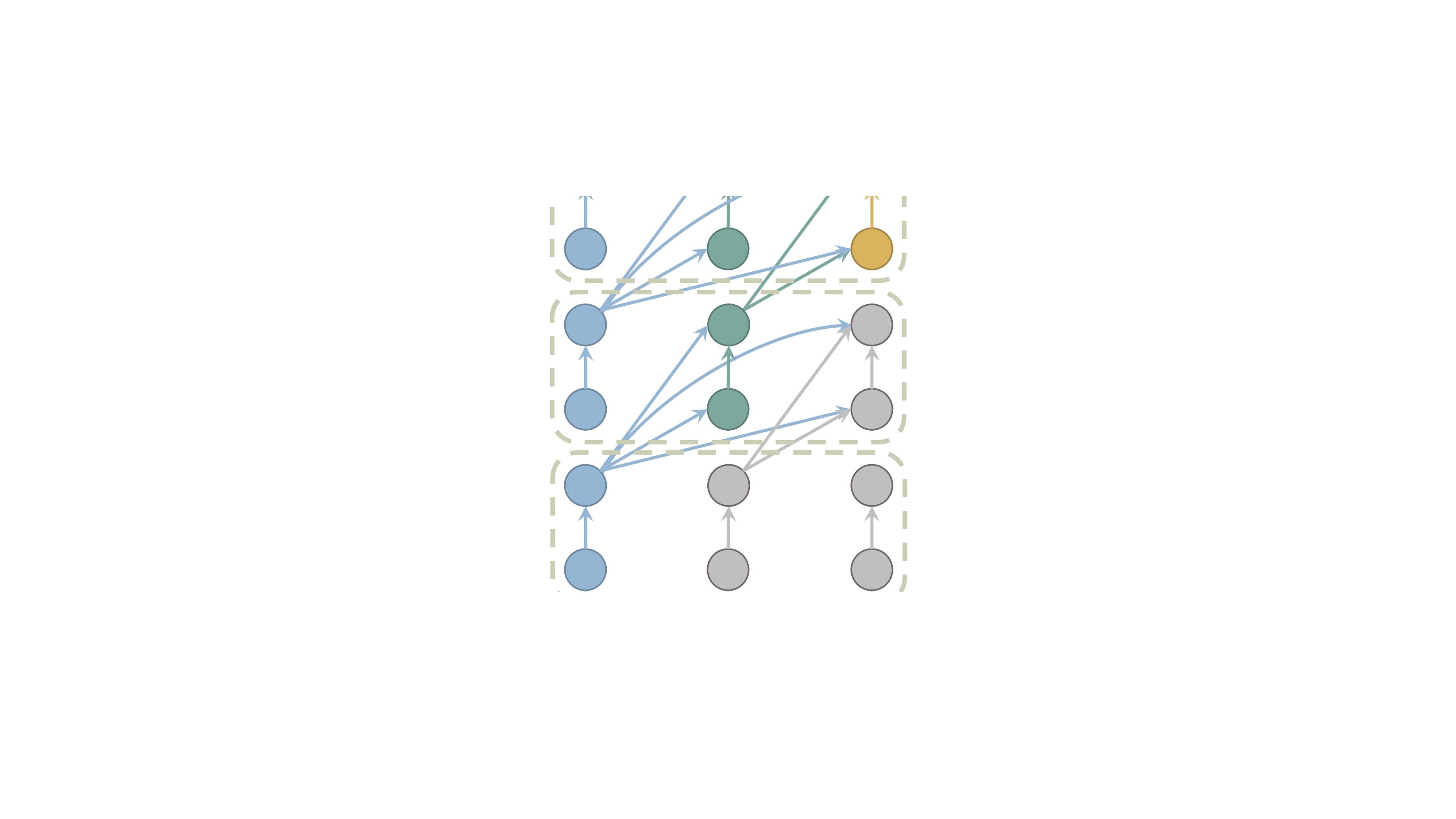
Layer-Condensed KV Cache for Efficient Inference of Large Language Models
Haoyi Wu, Kewei Tu
0
0
Huge memory consumption has been a major bottleneck for deploying high-throughput large language models in real-world applications. In addition to the large number of parameters, the key-value (KV) cache for the attention mechanism in the transformer architecture consumes a significant amount of memory, especially when the number of layers is large for deep language models. In this paper, we propose a novel method that only computes and caches the KVs of a small number of layers, thus significantly saving memory consumption and improving inference throughput. Our experiments on large language models show that our method achieves up to 26$times$ higher throughput than standard transformers and competitive performance in language modeling and downstream tasks. In addition, our method is orthogonal to existing transformer memory-saving techniques, so it is straightforward to integrate them with our model, achieving further improvement in inference efficiency. Our code is available at https://github.com/whyNLP/LCKV.
6/5/2024