Reference-based Metrics Disprove Themselves in Question Generation
2403.12242
0
0

Abstract
Reference-based metrics such as BLEU and BERTScore are widely used to evaluate question generation (QG). In this study, on QG benchmarks such as SQuAD and HotpotQA, we find that using human-written references cannot guarantee the effectiveness of the reference-based metrics. Most QG benchmarks have only one reference; we replicated the annotation process and collect another reference. A good metric was expected to grade a human-validated question no worse than generated questions. However, the results of reference-based metrics on our newly collected reference disproved the metrics themselves. We propose a reference-free metric consisted of multi-dimensional criteria such as naturalness, answerability, and complexity, utilizing large language models. These criteria are not constrained to the syntactic or semantic of a single reference question, and the metric does not require a diverse set of references. Experiments reveal that our metric accurately distinguishes between high-quality questions and flawed ones, and achieves state-of-the-art alignment with human judgment.
Create account to get full access
Overview
- This paper examines the limitations of reference-based metrics in automatically evaluating the quality of generated questions.
- The authors demonstrate that these metrics can fail to identify high-quality questions and even reward low-quality ones, undermining their usefulness.
- The paper highlights the need for more robust and comprehensive evaluation approaches in the field of question generation.
Plain English Explanation
When evaluating the quality of automatically generated questions, researchers often rely on reference-based metrics. These metrics compare the generated questions to a set of "reference" questions, which are typically created by humans. The idea is that the closer the generated questions are to the reference questions, the higher the quality.
However, this paper argues that reference-based metrics can be deeply flawed. The authors show that these metrics can sometimes reward low-quality questions and fail to recognize high-quality ones. This is a significant problem, as it means the metrics are not accurately reflecting the true quality of the generated questions.
To illustrate this, the authors provide examples where the reference-based metrics give high scores to questions that are actually quite poor, while giving low scores to questions that are much better. This demonstrates that these metrics are not a reliable way to assess the quality of generated questions.
The paper highlights the need for a more robust and comprehensive approach to evaluating question generation systems. Rather than relying solely on reference-based metrics, the authors suggest that a combination of different evaluation methods, including human judgments, may be necessary to accurately assess the quality of generated questions.
Technical Explanation
The paper begins by highlighting the widespread use of reference-based metrics in the field of question generation (QG), such as BLEU, METEOR, and BERTScore. These metrics compare the generated questions to a set of reference questions, with the assumption that the closer the generated questions are to the references, the higher the quality.
However, the authors argue that this assumption is flawed. They conduct a series of experiments that demonstrate the failure of reference-based metrics in accurately evaluating the quality of generated questions. The experiments involve collecting a dataset of reference questions and then using it to evaluate the performance of different QG models.
The results show that the reference-based metrics can often reward low-quality questions and fail to recognize high-quality ones. The authors provide several illustrative examples to support this claim, highlighting cases where the metrics give high scores to questions that are clearly problematic and low scores to questions that are much better.
The authors suggest that the failure of reference-based metrics in this context is due to the inherent complexity and diversity of question generation, which cannot be fully captured by simple comparisons to a limited set of reference questions. They argue that a more comprehensive approach, incorporating multiple evaluation methods such as human judgments and task-specific metrics, may be necessary to accurately assess the quality of generated questions.
Critical Analysis
The paper raises important concerns about the limitations of reference-based metrics in the context of question generation. The authors provide compelling evidence that these metrics can fail to identify high-quality questions and even reward low-quality ones, undermining their usefulness as evaluation tools.
One potential limitation of the study is the size and diversity of the reference dataset used. While the authors demonstrate the issues with reference-based metrics using this dataset, it's possible that a larger or more diverse set of reference questions could improve the performance of these metrics. Additionally, the paper does not explore the use of more advanced reference-based metrics, such as SpeechBERTScore, which may be more robust to the challenges identified in the paper.
It's also worth noting that reference-based metrics are widely used in other natural language generation tasks, such as machine translation and text summarization, where they have been shown to be useful. The issues identified in this paper may be more specific to the question generation domain, which has unique challenges due to the inherent complexity and diversity of questions.
Overall, the paper makes a strong case for the need to re-evaluate the use of reference-based metrics in question generation and explore alternative evaluation approaches that can more accurately capture the quality and usefulness of generated questions.
Conclusion
This paper presents a compelling critique of the use of reference-based metrics in the evaluation of question generation systems. The authors demonstrate that these widely-used metrics can fail to identify high-quality questions and even reward low-quality ones, undermining their usefulness as evaluation tools.
The findings of this study have important implications for the field of question generation, as they highlight the need for more robust and comprehensive evaluation approaches. By moving beyond simple comparisons to reference questions, researchers and developers can develop more reliable and informative ways to assess the quality and effectiveness of their question generation models.
The insights from this paper also have broader relevance for the field of natural language generation, where reference-based metrics are commonly employed. The authors' findings suggest that these metrics may not be a panacea, and that a more nuanced and context-specific approach to evaluation may be necessary to truly capture the quality and utility of generated content.
Overall, this paper serves as a valuable wake-up call, encouraging the research community to critically examine the assumptions and limitations of the evaluation methods they rely on. By doing so, we can work towards developing more robust and meaningful ways of assessing the performance of natural language generation systems, ultimately leading to more impactful and trustworthy applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Quality and Quantity of Machine Translation References for Automatic Metrics
Vil'em Zouhar, Ondv{r}ej Bojar
0
0
Automatic machine translation metrics typically rely on human translations to determine the quality of system translations. Common wisdom in the field dictates that the human references should be of very high quality. However, there are no cost-benefit analyses that could be used to guide practitioners who plan to collect references for machine translation evaluation. We find that higher-quality references lead to better metric correlations with humans at the segment-level. Having up to 7 references per segment and taking their average (or maximum) helps all metrics. Interestingly, the references from vendors of different qualities can be mixed together and improve metric success. Higher quality references, however, cost more to create and we frame this as an optimization problem: given a specific budget, what references should be collected to maximize metric success. These findings can be used by evaluators of shared tasks when references need to be created under a certain budget.
4/11/2024
📉
Not All Metrics Are Guilty: Improving NLG Evaluation by Diversifying References
Tianyi Tang, Hongyuan Lu, Yuchen Eleanor Jiang, Haoyang Huang, Dongdong Zhang, Wayne Xin Zhao, Tom Kocmi, Furu Wei
0
0
Most research about natural language generation (NLG) relies on evaluation benchmarks with limited references for a sample, which may result in poor correlations with human judgements. The underlying reason is that one semantic meaning can actually be expressed in different forms, and the evaluation with a single or few references may not accurately reflect the quality of the model's hypotheses. To address this issue, this paper presents a simple and effective method, named Div-Ref, to enhance existing evaluation benchmarks by enriching the number of references. We leverage large language models (LLMs) to diversify the expression of a single reference into multiple high-quality ones to cover the semantic space of the reference sentence as much as possible. We conduct comprehensive experiments to empirically demonstrate that diversifying the expression of reference can significantly enhance the correlation between automatic evaluation and human evaluation. This idea is compatible with recent LLM-based evaluation which can similarly derive advantages from incorporating multiple references. We strongly encourage future generation benchmarks to include more references, even if they are generated by LLMs, which is once for all. We release all the code and data at https://github.com/RUCAIBox/Div-Ref to facilitate research.
5/28/2024
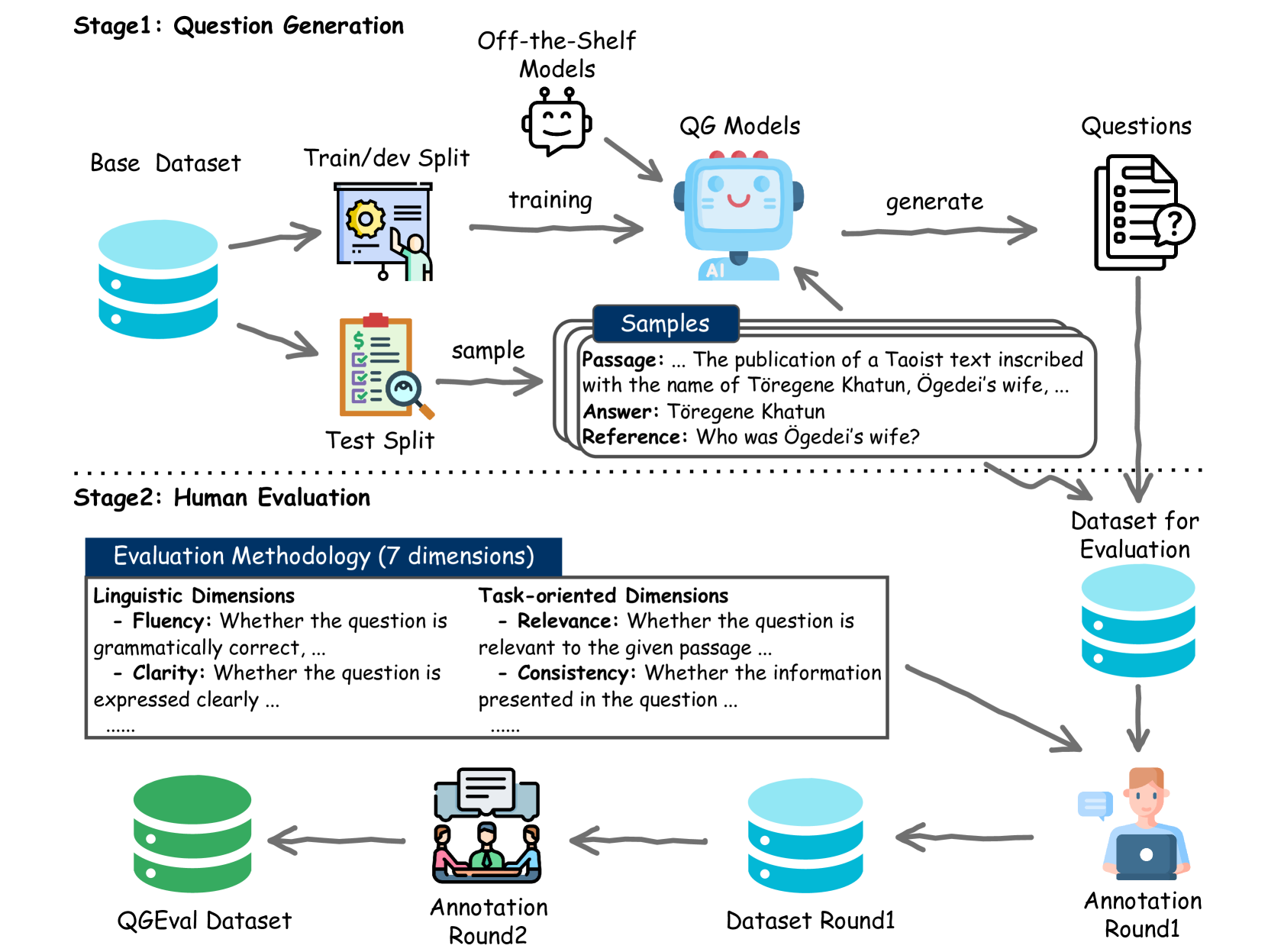
QGEval: A Benchmark for Question Generation Evaluation
Weiping Fu, Bifan Wei, Jianxiang Hu, Zhongmin Cai, Jun Liu
0
0
Automatically generated questions often suffer from problems such as unclear expression or factual inaccuracies, requiring a reliable and comprehensive evaluation of their quality. Human evaluation is frequently used in the field of question generation (QG) and is one of the most accurate evaluation methods. It also serves as the standard for automatic metrics. However, there is a lack of unified evaluation criteria, which hampers the development of both QG technologies and automatic evaluation methods. To address this, we propose QGEval, a multi-dimensional Evaluation benchmark for Question Generation, which evaluates both generated questions and existing automatic metrics across 7 dimensions: fluency, clarity, conciseness, relevance, consistency, answerability, and answer consistency. We demonstrate the appropriateness of these dimensions by examining their correlations and distinctions. Analysis with QGEval reveals that 1) most QG models perform unsatisfactorily in terms of answerability and answer consistency, and 2) existing metrics fail to align well with human assessments when evaluating generated questions across the 7 dimensions. We expect this work to foster the development of both QG technologies and automatic metrics for QG.
6/11/2024
🗣️
SpeechBERTScore: Reference-Aware Automatic Evaluation of Speech Generation Leveraging NLP Evaluation Metrics
Takaaki Saeki, Soumi Maiti, Shinnosuke Takamichi, Shinji Watanabe, Hiroshi Saruwatari
0
0
While subjective assessments have been the gold standard for evaluating speech generation, there is a growing need for objective metrics that are highly correlated with human subjective judgments due to their cost efficiency. This paper proposes reference-aware automatic evaluation methods for speech generation inspired by evaluation metrics in natural language processing. The proposed SpeechBERTScore computes the BERTScore for self-supervised dense speech features of the generated and reference speech, which can have different sequential lengths. We also propose SpeechBLEU and SpeechTokenDistance, which are computed on speech discrete tokens. The evaluations on synthesized speech show that our method correlates better with human subjective ratings than mel cepstral distortion and a recent mean opinion score prediction model. Also, they are effective in noisy speech evaluation and have cross-lingual applicability.
6/14/2024