Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey
2406.08115
0
0

Abstract
With rapidly increasing distributed deep learning workloads in large-scale data centers, efficient distributed deep learning framework strategies for resource allocation and workload scheduling have become the key to high-performance deep learning. The large-scale environment with large volumes of datasets, models, and computational and communication resources raises various unique challenges for resource allocation and workload scheduling in distributed deep learning, such as scheduling complexity, resource and workload heterogeneity, and fault tolerance. To uncover these challenges and corresponding solutions, this survey reviews the literature, mainly from 2019 to 2024, on efficient resource allocation and workload scheduling strategies for large-scale distributed DL. We explore these strategies by focusing on various resource types, scheduling granularity levels, and performance goals during distributed training and inference processes. We highlight critical challenges for each topic and discuss key insights of existing technologies. To illustrate practical large-scale resource allocation and workload scheduling in real distributed deep learning scenarios, we use a case study of training large language models. This survey aims to encourage computer science, artificial intelligence, and communications researchers to understand recent advances and explore future research directions for efficient framework strategies for large-scale distributed deep learning.
Create account to get full access
Overview
- Discusses the challenges of resource allocation and workload scheduling for large-scale distributed deep learning systems
- Explores techniques for GPU sharing, task scheduling, and handling large models with pipeline parallelism
- Surveys recent research advances in this area and their implications for improving the efficiency and scalability of distributed deep learning
Plain English Explanation
Deep learning is a powerful technique that has led to major advances in fields like image recognition and natural language processing. However, training large and complex deep learning models requires a significant amount of computational resources, such as GPUs. This is especially challenging in distributed settings where multiple users or teams are competing for access to limited GPU resources.
The paper provides an overview of the latest research on resource allocation and workload scheduling for large-scale distributed deep learning systems. It explores techniques for GPU sharing, task scheduling, and handling large models using [pipeline parallelism]. These innovations are aimed at improving the efficiency and scalability of distributed deep learning, allowing more users to access the computational power they need without overburdening the system.
Technical Explanation
The paper provides a comprehensive survey of recent research on resource allocation and workload scheduling for large-scale distributed deep learning. It covers several key techniques:
-
GPU Sharing: Researchers have developed advanced GPU sharing algorithms that can intelligently allocate GPU resources among multiple users or training tasks, maximizing utilization while ensuring fair and efficient access.
-
Task Scheduling: Novel task scheduling approaches have been proposed to optimize the execution of distributed deep learning workloads, taking into account factors like data dependencies, model size, and GPU availability.
-
Large Model Handling: To handle the growing size of deep learning models, the paper discusses techniques like [pipeline parallelism], which can split the model across multiple GPUs and execute the training process in stages.
The survey also highlights recent research advances in areas like communication-efficient distributed training, scheduling for computing continuum, and interpretable scheduling algorithms. These developments aim to improve the overall efficiency, scalability, and usability of large-scale distributed deep learning systems.
Critical Analysis
The paper provides a comprehensive overview of the state-of-the-art in resource allocation and workload scheduling for distributed deep learning. However, it also acknowledges several limitations and areas for further research:
-
Complexity of Real-World Deployments: The paper notes that many of the proposed techniques have been evaluated in simplified or idealized scenarios, and their performance in complex, real-world deployments with heterogeneous hardware, diverse workloads, and dynamic resource demands remains an open challenge.
-
Fairness and Prioritization: While the paper discusses GPU sharing and task scheduling algorithms, it suggests that more research is needed to ensure fair and equitable access to resources, especially in multi-tenant environments with competing priorities.
-
Integration with Higher-Level Frameworks: The authors highlight the need to seamlessly integrate resource allocation and scheduling mechanisms with higher-level deep learning frameworks and toolchains to provide a more cohesive and user-friendly experience for practitioners.
-
Energy Efficiency and Environmental Impact: As the scale and computational demands of distributed deep learning continue to grow, the paper suggests that future research should also consider the energy efficiency and environmental impact of these systems.
Conclusion
This survey paper provides a comprehensive overview of the latest research on resource allocation and workload scheduling for large-scale distributed deep learning. The techniques discussed, such as GPU sharing, task scheduling, and pipeline parallelism, have the potential to significantly improve the efficiency, scalability, and accessibility of these powerful machine learning systems. However, the paper also highlights the need for further research to address the complexity of real-world deployments, fairness concerns, and the broader environmental impact of these technologies. As the field of distributed deep learning continues to evolve, these advancements will play a crucial role in enabling more researchers, developers, and organizations to harness the transformative potential of deep learning at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Communication-Efficient Large-Scale Distributed Deep Learning: A Comprehensive Survey
Feng Liang, Zhen Zhang, Haifeng Lu, Victor C. M. Leung, Yanyi Guo, Xiping Hu
0
0
With the rapid growth in the volume of data sets, models, and devices in the domain of deep learning, there is increasing attention on large-scale distributed deep learning. In contrast to traditional distributed deep learning, the large-scale scenario poses new challenges that include fault tolerance, scalability of algorithms and infrastructures, and heterogeneity in data sets, models, and resources. Due to intensive synchronization of models and sharing of data across GPUs and computing nodes during distributed training and inference processes, communication efficiency becomes the bottleneck for achieving high performance at a large scale. This article surveys the literature over the period of 2018-2023 on algorithms and technologies aimed at achieving efficient communication in large-scale distributed deep learning at various levels, including algorithms, frameworks, and infrastructures. Specifically, we first introduce efficient algorithms for model synchronization and communication data compression in the context of large-scale distributed training. Next, we introduce efficient strategies related to resource allocation and task scheduling for use in distributed training and inference. After that, we present the latest technologies pertaining to modern communication infrastructures used in distributed deep learning with a focus on examining the impact of the communication overhead in a large-scale and heterogeneous setting. Finally, we conduct a case study on the distributed training of large language models at a large scale to illustrate how to apply these technologies in real cases. This article aims to offer researchers a comprehensive understanding of the current landscape of large-scale distributed deep learning and to reveal promising future research directions toward communication-efficient solutions in this scope.
4/10/2024
👁️
Scheduling of Distributed Applications on the Computing Continuum: A Survey
Narges Mehran, Dragi Kimovski, Hermann Hellwagner, Dumitru Roman, Ahmet Soylu, Radu Prodan
0
0
The demand for distributed applications has significantly increased over the past decade, with improvements in machine learning techniques fueling this growth. These applications predominantly utilize Cloud data centers for high-performance computing and Fog and Edge devices for low-latency communication for small-size machine learning model training and inference. The challenge of executing applications with different requirements on heterogeneous devices requires effective methods for solving NP-hard resource allocation and application scheduling problems. The state-of-the-art techniques primarily investigate conflicting objectives, such as the completion time, energy consumption, and economic cost of application execution on the Cloud, Fog, and Edge computing infrastructure. Therefore, in this work, we review these research works considering their objectives, methods, and evaluation tools. Based on the review, we provide a discussion on the scheduling methods in the Computing Continuum.
5/2/2024

Learning Interpretable Scheduling Algorithms for Data Processing Clusters
Zhibo Hu (Hye-Young), Chen Wang (Hye-Young), Helen (Hye-Young), Paik, Yanfeng Shu, Liming Zhu
0
0
Workloads in data processing clusters are often represented in the form of DAG (Directed Acyclic Graph) jobs. Scheduling DAG jobs is challenging. Simple heuristic scheduling algorithms are often adopted in practice in production data centres. There is much room for scheduling performance optimisation for cost saving. Recently, reinforcement learning approaches (like decima) have been attempted to optimise DAG job scheduling and demonstrate clear performance gain in comparison to traditional algorithms. However, reinforcement learning (RL) approaches face their own problems in real-world deployment. In particular, their black-box decision making processes and generalizability in unseen workloads may add a non-trivial burden to the cluster administrators. Moreover, adapting RL models on unseen workloads often requires significant amount of training data, which leaves edge cases run in a sub-optimal mode. To fill the gap, we propose a new method to distill a simple scheduling policy based on observations of the behaviours of a complex deep learning model. The simple model not only provides interpretability of scheduling decisions, but also adaptive to edge cases easily through tuning. We show that our method achieves high fidelity to the decisions made by deep learning models and outperforms these models when additional heuristics are taken into account.
5/30/2024
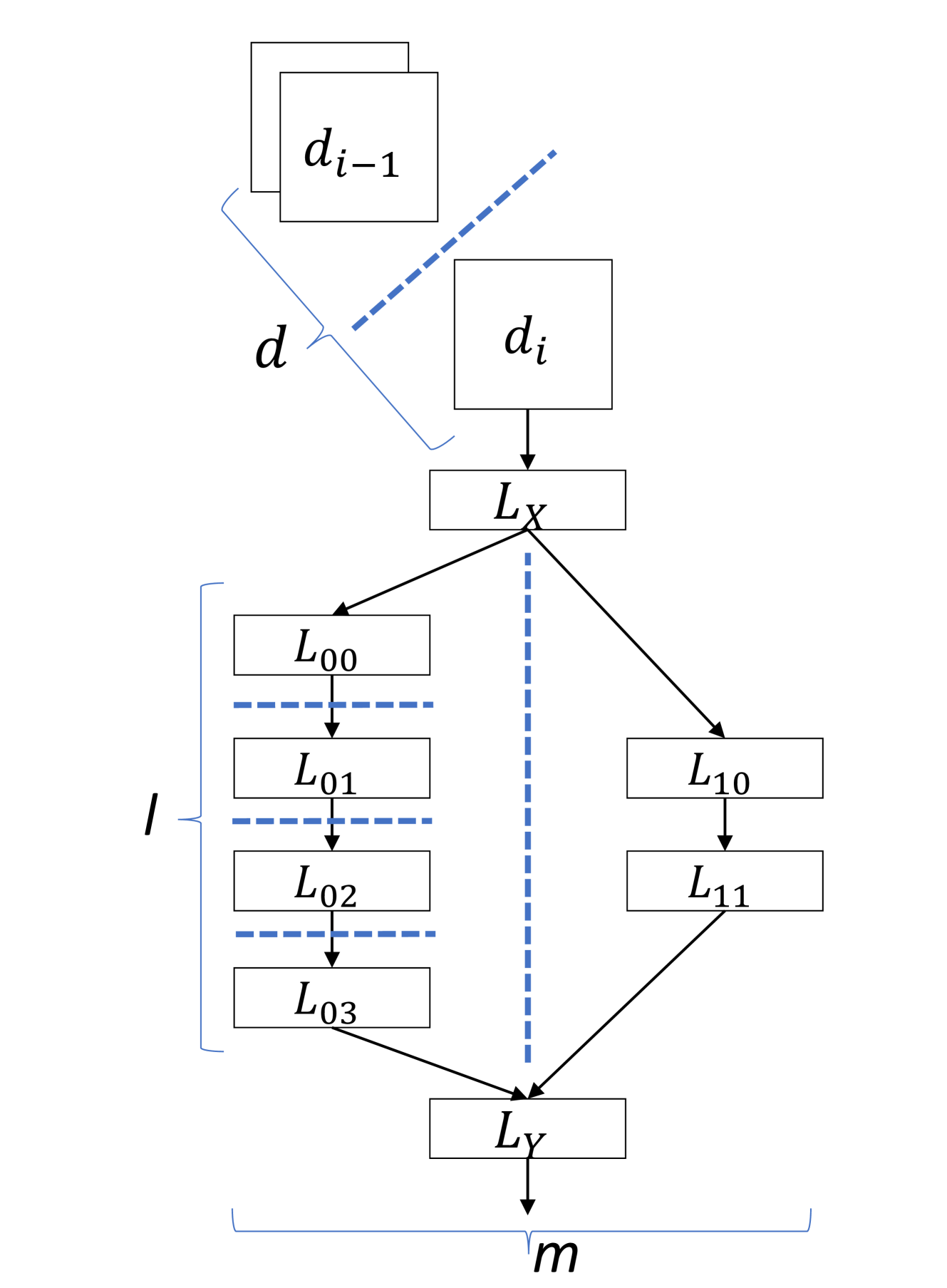
A Survey of Distributed Learning in Cloud, Mobile, and Edge Settings
Madison Threadgill, Andreas Gerstlauer
0
0
In the era of deep learning (DL), convolutional neural networks (CNNs), and large language models (LLMs), machine learning (ML) models are becoming increasingly complex, demanding significant computational resources for both inference and training stages. To address this challenge, distributed learning has emerged as a crucial approach, employing parallelization across various devices and environments. This survey explores the landscape of distributed learning, encompassing cloud and edge settings. We delve into the core concepts of data and model parallelism, examining how models are partitioned across different dimensions and layers to optimize resource utilization and performance. We analyze various partitioning schemes for different layer types, including fully connected, convolutional, and recurrent layers, highlighting the trade-offs between computational efficiency, communication overhead, and memory constraints. This survey provides valuable insights for future research and development in this rapidly evolving field by comparing and contrasting distributed learning approaches across diverse contexts.
5/27/2024