Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
2406.14288
0
0
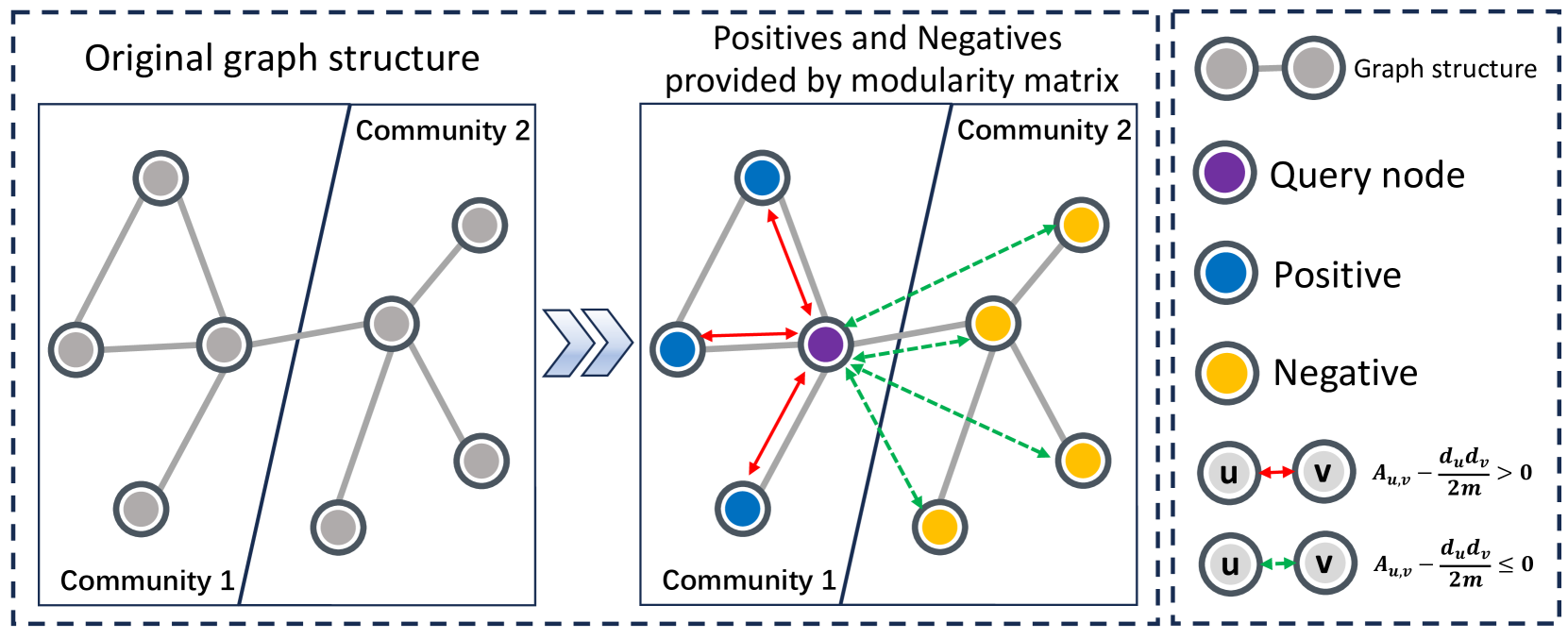
Abstract
Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.
Create account to get full access
Overview
- This paper revisits the problem of graph clustering, particularly the approach of modularity maximization.
- The authors propose a new perspective on modularity maximization by framing it as a contrastive learning task.
- They introduce a novel graph contrastive learning method called ClusterCL that aims to learn cluster-invariant node representations.
Plain English Explanation
In this paper, the researchers are looking at the problem of graph clustering, which is the task of dividing the nodes in a graph (such as a social network or a transportation network) into groups or "clusters" that have dense connections within them and sparser connections between them. One common approach to this is called "modularity maximization," which tries to find the clustering that maximizes a metric called modularity.
The researchers propose a new way of thinking about modularity maximization, by framing it as a type of "contrastive learning." Contrastive learning is a machine learning technique where the model tries to learn representations (or encodings) of data points that are similar for data points that are "positive" examples (i.e., belong to the same class or cluster), and different for "negative" examples (i.e., belong to different classes or clusters).
The researchers develop a new contrastive learning method called "ClusterCL" that aims to learn node representations that are "cluster-invariant" - meaning the representations of nodes in the same cluster should be similar, even if the overall structure of the graph changes. This can help the model generalize better to new graphs with different structures.
Technical Explanation
The key contribution of this paper is to reframe the graph clustering problem as a graph contrastive learning task. Specifically, the authors propose a novel method called ClusterCL that learns cluster-invariant node representations by contrasting nodes within the same cluster against those in different clusters.
The ClusterCL objective consists of two terms: 1) a modularity maximization term that encourages the model to discover clusters with high internal connectivity, and 2) a contrastive term that pulls representations of nodes in the same cluster closer together while pushing representations of nodes in different clusters apart. This contrastive term is key, as it allows the model to learn representations that are robust to changes in the graph structure.
The authors evaluate ClusterCL on several benchmark graph clustering datasets and show that it outperforms state-of-the-art modularity maximization and graph clustering methods. They also demonstrate the cluster-invariance property of the learned representations through experiments on graph contrastive learning tasks.
Critical Analysis
The main strength of this work is its novel perspective on modularity maximization, reframing it as a contrastive learning problem. This allows the model to learn more robust and generalizable node representations, as evidenced by the strong performance on graph clustering and contrastive learning tasks.
However, the paper does not deeply explore the theoretical connections between modularity maximization and contrastive learning. It would be interesting to see a more rigorous analysis of how the ClusterCL objective relates to and builds upon existing modularity maximization techniques.
Additionally, the paper only evaluates ClusterCL on relatively small and static graph datasets. It would be valuable to assess the method's performance on larger, dynamic graphs that are more representative of real-world networks. This could uncover potential scalability or adaptability issues that were not evident in the current experiments.
Finally, the authors do not provide much insight into the computational complexity or training efficiency of ClusterCL compared to other graph clustering approaches. This information would be helpful for practitioners considering the practical deployment of such methods.
Conclusion
This paper presents a fresh take on the graph clustering problem by casting modularity maximization as a contrastive learning task. The proposed ClusterCL method learns cluster-invariant node representations, which allows it to outperform state-of-the-art graph clustering techniques on several benchmark datasets.
While the theoretical grounding and practical considerations of the approach could be explored further, this work demonstrates the benefits of incorporating contrastive learning principles into traditional graph clustering algorithms. As the field of graph contrastive learning continues to evolve, this paper serves as an interesting example of how these techniques can be applied to long-standing problems in graph analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Community-Invariant Graph Contrastive Learning
Shiyin Tan, Dongyuan Li, Renhe Jiang, Ying Zhang, Manabu Okumura
0
0
Graph augmentation has received great attention in recent years for graph contrastive learning (GCL) to learn well-generalized node/graph representations. However, mainstream GCL methods often favor randomly disrupting graphs for augmentation, which shows limited generalization and inevitably leads to the corruption of high-level graph information, i.e., the graph community. Moreover, current knowledge-based graph augmentation methods can only focus on either topology or node features, causing the model to lack robustness against various types of noise. To address these limitations, this research investigated the role of the graph community in graph augmentation and figured out its crucial advantage for learnable graph augmentation. Based on our observations, we propose a community-invariant GCL framework to maintain graph community structure during learnable graph augmentation. By maximizing the spectral changes, this framework unifies the constraints of both topology and feature augmentation, enhancing the model's robustness. Empirical evidence on 21 benchmark datasets demonstrates the exclusive merits of our framework. Code is released on Github (https://github.com/ShiyinTan/CI-GCL.git).
5/3/2024

Dual-perspective Cross Contrastive Learning in Graph Transformers
Zelin Yao, Chuang Liu, Xueqi Ma, Mukun Chen, Jia Wu, Xiantao Cai, Bo Du, Wenbin Hu
0
0
Graph contrastive learning (GCL) is a popular method for leaning graph representations by maximizing the consistency of features across augmented views. Traditional GCL methods utilize single-perspective i.e. data or model-perspective) augmentation to generate positive samples, restraining the diversity of positive samples. In addition, these positive samples may be unreliable due to uncontrollable augmentation strategies that potentially alter the semantic information. To address these challenges, this paper proposed a innovative framework termed dual-perspective cross graph contrastive learning (DC-GCL), which incorporates three modifications designed to enhance positive sample diversity and reliability: 1) We propose dual-perspective augmentation strategy that provide the model with more diverse training data, enabling the model effective learning of feature consistency across different views. 2) From the data perspective, we slightly perturb the original graphs using controllable data augmentation, effectively preserving their semantic information. 3) From the model perspective, we enhance the encoder by utilizing more powerful graph transformers instead of graph neural networks. Based on the model's architecture, we propose three pruning-based strategies to slightly perturb the encoder, providing more reliable positive samples. These modifications collectively form the DC-GCL's foundation and provide more diverse and reliable training inputs, offering significant improvements over traditional GCL methods. Extensive experiments on various benchmarks demonstrate that DC-GCL consistently outperforms different baselines on various datasets and tasks.
6/4/2024
➖
Towards Graph Contrastive Learning: A Survey and Beyond
Wei Ju, Yifan Wang, Yifang Qin, Zhengyang Mao, Zhiping Xiao, Junyu Luo, Junwei Yang, Yiyang Gu, Dongjie Wang, Qingqing Long, Siyu Yi, Xiao Luo, Ming Zhang
0
0
In recent years, deep learning on graphs has achieved remarkable success in various domains. However, the reliance on annotated graph data remains a significant bottleneck due to its prohibitive cost and time-intensive nature. To address this challenge, self-supervised learning (SSL) on graphs has gained increasing attention and has made significant progress. SSL enables machine learning models to produce informative representations from unlabeled graph data, reducing the reliance on expensive labeled data. While SSL on graphs has witnessed widespread adoption, one critical component, Graph Contrastive Learning (GCL), has not been thoroughly investigated in the existing literature. Thus, this survey aims to fill this gap by offering a dedicated survey on GCL. We provide a comprehensive overview of the fundamental principles of GCL, including data augmentation strategies, contrastive modes, and contrastive optimization objectives. Furthermore, we explore the extensions of GCL to other aspects of data-efficient graph learning, such as weakly supervised learning, transfer learning, and related scenarios. We also discuss practical applications spanning domains such as drug discovery, genomics analysis, recommender systems, and finally outline the challenges and potential future directions in this field.
5/21/2024
🏋️
Provable Training for Graph Contrastive Learning
Yue Yu, Xiao Wang, Mengmei Zhang, Nian Liu, Chuan Shi
0
0
Graph Contrastive Learning (GCL) has emerged as a popular training approach for learning node embeddings from augmented graphs without labels. Despite the key principle that maximizing the similarity between positive node pairs while minimizing it between negative node pairs is well established, some fundamental problems are still unclear. Considering the complex graph structure, are some nodes consistently well-trained and following this principle even with different graph augmentations? Or are there some nodes more likely to be untrained across graph augmentations and violate the principle? How to distinguish these nodes and further guide the training of GCL? To answer these questions, we first present experimental evidence showing that the training of GCL is indeed imbalanced across all nodes. To address this problem, we propose the metric node compactness, which is the lower bound of how a node follows the GCL principle related to the range of augmentations. We further derive the form of node compactness theoretically through bound propagation, which can be integrated into binary cross-entropy as a regularization. To this end, we propose the PrOvable Training (POT) for GCL, which regularizes the training of GCL to encode node embeddings that follows the GCL principle better. Through extensive experiments on various benchmarks, POT consistently improves the existing GCL approaches, serving as a friendly plugin.
5/27/2024