Roadmaps with Gaps over Controllers: Achieving Efficiency in Planning under Dynamics

0

Sign in to get full access
Introduction
The paper discusses kinodynamic motion planning for mobile robots navigating environments with obstacles or challenging terrain. Tree sampling-based kinodynamic planners, which forward propagate the system's dynamics without requiring a local steering function, are a promising approach. Recent variants of these planners provide asymptotic optimality by propagating randomly sampled controls at each iteration. However, using random controls can result in slow convergence to high-quality solutions in practice.
The authors propose using Deep Reinforcement Learning (DRL) to improve the efficiency of kinodynamic motion planners. DRL can learn a local controller that approximately steers the robot between two states without collision, which can then be integrated into planners like Probabilistic Roadmaps (PRM) or Rapidly-exploring Random Trees (RRT). Unlike some supervised learning alternatives, DRL is applicable in kinodynamic motion planning but suffers from large training data requirements and requires proper tuning of reward parameters. Most current DRL solutions also lack long-horizon planning capabilities, necessitating the use of a planner for global state space search.
Recent works have leveraged DRL to build abstract representations of the planning problem and search for optimal paths between the start and goal on these representations. Methods such as Search on the Replay Buffer (SoRB), Sparse Graphical Memory (SGM), and Deep Skill Graphs build graph representations where nodes correspond to states or subgoals, and edges represent control policies between them. A common feature of these methods is that the control policy is trained in the planning environment of interest, which requires the learning algorithm to reason about both the system's dynamics and the obstacles present in the environment, making it challenging for second-order systems.
The paper presents a novel approach for integrating deep reinforcement learning (DRL) into kinodynamic motion planning. Previous methods train a controller offline in an empty environment, focusing only on the system's dynamics, and manually engineer local goals to guide the online planning process. However, designing informed local goals requires manual effort and may not generalize well across environments.
The proposed method introduces a data structure called a Roadmap with Gaps, which learns the approximate reachability of local regions in a given environment using a trained controller. The approach constructs a directed graph in the robot's free configuration space, with edges connecting source nodes to target nodes when the controller can reach the target node's termination set from the source node's nominal state without collisions. Gaps in the roadmap arise due to the imperfect connections made by the learned controller.
For new planning problems in the same environment, a wavefront expressing the cost-to-goal on the roadmap provides each node with the direction of motion towards the goal. This roadmap guidance is integrated with an AO tree sampling-based planner, which selects the accessible neighboring roadmap node with the lowest cost towards the global goal as the expansion target.
The proposed method is informed about the reachability properties of the learned controller and maintains the AO property of the overall framework. The evaluation considers various environments, including physically simulated mobile robots on uneven and varying friction terrains and a quadrotor under air pressure effects. The results show that the proposed framework finds lower-cost solutions faster than traditional random propagation methods when combined with an AO sampling-based kinodynamic planner.
Preliminaries
The paper considers a robotic system with a state space divided into collision-free and obstacle subsets. The robot's motions are governed by dynamics over the collision-free subset. A mapping function relates the state space to the configuration space. The inverse mapping returns a state by setting the dynamics term to a nominal value. A distance function is defined over the configuration space. A motion plan is a sequence of piecewise-constant controls that induce a feasible trajectory from a start state to a goal set. The goal set is defined using the distance function and a threshold. A heuristic function estimates the cost-to-go from a state to the goal region.
The paper presents a sampling-based motion planning framework that incrementally constructs a tree of states rooted at the initial state until reaching the goal set. The framework selects a tree node to expand, generates a control sequence, and propagates it to obtain a new state. The resulting edge is added to the tree if collision-free. The specific variant adopted is the "Dominance-Informed Region Tree" (DIRT), which uses an admissible state heuristic function for informed node selection and propagates a "blossom" of multiple controls at each iteration, prioritizing the edge that brings the robot closer to the goal.

Proposed Method
The paper focuses on generating control inputs to expand a tree-based motion planner out of a selected node towards a goal. It computes a local goal and uses a learned controller to generate controls that progress towards the local goal while ignoring obstacles.
The method has three main stages:
- Offline, a goal-conditioned controller is trained in an empty environment using reinforcement learning to reach goal sets.
- Offline, given a new planning environment, a directed graph roadmap is constructed. Edges in the graph represent that the controller can generate collision-free trajectories between the corresponding configurations.
- Online, given a new start and goal, the roadmap guides expansion of a tree-based planner. When a node is selected for the first time, a local goal is provided to the controller based on the roadmap. The controller generates controls to expand towards this local goal.
The roadmap introduces gaps because edges only require the final state to be in the goal set of the target node, not exactly at the node itself. This motivates using the roadmap to guide a tree search rather than directly as a plan.
The Roadmap-Guided Expansion (RoGuE) procedure uses a wavefront computed over the roadmap to select informed local goals for the controller when a tree node is expanded for the first time. On subsequent expansions, random controls are used to maintain asymptotic optimality.
V Experimental Evaluation
The paper evaluates four different vehicle systems: analytically simulated second-order differential-drive and car-like vehicles with a state space dimension of 5 and control input dimension of 2, a MuSHR car simulated using MuJoCo with a state space dimension of 27 and control input dimension of 2, and a Skydio X2 Autonomous Drone with a state space dimension of 13 and control input dimension of 4. For the drone, the distance function operates over the (x, y, z) coordinates of its center of mass. All systems use an epsilon value of 0.5.

The evaluation pairs of start and goal configurations are incorporated as milestones during the roadmap construction phase to reduce online planning time. Connecting the start and goal configurations to the roadmap can be done using multi-threaded implementations. The planning experiments use the ML4KP library and run on a cluster with an Intel Xeon Gold 5220 CPU at 2.20GHz and 512 GB of RAM.
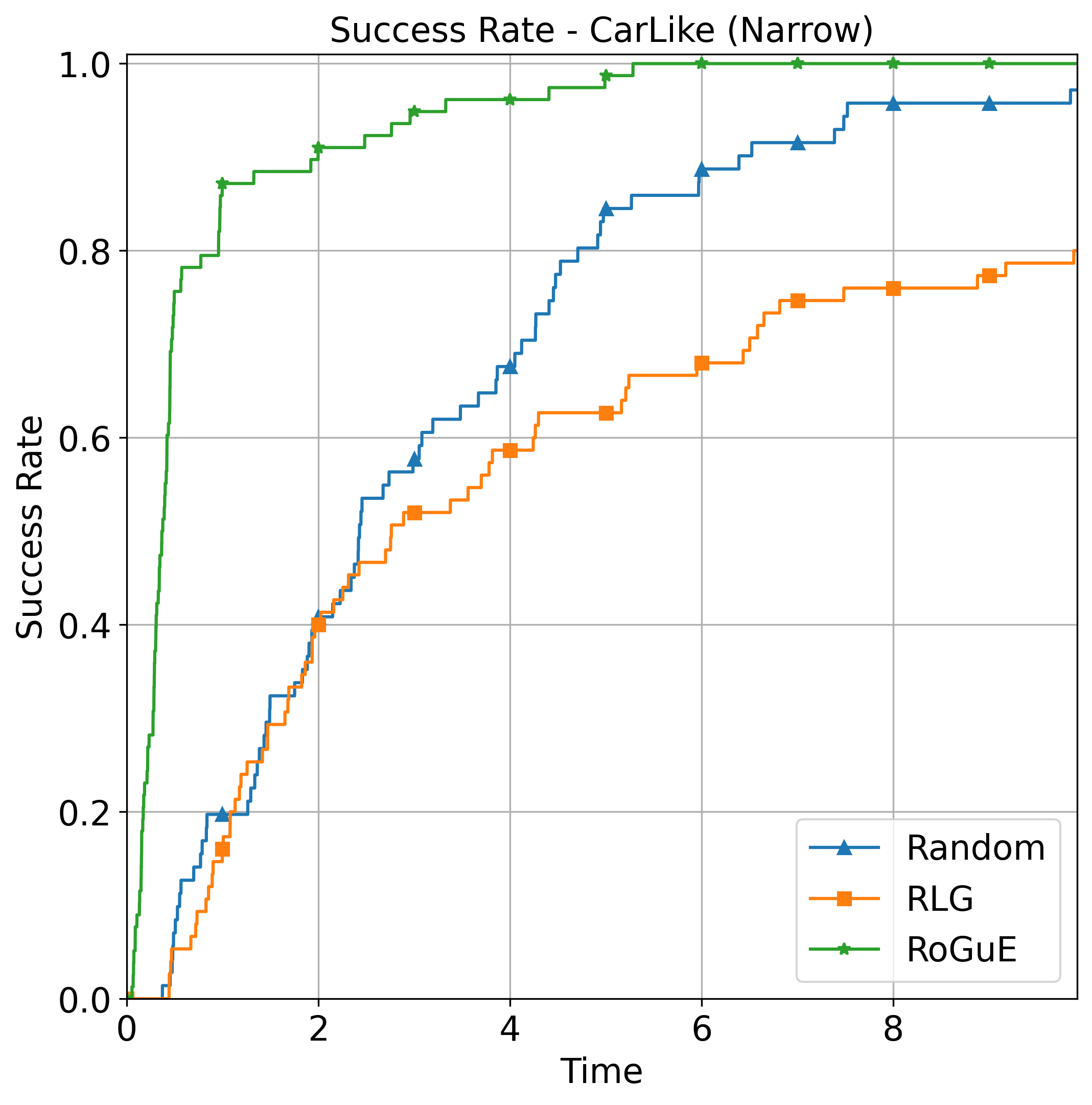
The paper evaluates the performance of the RoGuE expansion strategy compared to Random and RLG strategies on various planning benchmarks for analytically and physically simulated vehicular systems. RoGuE augments each tree node with a "roadmap cost-to-go" value and reselects nodes for expansion when their state heuristic or roadmap cost-to-go value is lower than their parent's.
In the analytically simulated benchmarks (Narrow passages, Indoor, and Warehouse environments), RoGuE finds the lowest cost solutions overall and is the only strategy that returns solutions in all trials. Random and RLG struggle to find solutions in all trials for the Indoor and Warehouse benchmarks.
For the physically simulated benchmarks using MuSHR (Maze, Terrain, and Friction environments) and a Quadrotor, RoGuE finds the lowest cost solutions successfully. Random and RLG fail to find solutions in all trials, although RLG's learned controller improves solution quality. RoGuE leverages the pre-computed roadmap to guide the planner efficiently.
Ablation studies show that planners using larger roadmaps (Baseline and Denser) find competitive solutions quickly, while a Sparser roadmap underperforms. Increasing the maximum allowed edge cost (Tmax) slightly increases the time taken by the planner to find solutions without significantly affecting the solution cost.
Conclusion
The paper proposes a strategy to improve the efficiency of kinodynamic planning for robots with significant dynamics by leveraging learned controllers. The target environment is represented using a "Roadmap with Gaps" over local regions and controller applications between them. A tree sampling-based motion planner generates informed subgoals based on a wavefront over the roadmap for a specific goal and uses the controller to reach them, resorting to random exploration when the controller fails. Experiments demonstrate significant improvement in planning efficiency. The memory requirements of the roadmap can be improved using sparse representations for higher-dimensional systems, and learned reachability estimators can assist in efficient roadmap construction and online queries. The approach assumes a perfect model of the vehicular dynamics, which complicates direct deployment on real vehicular systems and motivates integrating the motion planner with feedback control for accurate trajectory tracking. The methodology may suffer when the gaps due to the dynamics are too large, and introducing effort bias in the motion planner can help explore alternative paths quickly but may lack theoretical guarantees.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!