RobustSAM: Segment Anything Robustly on Degraded Images
2406.09627
0
0

Abstract
Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization. Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
Create account to get full access
Overview
- This paper introduces RobustSAM, a new model for robustly segmenting objects in degraded images.
- RobustSAM is an extension of the popular Segment Anything Model (SAM), which can segment any object in an image based on a text prompt or a click.
- The key innovation of RobustSAM is its ability to handle image degradation, such as noise, blur, and compression artifacts, which can significantly impact the performance of standard segmentation models.
Plain English Explanation
The Segment Anything Model (SAM) is a powerful AI system that can identify and outline any object in an image based on a simple text description or by clicking on the object. However, this model can struggle when the image is of poor quality, such as being blurry, noisy, or compressed.
The researchers behind RobustSAM have developed a new version of this model that is much better at handling degraded images. By incorporating specialized training techniques and architectural changes, RobustSAM is able to maintain accurate segmentation even on images with significant visual impairments. This is an important advancement, as many real-world applications of image segmentation, like autonomous driving or medical imaging, often have to deal with less-than-perfect image quality.
The key idea behind RobustSAM is to make the model more resilient to common image degradation factors. Rather than just training on clean, high-quality images, the researchers also expose the model to a diverse range of degraded images during training. This teaches RobustSAM to recognize objects and their boundaries even when the visual information is obscured or distorted.
Additionally, the RobustSAM architecture includes special components designed to enhance robustness, such as attention mechanisms that focus on the most informative image regions. By combining these technical innovations, the researchers were able to create a segmentation model that outperforms standard SAM on a variety of degraded image benchmarks.
Technical Explanation
The core of RobustSAM is an extension of the Segment Anything Model (SAM), a state-of-the-art general-purpose segmentation model. RobustSAM builds on SAM's architecture, which uses a vision transformer backbone and a specialized segmentation head, but introduces several key modifications to improve robustness to image degradation.
First, the researchers augment the training data by applying a wide range of degradation techniques, such as noise, blur, and compression, to the original images. This exposes the model to a diverse set of visual distortions during the training process, allowing it to learn more robust visual representations.
Second, RobustSAM incorporates a novel attention mechanism that dynamically focuses on the most informative regions of the input image. This helps the model overcome the challenges posed by degraded visual information, as it can rely more heavily on the few reliable cues available in the image.
The researchers also explore architectural changes, such as adding skip connections and modifying the transformer layers, to further enhance the model's ability to segment objects in degraded images. These modifications are designed to improve the flow of information through the network and enable better integration of low-level visual features.
Extensive experiments on various degraded image benchmarks, including FoCSAM, Zero-Shot Segmentation, and SimSAM, demonstrate the superior performance of RobustSAM compared to the original SAM model and other state-of-the-art approaches. The results highlight the effectiveness of the proposed techniques in enabling robust segmentation on a wide range of image degradation scenarios.
Critical Analysis
The RobustSAM paper presents a compelling solution to an important problem in the field of image segmentation. By addressing the challenge of degraded image quality, the researchers have developed a model that can maintain accurate object segmentation in real-world conditions, where image data is often noisy or distorted.
One potential limitation of the RobustSAM approach is the reliance on a diverse set of degradation techniques during training. While this strategy has proven effective, it may not capture the full range of real-world image degradation factors, and the model's performance may still be limited in certain edge cases. Further research could explore more comprehensive data augmentation strategies or the integration of dedicated degradation modeling components.
Additionally, the paper does not provide a detailed analysis of the computational complexity or inference speed of RobustSAM compared to the original SAM model. As practical applications often require efficient and low-latency inference, a more thorough evaluation of the model's efficiency would be valuable for understanding its suitability for deployment in real-world scenarios.
Despite these minor caveats, the RobustSAM paper represents a significant advancement in the field of robust image segmentation. By addressing the critical issue of degraded image quality, the researchers have opened up new possibilities for the application of segmentation models in a wide range of domains, from autonomous driving to medical imaging and beyond.
Conclusion
The RobustSAM paper introduces an innovative extension to the popular Segment Anything Model (SAM), which enables robust object segmentation on degraded images. By incorporating specialized training techniques and architectural modifications, the researchers have developed a model that can maintain accurate segmentation even in the presence of significant visual impairments, such as noise, blur, and compression artifacts.
The key contribution of RobustSAM is its ability to generalize beyond the clean, high-quality images typically used to train image segmentation models. By exposing the model to a diverse range of degraded images during training, RobustSAM learns to recognize and segment objects based on more resilient visual cues, making it well-suited for real-world applications where image quality is often suboptimal.
The successful evaluation of RobustSAM on various degraded image benchmarks, including FoCSAM, Zero-Shot Segmentation, and SimSAM, highlights the practical significance of this research. By addressing the challenge of degraded image quality, the RobustSAM model opens up new avenues for the deployment of advanced segmentation techniques in a wide range of domains, from autonomous driving to medical imaging and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Zero-Shot Segmentation of Eye Features Using the Segment Anything Model (SAM)
Virmarie Maquiling, Sean Anthony Byrne, Diederick C. Niehorster, Marcus Nystrom, Enkelejda Kasneci
0
0
The advent of foundation models signals a new era in artificial intelligence. The Segment Anything Model (SAM) is the first foundation model for image segmentation. In this study, we evaluate SAM's ability to segment features from eye images recorded in virtual reality setups. The increasing requirement for annotated eye-image datasets presents a significant opportunity for SAM to redefine the landscape of data annotation in gaze estimation. Our investigation centers on SAM's zero-shot learning abilities and the effectiveness of prompts like bounding boxes or point clicks. Our results are consistent with studies in other domains, demonstrating that SAM's segmentation effectiveness can be on-par with specialized models depending on the feature, with prompts improving its performance, evidenced by an IoU of 93.34% for pupil segmentation in one dataset. Foundation models like SAM could revolutionize gaze estimation by enabling quick and easy image segmentation, reducing reliance on specialized models and extensive manual annotation.
4/9/2024
SimSAM: Zero-shot Medical Image Segmentation via Simulated Interaction
Benjamin Towle, Xin Chen, Ke Zhou
0
0
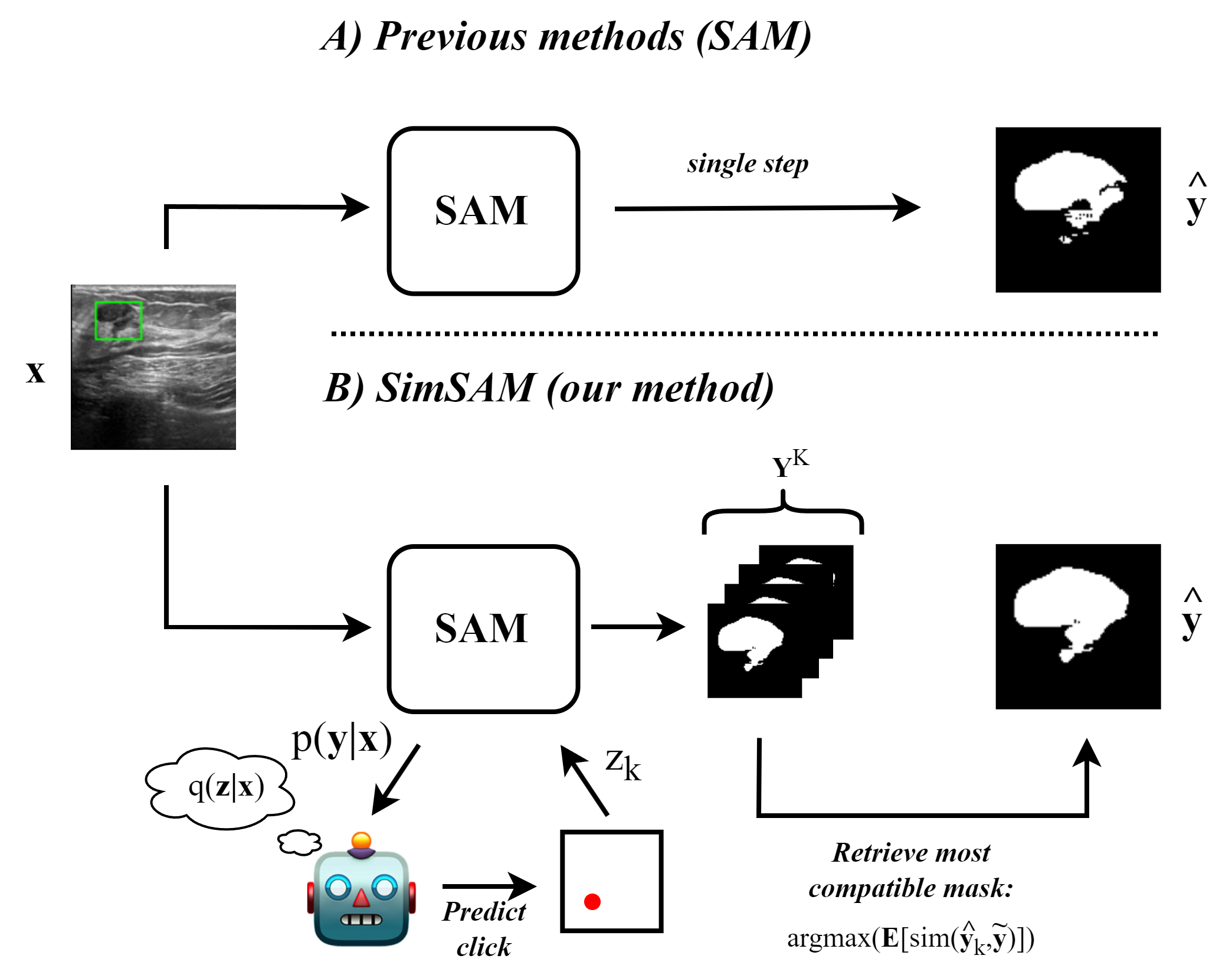
The recently released Segment Anything Model (SAM) has shown powerful zero-shot segmentation capabilities through a semi-automatic annotation setup in which the user can provide a prompt in the form of clicks or bounding boxes. There is growing interest around applying this to medical imaging, where the cost of obtaining expert annotations is high, privacy restrictions may limit sharing of patient data, and model generalisation is often poor. However, there are large amounts of inherent uncertainty in medical images, due to unclear object boundaries, low-contrast media, and differences in expert labelling style. Currently, SAM is known to struggle in a zero-shot setting to adequately annotate the contours of the structure of interest in medical images, where the uncertainty is often greatest, thus requiring significant manual correction. To mitigate this, we introduce textbf{Sim}ulated Interaction for textbf{S}egment textbf{A}nything textbf{M}odel (textsc{textbf{SimSAM}}), an approach that leverages simulated user interaction to generate an arbitrary number of candidate masks, and uses a novel aggregation approach to output the most compatible mask. Crucially, our method can be used during inference directly on top of SAM, without any additional training requirement. Quantitatively, we evaluate our method across three publicly available medical imaging datasets, and find that our approach leads to up to a 15.5% improvement in contour segmentation accuracy compared to zero-shot SAM. Our code is available at url{https://github.com/BenjaminTowle/SimSAM}.
6/4/2024

Boosting Medical Image Classification with Segmentation Foundation Model
Pengfei Gu, Zihan Zhao, Hongxiao Wang, Yaopeng Peng, Yizhe Zhang, Nishchal Sapkota, Chaoli Wang, Danny Z. Chen
0
0
The Segment Anything Model (SAM) exhibits impressive capabilities in zero-shot segmentation for natural images. Recently, SAM has gained a great deal of attention for its applications in medical image segmentation. However, to our best knowledge, no studies have shown how to harness the power of SAM for medical image classification. To fill this gap and make SAM a true ``foundation model'' for medical image analysis, it is highly desirable to customize SAM specifically for medical image classification. In this paper, we introduce SAMAug-C, an innovative augmentation method based on SAM for augmenting classification datasets by generating variants of the original images. The augmented datasets can be used to train a deep learning classification model, thereby boosting the classification performance. Furthermore, we propose a novel framework that simultaneously processes raw and SAMAug-C augmented image input, capitalizing on the complementary information that is offered by both. Experiments on three public datasets validate the effectiveness of our new approach.
6/18/2024

FocSAM: Delving Deeply into Focused Objects in Segmenting Anything
You Huang, Zongyu Lan, Liujuan Cao, Xianming Lin, Shengchuan Zhang, Guannan Jiang, Rongrong Ji
0
0
The Segment Anything Model (SAM) marks a notable milestone in segmentation models, highlighted by its robust zero-shot capabilities and ability to handle diverse prompts. SAM follows a pipeline that separates interactive segmentation into image preprocessing through a large encoder and interactive inference via a lightweight decoder, ensuring efficient real-time performance. However, SAM faces stability issues in challenging samples upon this pipeline. These issues arise from two main factors. Firstly, the image preprocessing disables SAM from dynamically using image-level zoom-in strategies to refocus on the target object during interaction. Secondly, the lightweight decoder struggles to sufficiently integrate interactive information with image embeddings. To address these two limitations, we propose FocSAM with a pipeline redesigned on two pivotal aspects. First, we propose Dynamic Window Multi-head Self-Attention (Dwin-MSA) to dynamically refocus SAM's image embeddings on the target object. Dwin-MSA localizes attention computations around the target object, enhancing object-related embeddings with minimal computational overhead. Second, we propose Pixel-wise Dynamic ReLU (P-DyReLU) to enable sufficient integration of interactive information from a few initial clicks that have significant impacts on the overall segmentation results. Experimentally, FocSAM augments SAM's interactive segmentation performance to match the existing state-of-the-art method in segmentation quality, requiring only about 5.6% of this method's inference time on CPUs.
5/30/2024