Self-Supervised Time-Series Anomaly Detection Using Learnable Data Augmentation
2406.12260
0
0

Abstract
Continuous efforts are being made to advance anomaly detection in various manufacturing processes to increase the productivity and safety of industrial sites. Deep learning replaced rule-based methods and recently emerged as a promising method for anomaly detection in diverse industries. However, in the real world, the scarcity of abnormal data and difficulties in obtaining labeled data create limitations in the training of detection models. In this study, we addressed these shortcomings by proposing a learnable data augmentation-based time-series anomaly detection (LATAD) technique that is trained in a self-supervised manner. LATAD extracts discriminative features from time-series data through contrastive learning. At the same time, learnable data augmentation produces challenging negative samples to enhance learning efficiency. We measured anomaly scores of the proposed technique based on latent feature similarities. As per the results, LATAD exhibited comparable or improved performance to the state-of-the-art anomaly detection assessments on several benchmark datasets and provided a gradient-based diagnosis technique to help identify root causes.
Create account to get full access
Overview
- This paper presents a self-supervised approach for anomaly detection in time-series data.
- The key idea is to use learnable data augmentation techniques to create diverse "positive" examples, which are then used to train a contrastive learning model to detect anomalies.
- The authors demonstrate the effectiveness of their method on various time-series benchmarks, outperforming existing self-supervised and supervised approaches.
Plain English Explanation
The paper focuses on the problem of detecting anomalies, or unusual events, in time-series data. This is an important task in many applications, such as monitoring industrial equipment, detecting healthcare issues, or identifying cyber attacks.
Traditional approaches to anomaly detection often rely on labeled data, where the model is trained to identify known types of anomalies. However, obtaining labeled data can be time-consuming and expensive, especially for rare or novel anomalies.
The researchers in this paper propose a self-supervised approach that doesn't require any labeled data. Instead, they use a technique called "data augmentation" to generate diverse "positive" examples from the normal, non-anomalous data. These positive examples are then used to train a contrastive learning model to distinguish normal data from anomalies.
The key innovation is that the data augmentation techniques are "learnable," meaning the model can automatically learn the best way to transform the data to create useful positive examples. This allows the model to adapt to the specific characteristics of the time-series data, rather than relying on pre-defined transformations.
Through experiments on various benchmark datasets, the authors show that their self-supervised approach outperforms both traditional supervised methods and other self-supervised techniques. This suggests that the learnable data augmentation is an effective way to capture the underlying patterns in time-series data and detect anomalies without the need for labeled examples.
Technical Explanation
The researchers propose a self-supervised time-series anomaly detection framework that leverages learnable data augmentation techniques. The core idea is to create diverse "positive" examples from the normal, non-anomalous data and then train a contrastive learning model to distinguish these positive examples from anomalies.
The data augmentation process is a key component of the approach. Instead of using pre-defined transformations, the authors develop a learnable data augmentation module that can automatically discover the most effective ways to transform the time-series data. This is achieved by training a generative model, such as a variational autoencoder (VAE) or a generative adversarial network (GAN), to generate plausible positive examples.
The contrastive learning model is then trained to embed the normal data and the generated positive examples into a shared latent space, where anomalies are pushed away from the normal data distribution. This self-supervised training procedure allows the model to learn robust representations of the normal data without any labeled examples.
The authors evaluate their approach, called Self-Supervised Time-Series Anomaly Detection Using Learnable Data Augmentation, on several benchmark datasets, including end-to-end-self-tuning-self-supervised, carla-self-supervised-contrastive-representation-learning-time, and reliable-framework-human-loop-anomaly-detection-time. The results show that their method outperforms both supervised and other self-supervised approaches, demonstrating the effectiveness of the learnable data augmentation technique.
Critical Analysis
The paper presents a solid and well-designed approach for self-supervised time-series anomaly detection. The use of learnable data augmentation is a clever idea that allows the model to adapt to the specific characteristics of the data, rather than relying on pre-defined transformations.
However, the authors do acknowledge some limitations of their work. For example, the performance of the method may depend on the quality of the generative model used for data augmentation. If the generated positive examples do not capture the essential features of the normal data, the contrastive learning model may not learn effective representations.
Additionally, the paper does not explore the interpretability of the learned representations or the ability to identify the root causes of anomalies. This could be an important consideration for real-world applications, where understanding the underlying reasons for anomalies is crucial.
Future research could also investigate the robustness of the method to different types of anomalies, such as large-language-models-can-deliver-accurate-interpretable or deep-positive-unlabeled-anomaly-detection-contaminated-unlabeled anomalies, which may require different data augmentation strategies.
Conclusion
This paper presents a novel self-supervised approach for time-series anomaly detection that uses learnable data augmentation techniques to train a contrastive learning model. The key innovation is the ability to automatically discover the most effective ways to transform the data and create diverse positive examples, which enables the model to learn robust representations of the normal data without any labeled examples.
The authors demonstrate the effectiveness of their method on various benchmarks, outperforming both supervised and other self-supervised approaches. This suggests that the learnable data augmentation technique is a promising direction for tackling the challenging problem of anomaly detection in time-series data, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

End-To-End Self-tuning Self-supervised Time Series Anomaly Detection
Boje Deforce, Meng-Chieh Lee, Bart Baesens, Estefan'ia Serral Asensio, Jaemin Yoo, Leman Akoglu
0
0
Time series anomaly detection (TSAD) finds many applications such as monitoring environmental sensors, industry KPIs, patient biomarkers, etc. A two-fold challenge for TSAD is a versatile and unsupervised model that can detect various different types of time series anomalies (spikes, discontinuities, trend shifts, etc.) without any labeled data. Modern neural networks have outstanding ability in modeling complex time series. Self-supervised models in particular tackle unsupervised TSAD by transforming the input via various augmentations to create pseudo anomalies for training. However, their performance is sensitive to the choice of augmentation, which is hard to choose in practice, while there exists no effort in the literature on data augmentation tuning for TSAD without labels. Our work aims to fill this gap. We introduce TSAP for TSA on autoPilot, which can (self-)tune augmentation hyperparameters end-to-end. It stands on two key components: a differentiable augmentation architecture and an unsupervised validation loss to effectively assess the alignment between augmentation type and anomaly type. Case studies show TSAP's ability to effectively select the (discrete) augmentation type and associated (continuous) hyperparameters. In turn, it outperforms established baselines, including SOTA self-supervised models, on diverse TSAD tasks exhibiting different anomaly types.
4/4/2024
❗
CARLA: Self-supervised Contrastive Representation Learning for Time Series Anomaly Detection
Zahra Zamanzadeh Darban, Geoffrey I. Webb, Shirui Pan, Charu C. Aggarwal, Mahsa Salehi
0
0
One main challenge in time series anomaly detection (TSAD) is the lack of labelled data in many real-life scenarios. Most of the existing anomaly detection methods focus on learning the normal behaviour of unlabelled time series in an unsupervised manner. The normal boundary is often defined tightly, resulting in slight deviations being classified as anomalies, consequently leading to a high false positive rate and a limited ability to generalise normal patterns. To address this, we introduce a novel end-to-end self-supervised ContrAstive Representation Learning approach for time series Anomaly detection (CARLA). While existing contrastive learning methods assume that augmented time series windows are positive samples and temporally distant windows are negative samples, we argue that these assumptions are limited as augmentation of time series can transform them to negative samples, and a temporally distant window can represent a positive sample. Our contrastive approach leverages existing generic knowledge about time series anomalies and injects various types of anomalies as negative samples. Therefore, CARLA not only learns normal behaviour but also learns deviations indicating anomalies. It creates similar representations for temporally closed windows and distinct ones for anomalies. Additionally, it leverages the information about representations' neighbours through a self-supervised approach to classify windows based on their nearest/furthest neighbours to further enhance the performance of anomaly detection. In extensive tests on seven major real-world time series anomaly detection datasets, CARLA shows superior performance over state-of-the-art self-supervised and unsupervised TSAD methods. Our research shows the potential of contrastive representation learning to advance time series anomaly detection.
4/9/2024

A Reliable Framework for Human-in-the-Loop Anomaly Detection in Time Series
Ziquan Deng, Xiwei Xuan, Kwan-Liu Ma, Zhaodan Kong
0
0
Time series anomaly detection is a critical machine learning task for numerous applications, such as finance, healthcare, and industrial systems. However, even high-performed models may exhibit potential issues such as biases, leading to unreliable outcomes and misplaced confidence. While model explanation techniques, particularly visual explanations, offer valuable insights to detect such issues by elucidating model attributions of their decision, many limitations still exist -- They are primarily instance-based and not scalable across dataset, and they provide one-directional information from the model to the human side, lacking a mechanism for users to address detected issues. To fulfill these gaps, we introduce HILAD, a novel framework designed to foster a dynamic and bidirectional collaboration between humans and AI for enhancing anomaly detection models in time series. Through our visual interface, HILAD empowers domain experts to detect, interpret, and correct unexpected model behaviors at scale. Our evaluation with two time series datasets and user studies demonstrates the effectiveness of HILAD in fostering a deeper human understanding, immediate corrective actions, and the reliability enhancement of models.
5/9/2024
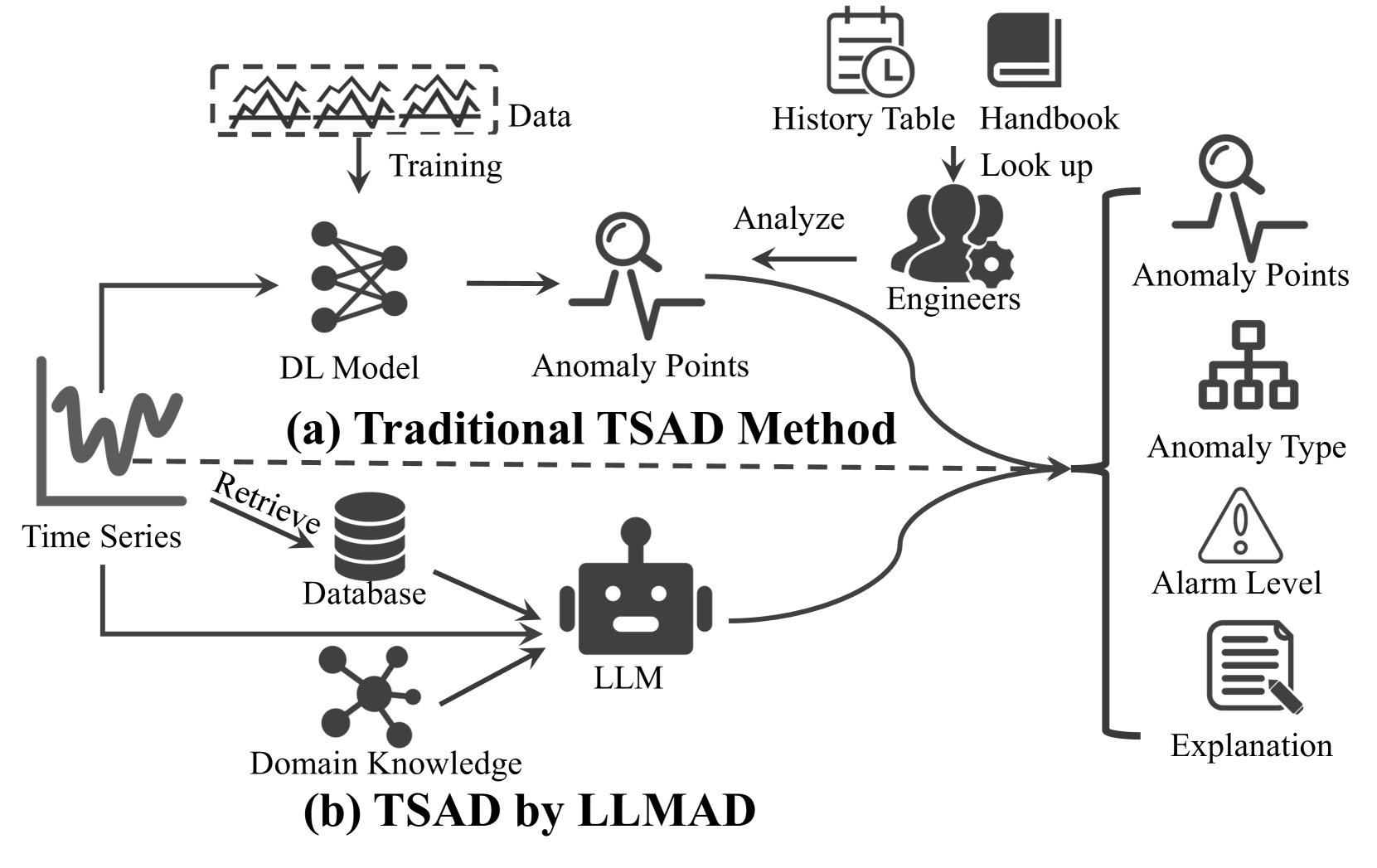
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
0
0
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
5/27/2024