SGCNeRF: Few-Shot Neural Rendering via Sparse Geometric Consistency Guidance
2404.00992
0
0
Abstract
Neural Radiance Field (NeRF) technology has made significant strides in creating novel viewpoints. However, its effectiveness is hampered when working with sparsely available views, often leading to performance dips due to overfitting. FreeNeRF attempts to overcome this limitation by integrating implicit geometry regularization, which incrementally improves both geometry and textures. Nonetheless, an initial low positional encoding bandwidth results in the exclusion of high-frequency elements. The quest for a holistic approach that simultaneously addresses overfitting and the preservation of high-frequency details remains ongoing. This study introduces a novel feature matching based sparse geometry regularization module. This module excels in pinpointing high-frequency keypoints, thereby safeguarding the integrity of fine details. Through progressive refinement of geometry and textures across NeRF iterations, we unveil an effective few-shot neural rendering architecture, designated as SGCNeRF, for enhanced novel view synthesis. Our experiments demonstrate that SGCNeRF not only achieves superior geometry-consistent outcomes but also surpasses FreeNeRF, with improvements of 0.7 dB and 0.6 dB in PSNR on the LLFF and DTU datasets, respectively.
Create account to get full access
Overview
- Few-shot neural rendering: Generating high-quality images from a small number of input images
- Sparse geometric consistency guidance: Using sparse 3D point cloud information to guide the neural rendering process
- Frequency regularization: Improving the rendering quality by regularizing the frequency content of the output images
Plain English Explanation
SGCNeRF is a method that aims to generate high-quality images from a small number of input images, a task known as few-shot neural rendering. The key idea is to use sparse 3D point cloud information to guide the neural rendering process, ensuring that the generated images are consistent with the underlying 3D geometry. This is done through a technique called sparse geometric consistency guidance, which helps the neural network learn to produce images that align with the available 3D data.
Additionally, the method employs frequency regularization, which ensures that the output images have the right balance of high and low frequency content. This helps to improve the overall rendering quality and avoid artifacts.
The SGCNeRF approach is particularly useful when only a few input images are available, as it can generate realistic and consistent images without requiring a large dataset. This makes it applicable to scenarios where data collection is limited, such as in robotics, augmented reality, or medical imaging.
Technical Explanation
The SGCNeRF method consists of a neural network architecture that takes in a small number of input images and their associated 3D point cloud information. The network is trained to generate high-quality images that are consistent with the underlying 3D geometry.
The key components of the SGCNeRF architecture are:
- Feature Matching Module: This module aligns the input images with the 3D point cloud data, ensuring that the neural network can learn the correspondence between 2D and 3D information.
- Rendering Module: This module generates the final output images, leveraging the guidance provided by the 3D point cloud data and the frequency regularization technique.
The SGCNeRF method is evaluated on various few-shot rendering tasks, demonstrating its ability to generate high-quality images from a small number of input images, while maintaining consistency with the underlying 3D geometry.
Critical Analysis
The SGCNeRF method provides a promising approach to few-shot neural rendering, leveraging sparse 3D point cloud information to guide the rendering process. However, the paper notes that the method may have limitations in scenarios where the 3D point cloud data is noisy or incomplete.
Additionally, the frequency regularization technique used in SGCNeRF may not be sufficient to address all potential rendering artifacts, and further research into more advanced frequency-based regularization methods could be beneficial.
It would also be interesting to see how the SGCNeRF method compares to other few-shot neural rendering techniques, such as GEAR-NeRF or SparseGS, in terms of rendering quality, efficiency, and the ability to handle diverse scenes and data distributions.
Conclusion
The SGCNeRF method presents an effective approach to few-shot neural rendering, leveraging sparse 3D point cloud information and frequency regularization to generate high-quality images from a small number of input images. This technique has the potential to be highly useful in various applications, such as robotics, augmented reality, and medical imaging, where data collection is limited. While the method shows promising results, further research into addressing its limitations and exploring alternative approaches could lead to even more robust and versatile few-shot neural rendering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Spatial Annealing Smoothing for Efficient Few-shot Neural Rendering
Yuru Xiao, Xianming Liu, Deming Zhai, Kui Jiang, Junjun Jiang, Xiangyang Ji
0
0
Neural Radiance Fields (NeRF) with hybrid representations have shown impressive capabilities in reconstructing scenes for view synthesis, delivering high efficiency. Nonetheless, their performance significantly drops with sparse view inputs, due to the issue of overfitting. While various regularization strategies have been devised to address these challenges, they often depend on inefficient assumptions or are not compatible with hybrid models. There is a clear need for a method that maintains efficiency and improves resilience to sparse views within a hybrid framework. In this paper, we introduce an accurate and efficient few-shot neural rendering method named Spatial Annealing smoothing regularized NeRF (SANeRF), which is specifically designed for a pre-filtering-driven hybrid representation architecture. We implement an exponential reduction of the sample space size from an initially large value. This methodology is crucial for stabilizing the early stages of the training phase and significantly contributes to the enhancement of the subsequent process of detail refinement. Our extensive experiments reveal that, by adding merely one line of code, SANeRF delivers superior rendering quality and much faster reconstruction speed compared to current few-shot NeRF methods. Notably, SANeRF outperforms FreeNeRF by 0.3 dB in PSNR on the Blender dataset, while achieving 700x faster reconstruction speed.
6/13/2024
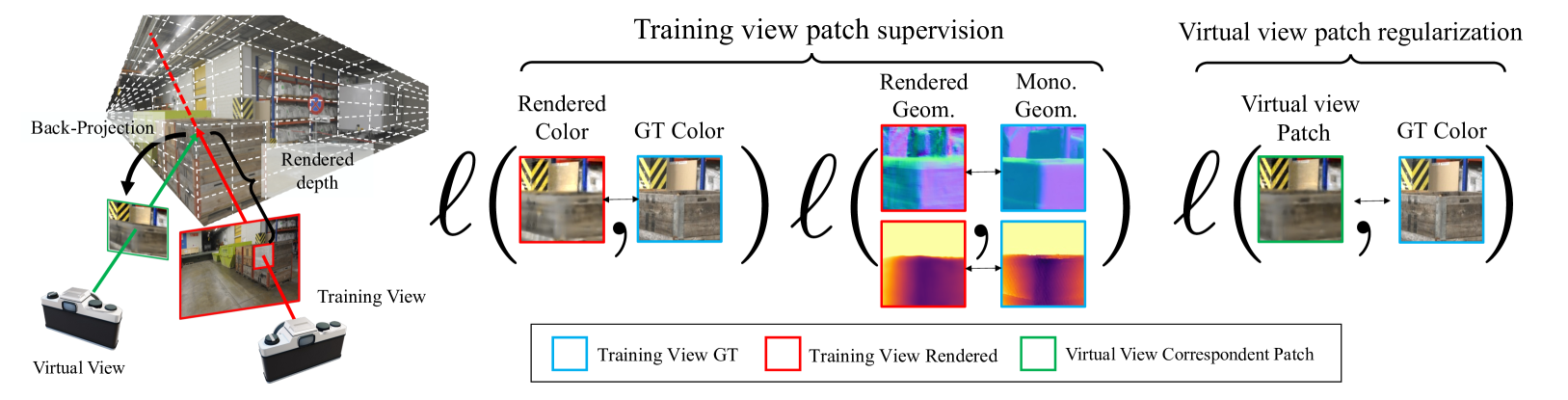
MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
Yuqun Wu, Jae Yong Lee, Chuhang Zou, Shenlong Wang, Derek Hoiem
0
0
The latest regularized Neural Radiance Field (NeRF) approaches produce poor geometry and view extrapolation for multiview stereo (MVS) benchmarks such as ETH3D. In this paper, we aim to create 3D models that provide accurate geometry and view synthesis, partially closing the large geometric performance gap between NeRF and traditional MVS methods. We propose a patch-based approach that effectively leverages monocular surface normal and relative depth predictions. The patch-based ray sampling also enables the appearance regularization of normalized cross-correlation (NCC) and structural similarity (SSIM) between randomly sampled virtual and training views. We further show that density restrictions based on sparse structure-from-motion points can help greatly improve geometric accuracy with a slight drop in novel view synthesis metrics. Our experiments show 4x the performance of RegNeRF and 8x that of FreeNeRF on average F1@2cm for ETH3D MVS benchmark, suggesting a fruitful research direction to improve the geometric accuracy of NeRF-based models, and sheds light on a potential future approach to enable NeRF-based optimization to eventually outperform traditional MVS.
4/15/2024
👁️
Simple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Nagabhushan Somraj, Sai Harsha Mupparaju, Adithyan Karanayil, Rajiv Soundararajan
0
0
Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^circ$ scenes by employing the above regularizations.
5/28/2024

Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling
Xinhang Liu, Yu-Wing Tai, Chi-Keung Tang, Pedro Miraldo, Suhas Lohit, Moitreya Chatterjee
0
0
Extensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest - a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets.
6/7/2024