Slight Corruption in Pre-training Data Makes Better Diffusion Models
2405.20494
0
0
📊
Abstract
Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs. Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs. We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over 50 conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs. Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP). CEP significantly improves the performance of various DMs in both pre-training and downstream tasks. We hope that our study provides new insights into understanding the data and pre-training processes of DMs.
Create account to get full access
Overview
- Diffusion models (DMs) have shown impressive capabilities in generating high-quality images, audios, and videos.
- DMs rely on extensive pre-training on large-scale datasets, which can sometimes include corrupted data where the conditions (e.g., image-text pairs) do not accurately describe the data.
- This paper explores the impact of such data corruption on the performance of DMs, both during pre-training and downstream adaptation.
Plain English Explanation
Diffusion models are a type of machine learning system that can generate realistic-looking images, sounds, and videos. These models are trained on large datasets of information, such as images paired with text descriptions or images labeled with categories.
However, even after careful cleaning, these datasets can sometimes contain corrupted or inaccurate information. For example, an image might be paired with a text description that doesn't accurately describe what's in the image.
This research paper investigates how this kind of data corruption affects the performance of diffusion models. The researchers synthetically introduced different types of corruption into two popular datasets (ImageNet and CC3M) and then trained over 50 diffusion models using the corrupted data.
Surprisingly, the researchers found that a little bit of corruption can actually improve the quality, diversity, and accuracy of the images generated by the diffusion models, both during the initial training and when the models are adapted to new tasks. The researchers think this is because the slight corruption adds some helpful "noise" that makes the models more robust and able to better capture the underlying patterns in the data.
Inspired by these findings, the researchers propose a simple technique called "condition embedding perturbation" that can be used to improve the training of diffusion models on real-world datasets. This technique involves intentionally adding a small amount of noise or corruption to the input conditions (like the text descriptions) during training, which can lead to better-performing models.
Overall, this research provides new insights into how the quality of training data affects the performance of diffusion models, and suggests that a little bit of controlled corruption can actually be beneficial for these powerful AI systems.
Technical Explanation
This paper presents a comprehensive study on the impact of corrupted pre-training data on the performance of diffusion models (DMs). Diffusion models have demonstrated remarkable abilities in generating realistic high-quality images, audios, and videos, but they heavily rely on extensive pre-training on large-scale datasets.
The researchers synthetically corrupted two popular datasets, ImageNet-1K and CC3M, and used the corrupted data to pre-train over 50 conditional DMs. Their empirical findings reveal that various types of slight corruption in the pre-training data can significantly enhance the quality, diversity, and fidelity of the generated images, both during pre-training and downstream adaptation.
Theoretically, the researchers consider a Gaussian mixture model and prove that slight corruption in the input conditions leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs.
Inspired by this analysis, the researchers propose a simple method called "condition embedding perturbation" (CEP) to improve the training of DMs on practical datasets. CEP involves intentionally adding a small amount of noise or corruption to the input conditions during training, which can significantly improve the performance of various DMs in both pre-training and downstream tasks.
Critical Analysis
The researchers provide a comprehensive and well-designed study on the impact of corrupted pre-training data on diffusion models. However, the paper does not fully address the potential risks or limitations of this approach.
For example, the researchers only explore synthetic corruption of the datasets, and it's unclear how well their findings would translate to real-world datasets with more complex and varied types of corruption. Additionally, while the condition embedding perturbation method shows promising results, the paper does not explore the long-term effects of this technique or how it might interact with other model training strategies.
Furthermore, the paper does not delve into the ethical implications of using potentially corrupted data or intentionally introducing noise during training. There could be concerns around the reliability and trustworthiness of models trained in this way, especially in sensitive applications like medical imaging or autonomous systems.
Overall, the research provides valuable insights into the robustness of diffusion models to data corruption, but more work is needed to fully understand the implications and potential risks of these techniques.
Conclusion
This paper presents a comprehensive study on the impact of corrupted pre-training data on the performance of diffusion models (DMs). The researchers found that a small amount of corruption in the input conditions can actually improve the quality, diversity, and fidelity of the images generated by DMs, both during pre-training and downstream adaptation.
The researchers propose a simple technique called "condition embedding perturbation" that intentionally introduces a controlled amount of noise or corruption to the input conditions during training, leading to better-performing DMs. This research provides new insights into the robustness of DMs and suggests that carefully managed data corruption could be a valuable tool for improving the training of these powerful AI systems.
However, the paper also highlights the need for further exploration of the potential risks and limitations of this approach, particularly when it comes to the use of DMs in sensitive or high-stakes applications. Nonetheless, this study represents an important step forward in understanding the complex relationship between data quality, model training, and AI system performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring Diffusion Models' Corruption Stage in Few-Shot Fine-tuning and Mitigating with Bayesian Neural Networks
Xiaoyu Wu, Jiaru Zhang, Yang Hua, Bohan Lyu, Hao Wang, Tao Song, Haibing Guan
0
0
Few-shot fine-tuning of Diffusion Models (DMs) is a key advancement, significantly reducing training costs and enabling personalized AI applications. However, we explore the training dynamics of DMs and observe an unanticipated phenomenon: during the training process, image fidelity initially improves, then unexpectedly deteriorates with the emergence of noisy patterns, only to recover later with severe overfitting. We term the stage with generated noisy patterns as corruption stage. To understand this corruption stage, we begin by theoretically modeling the one-shot fine-tuning scenario, and then extend this modeling to more general cases. Through this modeling, we identify the primary cause of this corruption stage: a narrowed learning distribution inherent in the nature of few-shot fine-tuning. To tackle this, we apply Bayesian Neural Networks (BNNs) on DMs with variational inference to implicitly broaden the learned distribution, and present that the learning target of the BNNs can be naturally regarded as an expectation of the diffusion loss and a further regularization with the pretrained DMs. This approach is highly compatible with current few-shot fine-tuning methods in DMs and does not introduce any extra inference costs. Experimental results demonstrate that our method significantly mitigates corruption, and improves the fidelity, quality and diversity of the generated images in both object-driven and subject-driven generation tasks.
5/31/2024

Improving robustness to corruptions with multiplicative weight perturbations
Trung Trinh, Markus Heinonen, Luigi Acerbi, Samuel Kaski
0
0
Deep neural networks (DNNs) excel on clean images but struggle with corrupted ones. Incorporating specific corruptions into the data augmentation pipeline can improve robustness to those corruptions but may harm performance on clean images and other types of distortion. In this paper, we introduce an alternative approach that improves the robustness of DNNs to a wide range of corruptions without compromising accuracy on clean images. We first demonstrate that input perturbations can be mimicked by multiplicative perturbations in the weight space. Leveraging this, we propose Data Augmentation via Multiplicative Perturbation (DAMP), a training method that optimizes DNNs under random multiplicative weight perturbations. We also examine the recently proposed Adaptive Sharpness-Aware Minimization (ASAM) and show that it optimizes DNNs under adversarial multiplicative weight perturbations. Experiments on image classification datasets (CIFAR-10/100, TinyImageNet and ImageNet) and neural network architectures (ResNet50, ViT-S/16) show that DAMP enhances model generalization performance in the presence of corruptions across different settings. Notably, DAMP is able to train a ViT-S/16 on ImageNet from scratch, reaching the top-1 error of 23.7% which is comparable to ResNet50 without extensive data augmentations.
6/26/2024
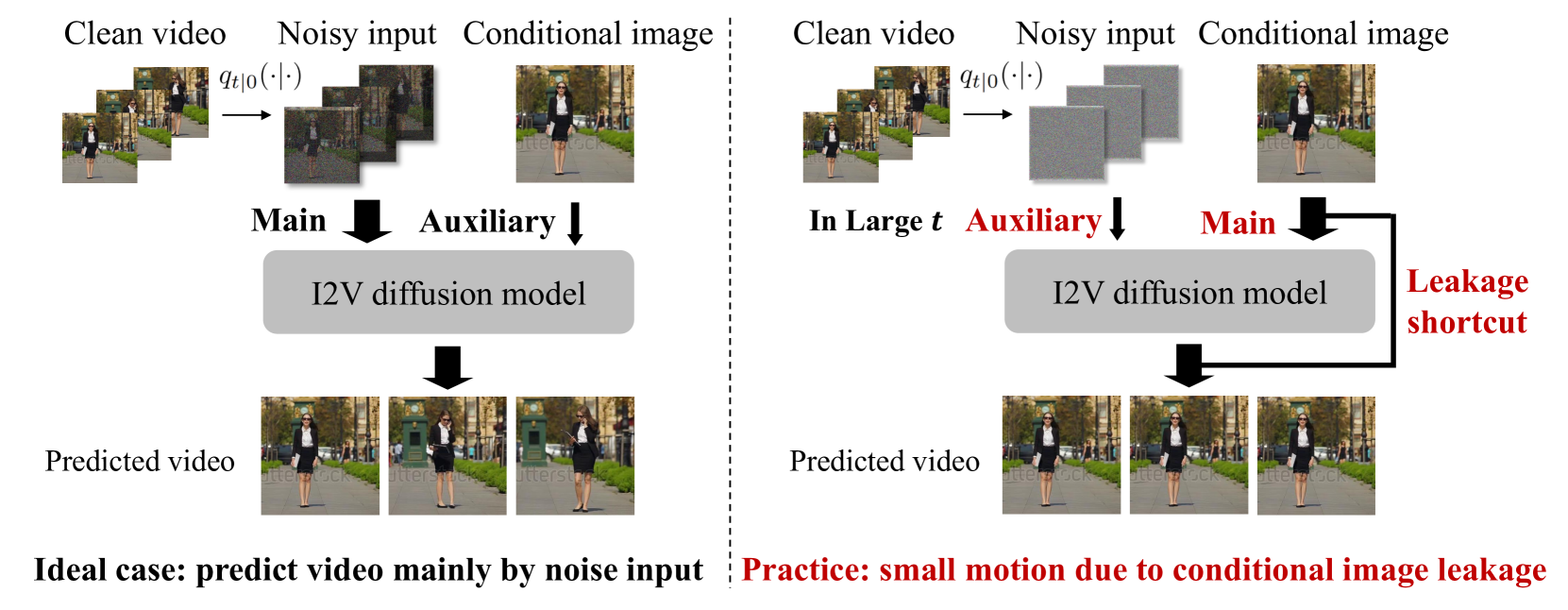
Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model
Min Zhao, Hongzhou Zhu, Chendong Xiang, Kaiwen Zheng, Chongxuan Li, Jun Zhu
0
0
Diffusion models have obtained substantial progress in image-to-video (I2V) generation. However, such models are not fully understood. In this paper, we report a significant but previously overlooked issue in I2V diffusion models (I2V-DMs), namely, conditional image leakage. I2V-DMs tend to over-rely on the conditional image at large time steps, neglecting the crucial task of predicting the clean video from noisy inputs, which results in videos lacking dynamic and vivid motion. We further address this challenge from both inference and training aspects by presenting plug-and-play strategies accordingly. First, we introduce a training-free inference strategy that starts the generation process from an earlier time step to avoid the unreliable late-time steps of I2V-DMs, as well as an initial noise distribution with optimal analytic expressions (Analytic-Init) by minimizing the KL divergence between it and the actual marginal distribution to effectively bridge the training-inference gap. Second, to mitigate conditional image leakage during training, we design a time-dependent noise distribution for the conditional image, which favors high noise levels at large time steps to sufficiently interfere with the conditional image. We validate these strategies on various I2V-DMs using our collected open-domain image benchmark and the UCF101 dataset. Extensive results demonstrate that our methods outperform baselines by producing videos with more dynamic and natural motion without compromising image alignment and temporal consistency. The project page: url{https://cond-image-leak.github.io/}.
6/26/2024
👨🏫
Corruptions of Supervised Learning Problems: Typology and Mitigations
Laura Iacovissi, Nan Lu, Robert C. Williamson
0
0
Corruption is notoriously widespread in data collection. Despite extensive research, the existing literature on corruption predominantly focuses on specific settings and learning scenarios, lacking a unified view. There is still a limited understanding of how to effectively model and mitigate corruption in machine learning problems. In this work, we develop a general theory of corruption from an information-theoretic perspective - with Markov kernels as a foundational mathematical tool. We generalize the definition of corruption beyond the concept of distributional shift: corruption includes all modifications of a learning problem, including changes in model class and loss function. We will focus here on changes in probability distributions. First, we construct a provably exhaustive framework for pairwise Markovian corruptions. The framework not only allows us to study corruption types based on their input space, but also serves to unify prior works on specific corruption models and establish a consistent nomenclature. Second, we systematically analyze the consequences of corruption on learning tasks by comparing Bayes risks in the clean and corrupted scenarios. This examination sheds light on complexities arising from joint and dependent corruptions on both labels and attributes. Notably, while label corruptions affect only the loss function, more intricate cases involving attribute corruptions extend the influence beyond the loss to affect the hypothesis class. Third, building upon these results, we investigate mitigations for various corruption types. We expand the existing loss-correction results for label corruption, and identify the necessity to generalize the classical corruption-corrected learning framework to a new paradigm with weaker requirements. Within the latter setting, we provide a negative result for loss correction in the attribute and the joint corruption case.
5/6/2024