SonicVisionLM: Playing Sound with Vision Language Models
2401.04394
0
2
Abstract
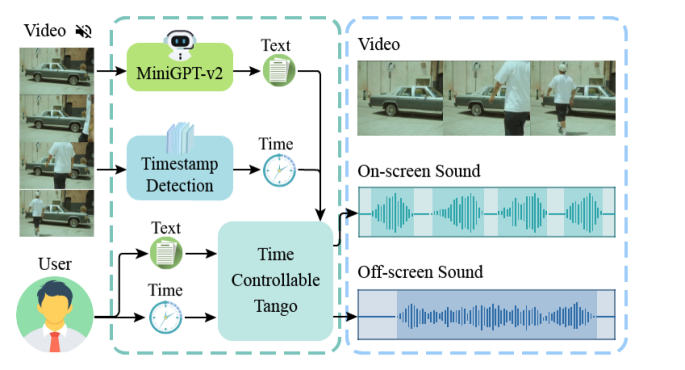
There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations. In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision-language models(VLMs). Instead of generating audio directly from video, we use the capabilities of powerful VLMs. When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed a time-controlled audio adapter. Our approach surpasses current state-of-the-art methods for converting video to audio, enhancing synchronization with the visuals, and improving alignment between audio and video components. Project page: https://yusiissy.github.io/SonicVisionLM.github.io/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces SonicVisionLM, a novel approach for playing sound based on vision language models.
- The key idea is to leverage large pre-trained vision-language models to generate audio output from text input.
- The authors demonstrate that SonicVisionLM can be used for a variety of audio generation tasks, including music, speech, and sound effects.
Plain English Explanation
SonicVisionLM is a new system that allows you to generate sound from text. It works by using powerful language models that were originally designed for processing images and text together. The researchers found a way to adapt these models to also generate audio output, based solely on text input.
This is a fascinating capability, as it means you can potentially create all sorts of sounds and audio just by typing some words. For example, you could describe a particular type of music or a sound effect, and the system would then automatically produce that audio for you.
The researchers show that SonicVisionLM can generate a diverse range of audio, from musical compositions to speech to environmental sounds. This opens up a lot of interesting possibilities, like being able to quickly prototype audio for movies, video games, or other applications just by providing some text descriptions.
Of course, the quality of the generated audio is not perfect yet, and there is still room for improvement. But the core idea of leveraging powerful language models to bridge the gap between text and audio is a really intriguing development in the field of audio generation and synthesis.
Technical Explanation
SonicVisionLM is built upon recent advancements in vision-language models, which are deep neural networks trained on large datasets of images and associated text. The key innovation in this work is adapting these models to also generate audio output, in addition to their standard capabilities for processing and generating text and images.
The core architecture of SonicVisionLM consists of a vision-language encoder that takes in the text input, and an audio decoder that produces the corresponding waveform. The researchers experiment with different decoder configurations, including autoregressive and non-autoregressive approaches, to balance audio quality and generation speed.
Importantly, the authors do not train SonicVisionLM from scratch. Instead, they leverage pre-trained vision-language models like CLIP and adapt them to the audio generation task through additional fine-tuning. This allows them to benefit from the powerful representations and multimodal understanding already learned by these models.
The authors evaluate SonicVisionLM on a variety of audio generation benchmarks, covering music, speech, and environmental sounds. The results show that SonicVisionLM can generate plausible and diverse audio outputs, outperforming prior text-to-audio methods in several metrics.
Critical Analysis
A key strength of SonicVisionLM is its ability to leverage large-scale vision-language models, which have shown remarkable performance on a wide range of multimodal tasks. By building on these pre-trained foundations, the authors are able to rapidly develop a capable audio generation system without starting from scratch.
However, the audio quality produced by SonicVisionLM is still limited compared to specialized audio synthesis models. The authors acknowledge this as an area for future improvement, suggesting that combining SonicVisionLM with more sophisticated audio decoders or neural vocoders could lead to further advancements.
Additionally, the current version of SonicVisionLM is trained on a relatively narrow set of audio data, focused primarily on music, speech, and environmental sounds. Expanding the training data to cover a broader range of audio types, such as sound effects or more diverse musical genres, could enhance the system's versatility and applicability.
Another potential limitation is the computational cost and latency associated with generating high-quality audio. As the authors note, the autoregressive decoding approach can be slow, while the non-autoregressive method may compromise audio fidelity. Addressing this trade-off between speed and quality could be an important direction for future research.
Conclusion
SonicVisionLM represents an innovative approach to bridging the gap between text and audio generation. By leveraging powerful vision-language models, the system demonstrates the ability to produce plausible and diverse audio outputs based solely on text input. This capability opens up exciting possibilities for applications in media production, creative expression, and human-computer interaction.
While the current quality of the generated audio is not yet on par with specialized audio synthesis models, the core concept of SonicVisionLM is a significant step forward in the field of multimodal AI. Continued research and development in this area could lead to further advancements, potentially expanding the ways in which we can interact with and manipulate audio through language-based interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Synthesizing Audio from Silent Video using Sequence to Sequence Modeling
Hugo Garrido-Lestache Belinchon, Helina Mulugeta, Adam Haile
0
0
Generating audio from a video's visual context has multiple practical applications in improving how we interact with audio-visual media - for example, enhancing CCTV footage analysis, restoring historical videos (e.g., silent movies), and improving video generation models. We propose a novel method to generate audio from video using a sequence-to-sequence model, improving on prior work that used CNNs and WaveNet and faced sound diversity and generalization challenges. Our approach employs a 3D Vector Quantized Variational Autoencoder (VQ-VAE) to capture the video's spatial and temporal structures, decoding with a custom audio decoder for a broader range of sounds. Trained on the Youtube8M dataset segment, focusing on specific domains, our model aims to enhance applications like CCTV footage analysis, silent movie restoration, and video generation models.
4/30/2024
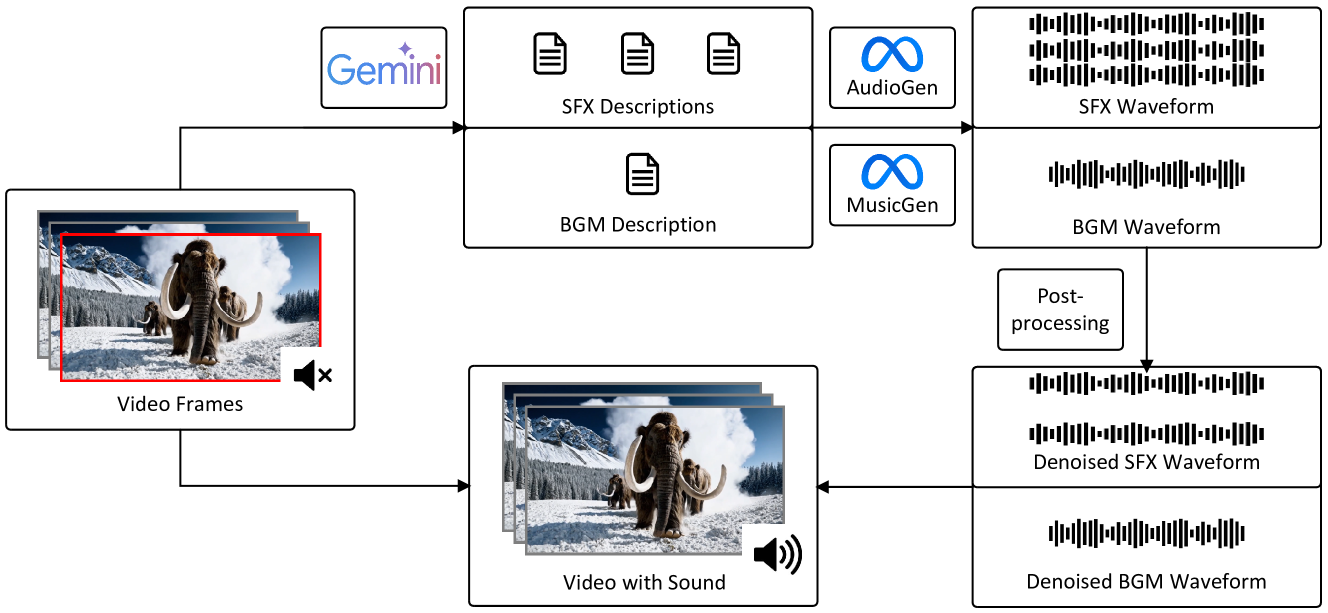
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
0
0
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
4/29/2024
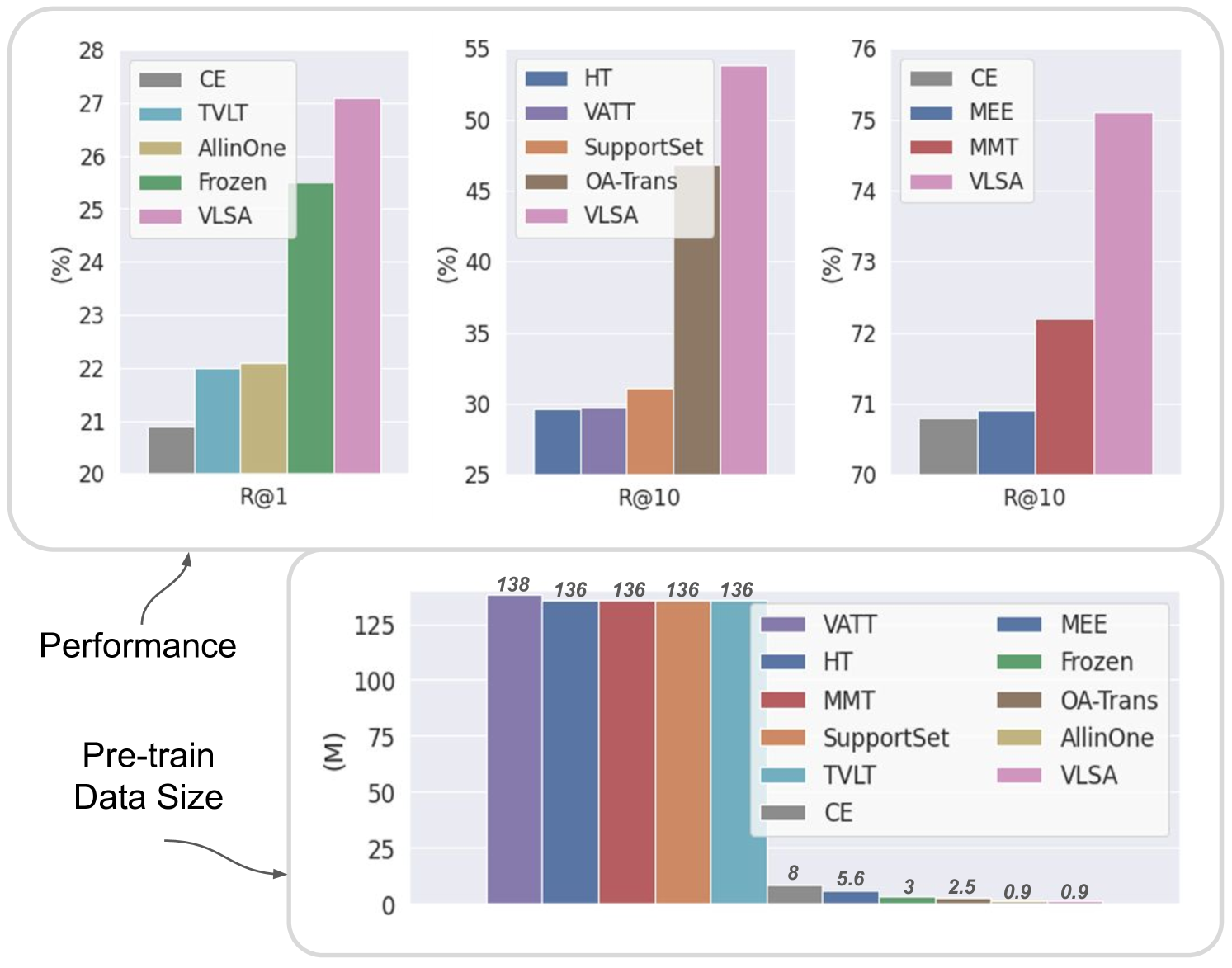
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024
📈
Audio is all in one: speech-driven gesture synthetics using WavLM pre-trained model
Fan Zhang, Naye Ji, Fuxing Gao, Siyuan Zhao, Zhaohan Wang, Shunman Li
0
0
The generation of co-speech gestures for digital humans is an emerging area in the field of virtual human creation. Prior research has made progress by using acoustic and semantic information as input and adopting classify method to identify the person's ID and emotion for driving co-speech gesture generation. However, this endeavour still faces significant challenges. These challenges go beyond the intricate interplay between co-speech gestures, speech acoustic, and semantics; they also encompass the complexities associated with personality, emotion, and other obscure but important factors. This paper introduces diffmotion-v2, a speech-conditional diffusion-based and non-autoregressive transformer-based generative model with WavLM pre-trained model. It can produce individual and stylized full-body co-speech gestures only using raw speech audio, eliminating the need for complex multimodal processing and manually annotated. Firstly, considering that speech audio not only contains acoustic and semantic features but also conveys personality traits, emotions, and more subtle information related to accompanying gestures, we pioneer the adaptation of WavLM, a large-scale pre-trained model, to extract low-level and high-level audio information. Secondly, we introduce an adaptive layer norm architecture in the transformer-based layer to learn the relationship between speech information and accompanying gestures. Extensive subjective evaluation experiments are conducted on the Trinity, ZEGGS, and BEAT datasets to confirm the WavLM and the model's ability to synthesize natural co-speech gestures with various styles.
4/16/2024