Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised Object Detection
2404.01819
0
0
Abstract
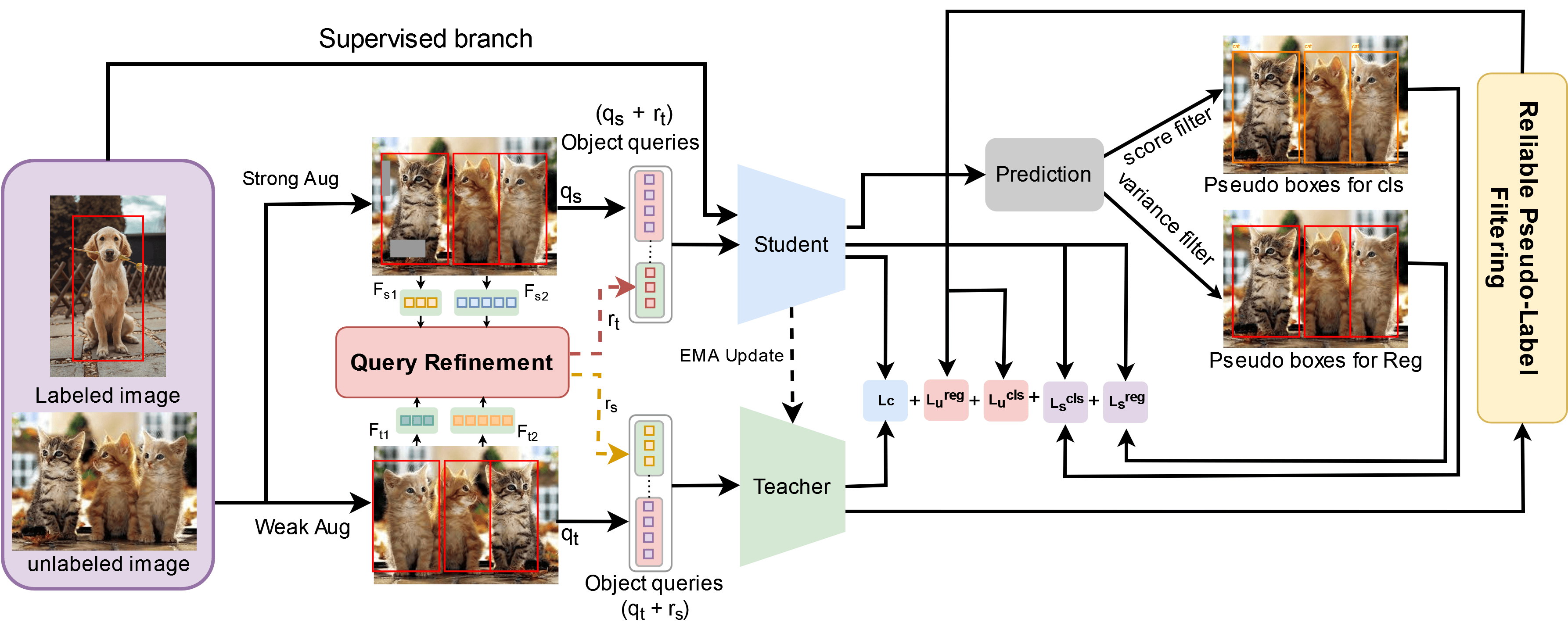
In this paper, we address the limitations of the DETR-based semi-supervised object detection (SSOD) framework, particularly focusing on the challenges posed by the quality of object queries. In DETR-based SSOD, the one-to-one assignment strategy provides inaccurate pseudo-labels, while the one-to-many assignments strategy leads to overlapping predictions. These issues compromise training efficiency and degrade model performance, especially in detecting small or occluded objects. We introduce Sparse Semi-DETR, a novel transformer-based, end-to-end semi-supervised object detection solution to overcome these challenges. Sparse Semi-DETR incorporates a Query Refinement Module to enhance the quality of object queries, significantly improving detection capabilities for small and partially obscured objects. Additionally, we integrate a Reliable Pseudo-Label Filtering Module that selectively filters high-quality pseudo-labels, thereby enhancing detection accuracy and consistency. On the MS-COCO and Pascal VOC object detection benchmarks, Sparse Semi-DETR achieves a significant improvement over current state-of-the-art methods that highlight Sparse Semi-DETR's effectiveness in semi-supervised object detection, particularly in challenging scenarios involving small or partially obscured objects.
Create account to get full access
Overview
- This paper presents Sparse Semi-DETR, a novel object detection approach that uses sparse learnable queries to enable semi-supervised learning.
- The method aims to improve object detection performance by leveraging both labeled and unlabeled data, overcoming the need for extensive manual annotation.
- The key innovation is the use of sparse learnable queries, which serve as a flexible and efficient way to detect objects in the absence of full supervision.
Plain English Explanation
Sparse Semi-DETR is a new way to detect objects in images, even when you don't have a lot of labeled training data. Normally, object detection models need a huge amount of labeled data to learn what different objects look like. This can be very time-consuming and expensive to obtain.
The key idea behind Sparse Semi-DETR is to use "sparse learnable queries" - a set of flexible object templates that the model can learn to match against the image. These queries act as a kind of shorthand, allowing the model to efficiently detect objects without needing a ton of labeled examples.
The model is trained on a mix of labeled and unlabeled data. The labeled data provides some ground truth examples to learn from, while the unlabeled data gives the model a chance to generalize and discover new objects on its own. By combining these two sources of information, Sparse Semi-DETR can achieve strong object detection performance with much less manual annotation effort.
Overall, this approach represents an exciting advance in making object detection more scalable and accessible, by reducing the reliance on expensive labeled datasets. It could enable a wide range of real-world applications that were previously limited by the data bottleneck.
Technical Explanation
The core of Sparse Semi-DETR is a transformer-based object detection architecture that uses sparse learnable queries. These queries are a set of learnable object templates that serve as the model's object proposals. Unlike traditional region proposal networks, the sparse queries are learned end-to-end as part of the overall detection pipeline.
During training, the model sees a mix of labeled and unlabeled images. For the labeled data, the sparse queries are trained to match the ground truth object bounding boxes. For the unlabeled data, the model learns to discover new object instances that the sparse queries can effectively detect.
The key advantages of this approach are:
- Efficiency - The sparse query representation is more compact and flexible than dense proposals, enabling faster and more accurate detection.
- Semi-supervision - The ability to leverage unlabeled data improves generalization and reduces the need for manual annotation.
- End-to-end learning - The sparse queries are optimized jointly with the rest of the detection pipeline, allowing the model to learn an effective object representation.
Extensive experiments on common benchmarks show that Sparse Semi-DETR outperforms fully-supervised baselines and other semi-supervised methods, demonstrating the power of this sparse learnable query approach.
Critical Analysis
The paper provides a thorough evaluation of Sparse Semi-DETR, exploring its performance across different datasets and semi-supervised setups. The results convincingly show the benefits of the sparse learnable queries, which enable effective object detection with much less labeled training data.
However, the paper does not deeply address some potential limitations or avenues for future work. For example, it is unclear how the sparse query mechanism would scale to richer, more complex object categories beyond the common COCO classes. Additionally, the semi-supervised training process is still somewhat opaque, and further analysis of how the model learns from unlabeled data could lead to insights for improving the approach.
More broadly, the reliance on transformer-based architectures raises questions about model interpretability and the ability to deploy these systems in resource-constrained real-world settings. Exploring alternative lightweight query mechanisms or hybrid approaches could help address these practical concerns.
Overall, Sparse Semi-DETR represents an impressive advance in semi-supervised object detection. But as with any new technique, there is still room for refinement and expansion to fully realize its potential impact on real-world applications.
Conclusion
Sparse Semi-DETR introduces a novel semi-supervised object detection framework that leverages sparse learnable queries to achieve strong performance with limited labeled data. By combining the efficiency of the sparse query representation with the flexibility of semi-supervised learning, this approach opens up new possibilities for scalable and practical object detection.
The results demonstrate the power of this technique, which could have far-reaching implications for a wide range of applications that rely on computer vision, from autonomous vehicles to medical imaging. As the field of machine learning continues to push the boundaries of what's possible with limited supervision, innovations like Sparse Semi-DETR will become increasingly valuable in bringing these capabilities to the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DQ-DETR: DETR with Dynamic Query for Tiny Object Detection
Yi-Xin Huang, Hou-I Liu, Hong-Han Shuai, Wen-Huang Cheng
0
0
Despite previous DETR-like methods having performed successfully in generic object detection, tiny object detection is still a challenging task for them since the positional information of object queries is not customized for detecting tiny objects, whose scale is extraordinarily smaller than general objects. Also, DETR-like methods using a fixed number of queries make them unsuitable for aerial datasets, which only contain tiny objects, and the numbers of instances are imbalanced between different images. Thus, we present a simple yet effective model, named DQ-DETR, which consists of three different components: categorical counting module, counting-guided feature enhancement, and dynamic query selection to solve the above-mentioned problems. DQ-DETR uses the prediction and density maps from the categorical counting module to dynamically adjust the number of object queries and improve the positional information of queries. Our model DQ-DETR outperforms previous CNN-based and DETR-like methods, achieving state-of-the-art mAP 30.2% on the AI-TOD-V2 dataset, which mostly consists of tiny objects.
4/15/2024

SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Lin Liu, Ziying Song, Qiming Xia, Feiyang Jia, Caiyan Jia, Lei Yang, Hongyu Pan
0
0
LiDAR-based sparse 3D object detection plays a crucial role in autonomous driving applications due to its computational efficiency advantages. Existing methods either use the features of a single central voxel as an object proxy, or treat an aggregated cluster of foreground points as an object proxy. However, the former lacks the ability to aggregate contextual information, resulting in insufficient information expression in object proxies. The latter relies on multi-stage pipelines and auxiliary tasks, which reduce the inference speed. To maintain the efficiency of the sparse framework while fully aggregating contextual information, in this work, we propose SparseDet which designs sparse queries as object proxies. It introduces two key modules, the Local Multi-scale Feature Aggregation (LMFA) module and the Global Feature Aggregation (GFA) module, aiming to fully capture the contextual information, thereby enhancing the ability of the proxies to represent objects. Where LMFA sub-module achieves feature fusion across different scales for sparse key voxels %which does this through via coordinate transformations and using nearest neighbor relationships to capture object-level details and local contextual information, GFA sub-module uses self-attention mechanisms to selectively aggregate the features of the key voxels across the entire scene for capturing scene-level contextual information. Experiments on nuScenes and KITTI demonstrate the effectiveness of our method. Specifically, on nuScene, SparseDet surpasses the previous best sparse detector VoxelNeXt by 2.2% mAP with 13.5 FPS, and on KITTI, it surpasses VoxelNeXt by 1.12% $mathbf{AP_{3D}}$ on hard level tasks with 17.9 FPS.
6/18/2024
🔮
OccupancyDETR: Using DETR for Mixed Dense-sparse 3D Occupancy Prediction
Yupeng Jia, Jie He, Runze Chen, Fang Zhao, Haiyong Luo
0
0
Visual-based 3D semantic occupancy perception is a key technology for robotics, including autonomous vehicles, offering an enhanced understanding of the environment by 3D. This approach, however, typically requires more computational resources than BEV or 2D methods. We propose a novel 3D semantic occupancy perception method, OccupancyDETR, which utilizes a DETR-like object detection, a mixed dense-sparse 3D occupancy decoder. Our approach distinguishes between foreground and background within a scene. Initially, foreground objects are detected using the DETR-like object detection. Subsequently, queries for both foreground and background objects are fed into the mixed dense-sparse 3D occupancy decoder, performing upsampling in dense and sparse methods, respectively. Finally, a MaskFormer is utilized to infer the semantics of the background voxels. Our approach strikes a balance between efficiency and accuracy, achieving faster inference times, lower resource consumption, and improved performance for small object detection. We demonstrate the effectiveness of our proposed method on the SemanticKITTI dataset, showcasing an mIoU of 14 and a processing speed of 10 FPS, thereby presenting a promising solution for real-time 3D semantic occupancy perception.
5/21/2024
SpecDETR: A Transformer-based Hyperspectral Point Object Detection Network
Zhaoxu Li, Wei An, Gaowei Guo, Longguang Wang, Yingqian Wang, Zaiping Lin
0
0
Hyperspectral target detection (HTD) aims to identify specific materials based on spectral information in hyperspectral imagery and can detect point targets, some of which occupy a smaller than one-pixel area. However, existing HTD methods are developed based on per-pixel binary classification, which limits the feature representation capability for point targets. In this paper, we rethink the hyperspectral point target detection from the object detection perspective, and focus more on the object-level prediction capability rather than the pixel classification capability. Inspired by the token-based processing flow of Detection Transformer (DETR), we propose the first specialized network for hyperspectral multi-class point object detection, SpecDETR. Without the backbone part of the current object detection framework, SpecDETR treats the spectral features of each pixel in hyperspectral images as a token and utilizes a multi-layer Transformer encoder with local and global coordination attention modules to extract deep spatial-spectral joint features. SpecDETR regards point object detection as a one-to-many set prediction problem, thereby achieving a concise and efficient DETR decoder that surpasses the current state-of-the-art DETR decoder in terms of parameters and accuracy in point object detection. We develop a simulated hyperSpectral Point Object Detection benchmark termed SPOD, and for the first time, evaluate and compare the performance of current object detection networks and HTD methods on hyperspectral multi-class point object detection. SpecDETR demonstrates superior performance as compared to current object detection networks and HTD methods on the SPOD dataset. Additionally, we validate on a public HTD dataset that by using data simulation instead of manual annotation, SpecDETR can detect real-world single-spectral point objects directly.
5/17/2024