SUGAR: Pre-training 3D Visual Representations for Robotics
2404.01491
0
0

Abstract
Learning generalizable visual representations from Internet data has yielded promising results for robotics. Yet, prevailing approaches focus on pre-training 2D representations, being sub-optimal to deal with occlusions and accurately localize objects in complex 3D scenes. Meanwhile, 3D representation learning has been limited to single-object understanding. To address these limitations, we introduce a novel 3D pre-training framework for robotics named SUGAR that captures semantic, geometric and affordance properties of objects through 3D point clouds. We underscore the importance of cluttered scenes in 3D representation learning, and automatically construct a multi-object dataset benefiting from cost-free supervision in simulation. SUGAR employs a versatile transformer-based model to jointly address five pre-training tasks, namely cross-modal knowledge distillation for semantic learning, masked point modeling to understand geometry structures, grasping pose synthesis for object affordance, 3D instance segmentation and referring expression grounding to analyze cluttered scenes. We evaluate our learned representation on three robotic-related tasks, namely, zero-shot 3D object recognition, referring expression grounding, and language-driven robotic manipulation. Experimental results show that SUGAR's 3D representation outperforms state-of-the-art 2D and 3D representations.
Create account to get full access
Overview
- SUGAR is a method for pre-training 3D visual representations to improve performance on downstream robotics tasks
- It involves self-supervised learning from large-scale 3D data to learn useful visual features
- The pre-trained model can then be fine-tuned on specific robotics applications for better performance
Plain English Explanation
SUGAR is a new approach to help robots see and understand the 3D world around them more effectively. When robots are trained on 3D data, they can learn useful visual features that allow them to perform tasks like object recognition, scene understanding, and motion planning better.
The key idea behind SUGAR is to first pre-train the robot's visual system on a large amount of 3D data, using a self-supervised learning approach. This means the robot can learn these visual features without human labels or annotations - it can just discover patterns in the 3D data on its own. Once this pre-training is done, the robot can then be fine-tuned on specific robotics applications, building on the strong visual foundations it has learned.
This pre-training approach is powerful because it allows the robot to leverage massive amounts of 3D data to learn robust and generalizable visual representations. Rather than starting from scratch every time, the robot can build on this pre-trained knowledge to quickly adapt to new robotic tasks and environments. This can lead to significant performance improvements compared to training the robot's visual system entirely from scratch.
Technical Explanation
SUGAR utilizes a self-supervised learning approach to pre-train 3D visual representations. The model is trained on a large-scale 3D dataset using a variety of pretext tasks, such as 3D object view prediction, 3D point cloud instance segmentation, and 3D object pose estimation. These tasks encourage the model to learn useful visual features and geometric understanding without the need for manual labeling.
The SUGAR architecture consists of a 3D backbone network that encodes the input 3D data, along with task-specific prediction heads. During pre-training, the model is trained to perform well on these various 3D prediction tasks. The resulting pre-trained model can then be fine-tuned on downstream robotics applications, such as object detection, semantic segmentation, and motion planning.
Experiments demonstrate that the SUGAR pre-training approach leads to significant performance gains on a range of 3D robotics benchmarks, outperforming models trained from scratch. The learned visual representations are shown to be transferable and generalizable, enabling efficient adaptation to new tasks and domains.
Critical Analysis
The SUGAR paper presents a compelling approach for improving 3D visual understanding in robotics through self-supervised pre-training. However, the authors acknowledge some limitations and areas for future work:
- The current pre-training tasks are relatively simple and may not fully capture the complexity of real-world robotics applications. More sophisticated pretext tasks could potentially lead to even more powerful visual representations.
- The experiments focus on popular robotics datasets, but it remains to be seen how well the SUGAR pre-training generalizes to more diverse or challenging real-world robotic environments.
- The paper does not explore the computational and memory efficiency of the SUGAR pre-training approach, which could be an important consideration for resource-constrained robotic systems.
Additionally, while the results are promising, some readers may wish to see more thorough comparisons to other state-of-the-art 3D representation learning methods to better understand SUGAR's relative strengths and weaknesses.
Conclusion
SUGAR offers a promising approach for boosting the 3D visual capabilities of robotic systems through self-supervised pre-training. By leveraging large-scale 3D data to learn powerful visual representations, the SUGAR method can significantly improve the performance of robots on a variety of downstream tasks, from object detection to motion planning. As robots continue to play an increasingly important role in our lives, advancements in 3D visual understanding like SUGAR will be crucial for enabling more capable, adaptable, and intelligent robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
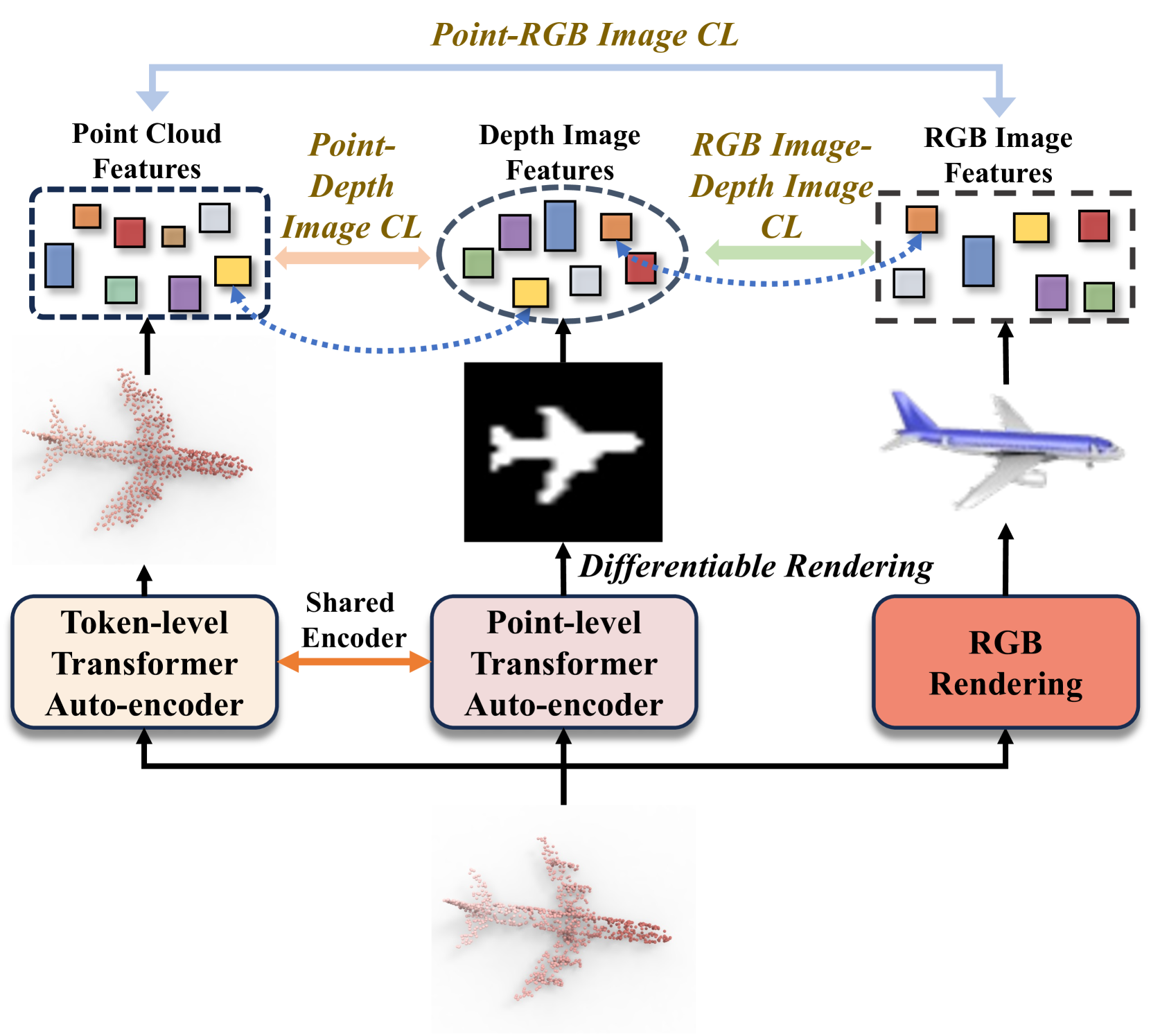
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
0
0
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
4/23/2024

Enhancing Generalizability of Representation Learning for Data-Efficient 3D Scene Understanding
Yunsong Wang, Na Zhao, Gim Hee Lee
0
0
The field of self-supervised 3D representation learning has emerged as a promising solution to alleviate the challenge presented by the scarcity of extensive, well-annotated datasets. However, it continues to be hindered by the lack of diverse, large-scale, real-world 3D scene datasets for source data. To address this shortfall, we propose Generalizable Representation Learning (GRL), where we devise a generative Bayesian network to produce diverse synthetic scenes with real-world patterns, and conduct pre-training with a joint objective. By jointly learning a coarse-to-fine contrastive learning task and an occlusion-aware reconstruction task, the model is primed with transferable, geometry-informed representations. Post pre-training on synthetic data, the acquired knowledge of the model can be seamlessly transferred to two principal downstream tasks associated with 3D scene understanding, namely 3D object detection and 3D semantic segmentation, using real-world benchmark datasets. A thorough series of experiments robustly display our method's consistent superiority over existing state-of-the-art pre-training approaches.
6/18/2024

Enhancing 2D Representation Learning with a 3D Prior
Mehmet Aygun, Prithviraj Dhar, Zhicheng Yan, Oisin Mac Aodha, Rakesh Ranjan
0
0
Learning robust and effective representations of visual data is a fundamental task in computer vision. Traditionally, this is achieved by training models with labeled data which can be expensive to obtain. Self-supervised learning attempts to circumvent the requirement for labeled data by learning representations from raw unlabeled visual data alone. However, unlike humans who obtain rich 3D information from their binocular vision and through motion, the majority of current self-supervised methods are tasked with learning from monocular 2D image collections. This is noteworthy as it has been demonstrated that shape-centric visual processing is more robust compared to texture-biased automated methods. Inspired by this, we propose a new approach for strengthening existing self-supervised methods by explicitly enforcing a strong 3D structural prior directly into the model during training. Through experiments, across a range of datasets, we demonstrate that our 3D aware representations are more robust compared to conventional self-supervised baselines.
6/5/2024
✨
Multi-View Representation is What You Need for Point-Cloud Pre-Training
Siming Yan, Chen Song, Youkang Kong, Qixing Huang
0
0
A promising direction for pre-training 3D point clouds is to leverage the massive amount of data in 2D, whereas the domain gap between 2D and 3D creates a fundamental challenge. This paper proposes a novel approach to point-cloud pre-training that learns 3D representations by leveraging pre-trained 2D networks. Different from the popular practice of predicting 2D features first and then obtaining 3D features through dimensionality lifting, our approach directly uses a 3D network for feature extraction. We train the 3D feature extraction network with the help of the novel 2D knowledge transfer loss, which enforces the 2D projections of the 3D feature to be consistent with the output of pre-trained 2D networks. To prevent the feature from discarding 3D signals, we introduce the multi-view consistency loss that additionally encourages the projected 2D feature representations to capture pixel-wise correspondences across different views. Such correspondences induce 3D geometry and effectively retain 3D features in the projected 2D features. Experimental results demonstrate that our pre-trained model can be successfully transferred to various downstream tasks, including 3D shape classification, part segmentation, 3D object detection, and semantic segmentation, achieving state-of-the-art performance.
4/30/2024