SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering
2404.01225
0
0

Abstract
Dynamic human rendering from video sequences has achieved remarkable progress by formulating the rendering as a mapping from static poses to human images. However, existing methods focus on the human appearance reconstruction of every single frame while the temporal motion relations are not fully explored. In this paper, we propose a new 4D motion modeling paradigm, SurMo, that jointly models the temporal dynamics and human appearances in a unified framework with three key designs: 1) Surface-based motion encoding that models 4D human motions with an efficient compact surface-based triplane. It encodes both spatial and temporal motion relations on the dense surface manifold of a statistical body template, which inherits body topology priors for generalizable novel view synthesis with sparse training observations. 2) Physical motion decoding that is designed to encourage physical motion learning by decoding the motion triplane features at timestep t to predict both spatial derivatives and temporal derivatives at the next timestep t+1 in the training stage. 3) 4D appearance decoding that renders the motion triplanes into images by an efficient volumetric surface-conditioned renderer that focuses on the rendering of body surfaces with motion learning conditioning. Extensive experiments validate the state-of-the-art performance of our new paradigm and illustrate the expressiveness of surface-based motion triplanes for rendering high-fidelity view-consistent humans with fast motions and even motion-dependent shadows. Our project page is at: https://taohuumd.github.io/projects/SurMo/
Create account to get full access
Overview
- This paper introduces SurMo, a novel approach for modeling the 4D (3D + time) motion of dynamic human surfaces.
- SurMo captures the complex deformations of human skin and clothing during motion by learning a surface-based representation.
- The model can be used for high-fidelity rendering of dynamic human characters.
Plain English Explanation
SurMo is a new way to digitally capture the movements and deformations of the human body and clothing in 3D over time. Most existing methods for modeling human motion rely on tracking a set of joints or markers, but this can miss important details like the complex ways our skin and clothes move. SurMo instead learns a direct representation of the surface of the human body, allowing it to model even subtle changes in shape and texture as we move.
This is useful for creating highly realistic digital human characters, for example in video games, movies, or virtual reality experiences. By accurately capturing the nuanced dynamics of the human form, SurMo can enable the rendering of characters that look and move in a truly lifelike manner. This could lead to more immersive and believable virtual environments.
Technical Explanation
The key innovation of SurMo is its surface-based approach to motion modeling. Rather than tracking a skeleton or set of landmarks, the method directly learns a parametric representation of the dynamic 3D surface of the human body. This allows it to capture fine-grained deformations of the skin and clothing that traditional joint-based models miss.
SurMo achieves this by combining a convolutional neural network to extract meaningful features from 3D surface data, with a recurrent neural network to model the temporal evolution of those features over time. The authors train this architecture on a large dataset of 4D scans of human subjects performing various motions.
Experiments show that SurMo can generate highly realistic renderings of dynamic human characters, outperforming previous state-of-the-art approaches on both quantitative and qualitative metrics. The model is also efficient, enabling real-time inference and rendering.
Critical Analysis
The paper provides a thorough technical description of the SurMo architecture and demonstrates its effectiveness through extensive evaluations. However, it does not deeply explore some potential limitations or avenues for future work.
For example, the training data consisted of 4D scans captured in a controlled laboratory setting. It's unclear how well the model would generalize to more diverse real-world environments and motions. Additionally, the paper does not address potential privacy concerns around the use of detailed 3D human models, which could raise ethical issues.
Further research could explore techniques to improve the model's robustness, as well as investigate ways to ensure the ethical deployment of such technology. Overall, SurMo represents an exciting advance in dynamic human rendering, but there remain opportunities to build upon this work.
Conclusion
SurMo introduces a novel surface-based approach to 4D motion modeling that can enable highly realistic digital human characters. By directly learning a parametric representation of the dynamic 3D surface, the model captures nuanced deformations of the skin and clothing that are crucial for lifelike rendering. While the technical details and evaluations are comprehensive, the paper also points to important areas for future research to address potential limitations and ethical considerations.
The development of methods like SurMo could have a significant impact on fields like virtual reality, video game development, and digital entertainment, allowing for the creation of more immersive and believable virtual experiences. As this technology continues to advance, it will be important to thoughtfully consider the societal implications and work to ensure it is deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Mixture of Experts Approach to 3D Human Motion Prediction
Edmund Shieh, Joshua Lee Franco, Kang Min Bae, Tej Lalvani
0
0
This project addresses the challenge of human motion prediction, a critical area for applications such as au- tonomous vehicle movement detection. Previous works have emphasized the need for low inference times to provide real time performance for applications like these. Our primary objective is to critically evaluate existing model ar- chitectures, identifying their advantages and opportunities for improvement by replicating the state-of-the-art (SOTA) Spatio-Temporal Transformer model as best as possible given computational con- straints. These models have surpassed the limitations of RNN-based models and have demonstrated the ability to generate plausible motion sequences over both short and long term horizons through the use of spatio-temporal rep- resentations. We also propose a novel architecture to ad- dress challenges of real time inference speed by incorpo- rating a Mixture of Experts (MoE) block within the Spatial- Temporal (ST) attention layer. The particular variation that is used is Soft MoE, a fully-differentiable sparse Transformer that has shown promising ability to enable larger model capacity at lower inference cost. We make out code publicly available at https://github.com/edshieh/motionprediction
5/13/2024
🤖
MOSS: Motion-based 3D Clothed Human Synthesis from Monocular Video
Hongsheng Wang, Xiang Cai, Xi Sun, Jinhong Yue, Zhanyun Tang, Shengyu Zhang, Feng Lin, Fei Wu
0
0
Single-view clothed human reconstruction holds a central position in virtual reality applications, especially in contexts involving intricate human motions. It presents notable challenges in achieving realistic clothing deformation. Current methodologies often overlook the influence of motion on surface deformation, resulting in surfaces lacking the constraints imposed by global motion. To overcome these limitations, we introduce an innovative framework, Motion-Based 3D Clo}thed Humans Synthesis (MOSS), which employs kinematic information to achieve motion-aware Gaussian split on the human surface. Our framework consists of two modules: Kinematic Gaussian Locating Splatting (KGAS) and Surface Deformation Detector (UID). KGAS incorporates matrix-Fisher distribution to propagate global motion across the body surface. The density and rotation factors of this distribution explicitly control the Gaussians, thereby enhancing the realism of the reconstructed surface. Additionally, to address local occlusions in single-view, based on KGAS, UID identifies significant surfaces, and geometric reconstruction is performed to compensate for these deformations. Experimental results demonstrate that MOSS achieves state-of-the-art visual quality in 3D clothed human synthesis from monocular videos. Notably, we improve the Human NeRF and the Gaussian Splatting by 33.94% and 16.75% in LPIPS* respectively. Codes are available at https://wanghongsheng01.github.io/MOSS/.
6/26/2024
🔮
Multimodal Sense-Informed Prediction of 3D Human Motions
Zhenyu Lou, Qiongjie Cui, Haofan Wang, Xu Tang, Hong Zhou
0
0
Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
5/7/2024
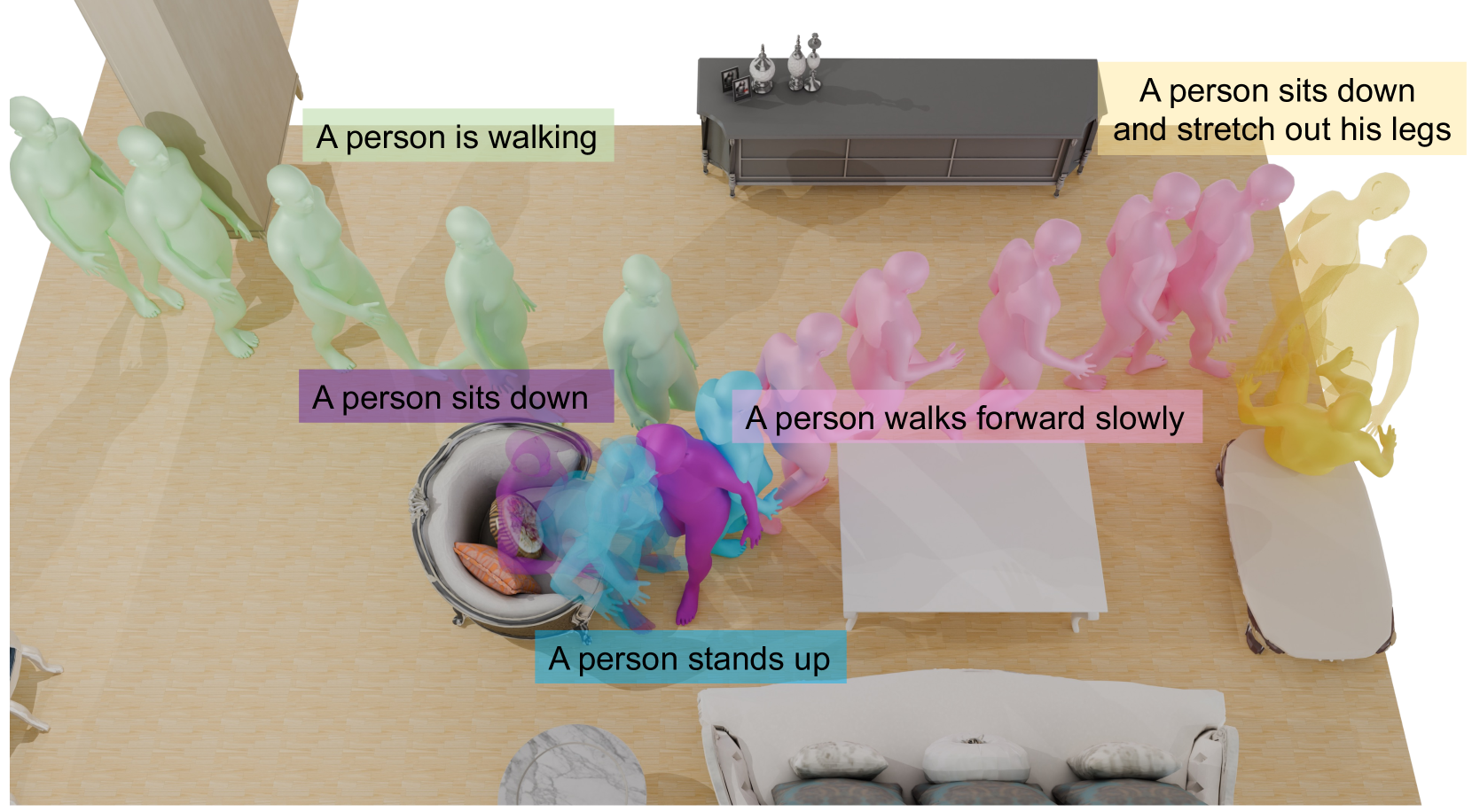
Generating Human Interaction Motions in Scenes with Text Control
Hongwei Yi, Justus Thies, Michael J. Black, Xue Bin Peng, Davis Rempe
0
0
We present TeSMo, a method for text-controlled scene-aware motion generation based on denoising diffusion models. Previous text-to-motion methods focus on characters in isolation without considering scenes due to the limited availability of datasets that include motion, text descriptions, and interactive scenes. Our approach begins with pre-training a scene-agnostic text-to-motion diffusion model, emphasizing goal-reaching constraints on large-scale motion-capture datasets. We then enhance this model with a scene-aware component, fine-tuned using data augmented with detailed scene information, including ground plane and object shapes. To facilitate training, we embed annotated navigation and interaction motions within scenes. The proposed method produces realistic and diverse human-object interactions, such as navigation and sitting, in different scenes with various object shapes, orientations, initial body positions, and poses. Extensive experiments demonstrate that our approach surpasses prior techniques in terms of the plausibility of human-scene interactions, as well as the realism and variety of the generated motions. Code will be released upon publication of this work at https://research.nvidia.com/labs/toronto-ai/tesmo.
4/17/2024