A Survey on Large Language Model-Based Game Agents
2404.02039
0
0
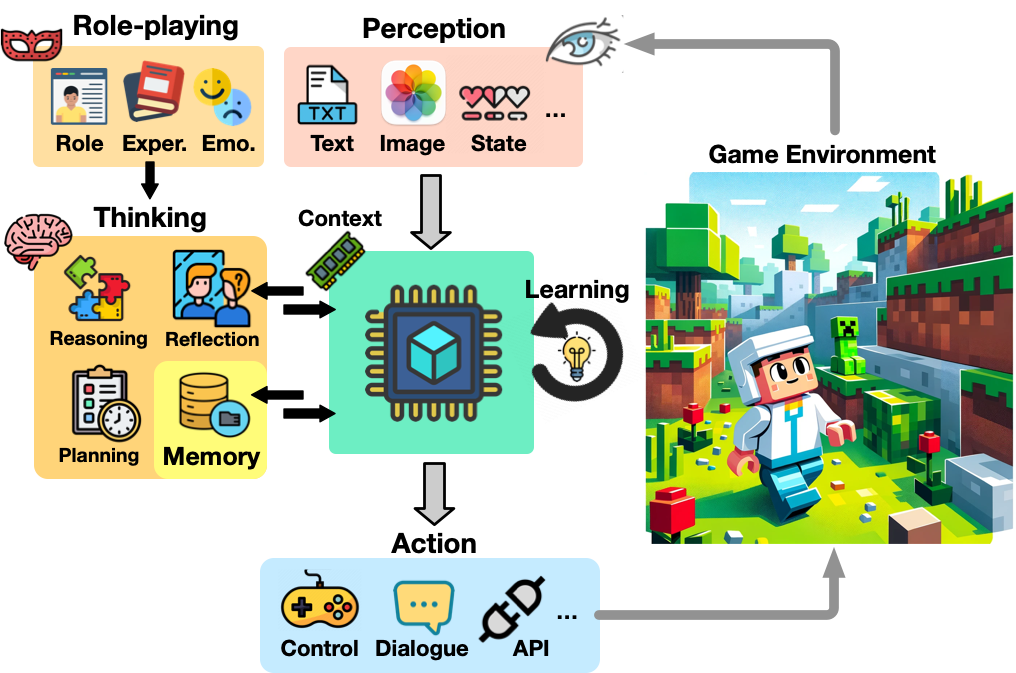
Abstract
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a survey on large language model-based game agents (LLMGAs), which are AI systems that leverage large language models to play video games.
- The authors propose a unified architecture for designing and implementing LLMGAs, covering key components such as perception, reasoning, and action.
- The paper also reviews existing work on LLMGAs, highlighting their capabilities, limitations, and potential future directions.
Plain English Explanation
Large language models are powerful AI systems that can understand and generate human-like text. Researchers are now exploring ways to use these models to create intelligent game agents that can perceive, reason about, and interact with game environments, just like human players would.
The key idea behind LLMGAs is to leverage the impressive language understanding and generation capabilities of large language models to enable game agents to communicate, plan, and make decisions in complex game worlds. Instead of relying on hard-coded rules or specialized algorithms, these agents can draw on the broad knowledge and flexible reasoning skills of large language models to tackle a wide range of game-related tasks.
By designing a unified architecture for LLMGAs, the researchers aim to provide a common framework for developing these intelligent game agents. This architecture outlines the essential components, such as perception (how the agent senses the game state), reasoning (how the agent understands the game situation and formulates strategies), and action (how the agent interacts with the game environment). With this framework, developers can more easily build and evaluate different LLMGA systems, ultimately advancing the state of the art in this emerging field.
Technical Explanation
The paper proposes a unified architecture for designing and implementing LLMGAs, which consists of three key components:
-
Perception: This module is responsible for translating the game environment into a format that can be understood by the large language model. This may involve processing visual, auditory, or textual information about the game state.
-
Reasoning: The reasoning component uses the large language model to comprehend the current game situation, generate possible actions, and select the most appropriate response. This may involve question answering, language generation, or other advanced language processing capabilities.
-
Action: The action component takes the agent's chosen response and translates it into the appropriate game actions, such as moving the character, attacking an enemy, or communicating with other players.
The authors review several existing LLMGA systems, highlighting their unique approaches to perception, reasoning, and action. They also discuss the capabilities and limitations of these systems, such as their ability to understand complex game mechanics, their robustness to unexpected situations, and their scalability to different game genres.
Critical Analysis
The paper provides a thorough and well-structured overview of the emerging field of LLMGAs, but it also acknowledges several important caveats and areas for further research:
- The authors note that current LLMGA systems are still limited in their ability to handle the full complexity of real-world game environments, which often involve dynamic, multi-agent interactions and require deep strategic reasoning.
- They also highlight the potential for LLMGAs to exhibit biases or inconsistencies inherited from the training data of the underlying large language models, which could lead to unexpected or undesirable behaviors in game agents.
- Additionally, the paper suggests that more work is needed to improve the interpretability and explainability of LLMGA decision-making, as well as to ensure the safe and ethical deployment of these systems in interactive game environments.
Overall, the paper serves as a valuable resource for researchers and developers interested in leveraging large language models for game agent design. By outlining a unified architecture and reviewing the current state of the art, the authors lay the groundwork for future advancements in this exciting and rapidly evolving field.
Conclusion
This survey paper provides a comprehensive overview of the emerging field of large language model-based game agents (LLMGAs). By proposing a unified architecture and reviewing existing LLMGA systems, the authors demonstrate the potential of leveraging powerful language models to create intelligent game agents that can perceive, reason about, and interact with complex game environments.
While current LLMGA systems show promising capabilities, the paper also highlights important challenges and limitations that need to be addressed, such as handling the full complexity of real-world games, mitigating biases, and ensuring the safe and ethical deployment of these technologies. As the field of LLMGAs continues to evolve, addressing these issues will be crucial for unlocking the full potential of large language models in game agent design and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
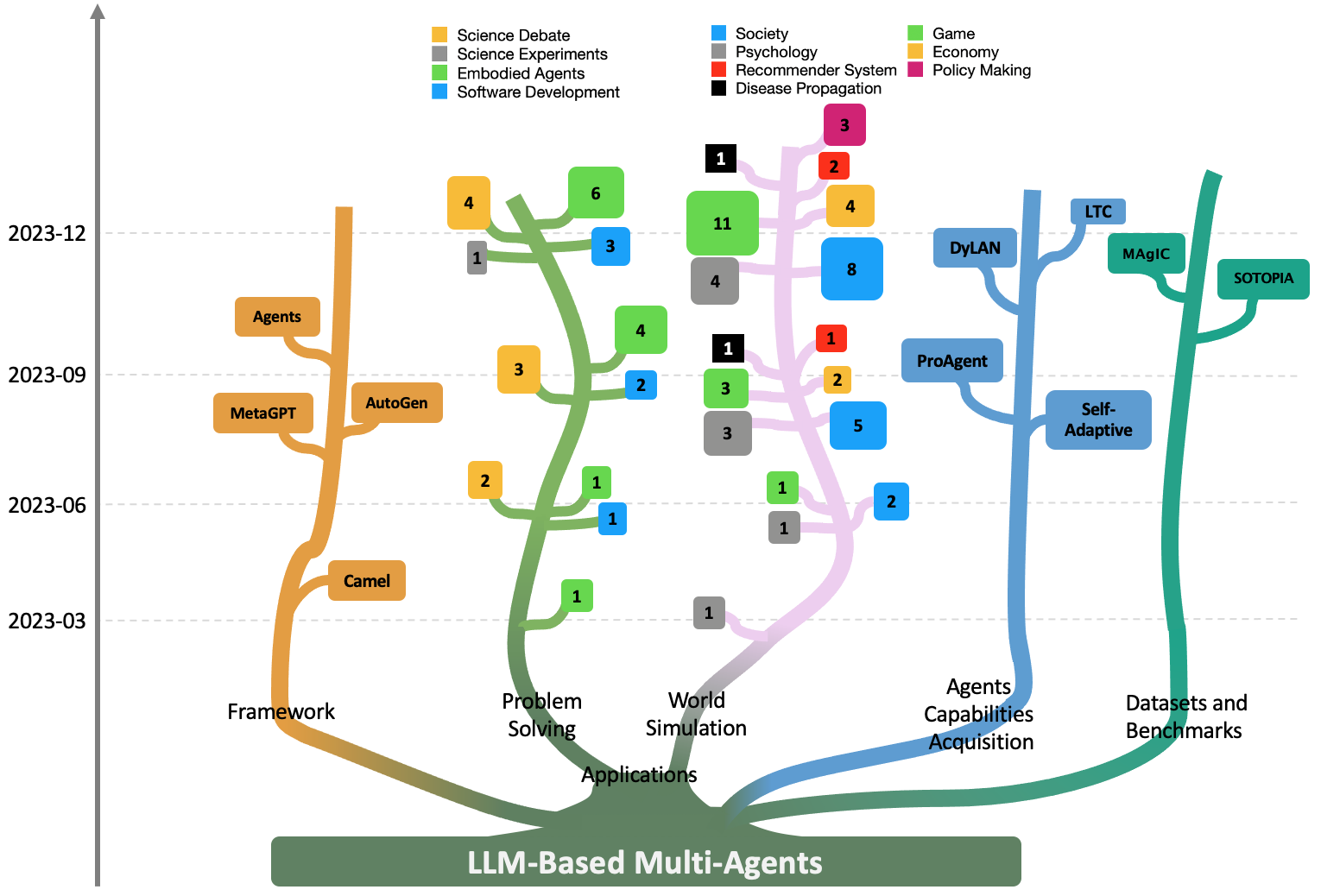
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
0
0
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
4/22/2024
💬
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen
0
0
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.
4/5/2024
Exploring Autonomous Agents through the Lens of Large Language Models: A Review
Saikat Barua
0
0
Large Language Models (LLMs) are transforming artificial intelligence, enabling autonomous agents to perform diverse tasks across various domains. These agents, proficient in human-like text comprehension and generation, have the potential to revolutionize sectors from customer service to healthcare. However, they face challenges such as multimodality, human value alignment, hallucinations, and evaluation. Techniques like prompting, reasoning, tool utilization, and in-context learning are being explored to enhance their capabilities. Evaluation platforms like AgentBench, WebArena, and ToolLLM provide robust methods for assessing these agents in complex scenarios. These advancements are leading to the development of more resilient and capable autonomous agents, anticipated to become integral in our digital lives, assisting in tasks from email responses to disease diagnosis. The future of AI, with LLMs at the forefront, is promising.
4/9/2024
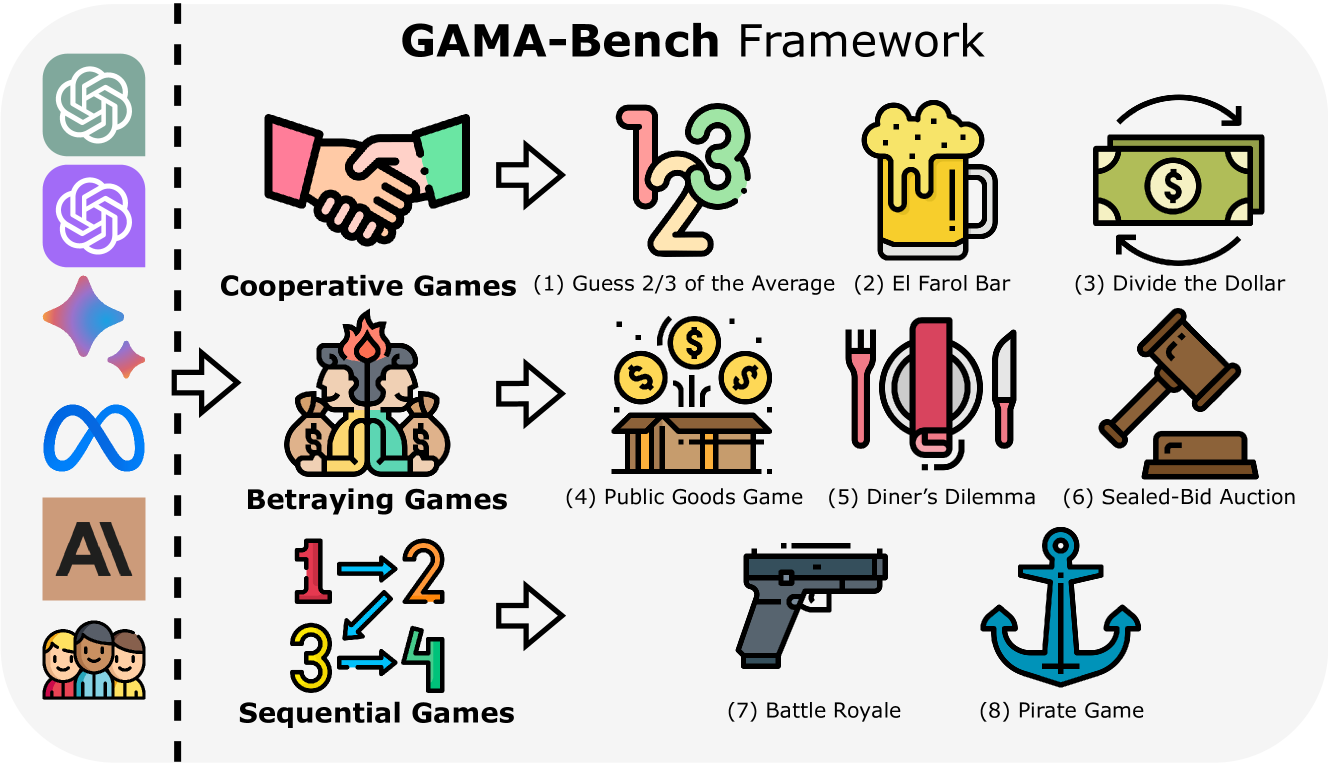
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
0
0
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates LLMs' decision-making capabilities through the lens of a well-established field, Game Theory. We focus specifically on games that support the participation of more than two agents simultaneously. Subsequently, we introduce our framework, GAMA-Bench, including eight classical multi-agent games. We design a scoring scheme to assess a model's performance in these games quantitatively. Through GAMA-Bench, we investigate LLMs' robustness, generalizability, and enhancement strategies. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we conduct evaluations across various LLMs and find that GPT-4 outperforms other models on GAMA-Bench, achieving a score of 60.5. Moreover, Gemini-1.0-Pro and GPT-3.5 (0613, 1106, 0125) demonstrate similar intelligence on GAMA-Bench. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
4/26/2024