Synergistic Integration of Coordinate Network and Tensorial Feature for Improving Neural Radiance Fields from Sparse Inputs
2405.07857
0
0
🌐
Abstract
The multi-plane representation has been highlighted for its fast training and inference across static and dynamic neural radiance fields. This approach constructs relevant features via projection onto learnable grids and interpolating adjacent vertices. However, it has limitations in capturing low-frequency details and tends to overuse parameters for low-frequency features due to its bias toward fine details, despite its multi-resolution concept. This phenomenon leads to instability and inefficiency when training poses are sparse. In this work, we propose a method that synergistically integrates multi-plane representation with a coordinate-based MLP network known for strong bias toward low-frequency signals. The coordinate-based network is responsible for capturing low-frequency details, while the multi-plane representation focuses on capturing fine-grained details. We demonstrate that using residual connections between them seamlessly preserves their own inherent properties. Additionally, the proposed progressive training scheme accelerates the disentanglement of these two features. We demonstrate empirically that our proposed method not only outperforms baseline models for both static and dynamic NeRFs with sparse inputs, but also achieves comparable results with fewer parameters.
Create account to get full access
Overview
- This paper introduces a new approach for capturing details in neural radiance fields (NeRFs) that combines a multi-plane representation with a coordinate-based network.
- The multi-plane representation is known for its fast training and inference, but it struggles to capture low-frequency details.
- The coordinate-based network is good at capturing low-frequency signals, but it tends to overuse parameters.
- The proposed method integrates these two components using residual connections to leverage their respective strengths and overcome their individual limitations.
- The authors also introduce a progressive training scheme to accelerate the disentanglement of low and high-frequency features.
Plain English Explanation
The paper tackles the challenge of efficiently representing neural radiance fields (NeRFs), which are a powerful way to model 3D scenes. NeRFs can capture fine details, but they can struggle when the input data is sparse, like when there are only a few camera views.
The authors propose a new approach that combines two different techniques: a multi-plane representation and a coordinate-based network. The multi-plane representation is good at capturing high-frequency details, but it has trouble with low-frequency information. The coordinate-based network, on the other hand, is better at capturing low-frequency signals, but it can be inefficient.
By putting these two techniques together and using residual connections between them, the authors create a system that can effectively represent both low and high-frequency details. They also use a progressive training scheme to help the model learn these different types of features more efficiently.
The end result is a method that can produce high-quality NeRF reconstructions, even when the input data is sparse. This could be useful for applications like capturing 3D scenes from limited camera views.
Technical Explanation
The paper introduces a new approach for constructing neural radiance fields (NeRFs) that combines a multi-plane representation with a coordinate-based network. The multi-plane representation is known for its fast training and inference, as it constructs relevant features by projecting them onto learnable grids and interpolating adjacent vertices. However, this approach has limitations in capturing low-frequency details and tends to overuse parameters for low-frequency features due to its bias toward fine details, despite its multi-resolution concept.
To address these limitations, the authors propose a method that synergistically integrates the multi-plane representation with a coordinate-based network, which is known for its strong bias toward low-frequency signals. The coordinate-based network is responsible for capturing low-frequency details, while the multi-plane representation focuses on capturing fine-grained details. The authors demonstrate that using residual connections between these two components seamlessly preserves their inherent properties.
Additionally, the authors introduce a progressive training scheme that accelerates the disentanglement of low and high-frequency features. This scheme helps the model learn to efficiently represent both types of features, which is particularly important when the input data is sparse, as is the case in many real-world scenarios.
The authors empirically show that the proposed method achieves comparable results to explicit encoding with fewer parameters, and it outperforms other approaches, especially for static and dynamic NeRFs under sparse input conditions.
Critical Analysis
The paper presents a compelling approach for improving the representation of neural radiance fields, particularly in scenarios with sparse input data. The integration of the multi-plane representation and the coordinate-based network is a clever way to leverage the strengths of both techniques while mitigating their individual limitations.
One potential concern is the reliance on residual connections to seamlessly combine the two components. While this approach seems to work well in practice, it would be interesting to explore alternative methods for integrating the multi-plane and coordinate-based representations, perhaps through more sophisticated fusion or gating mechanisms.
Additionally, the authors mention that the proposed method tends to overuse parameters for low-frequency features, despite the inclusion of the coordinate-based network. This suggests that there may be room for further improvements in the model architecture or training process to better balance the representation of low and high-frequency details.
It would also be valuable to see the proposed method tested on a wider range of NeRF-based applications, such as stylizing sparse-view 3D scenes or dynamic neural radiance field reconstruction, to better understand its generalization capabilities and potential limitations.
Conclusion
This paper presents a novel approach for constructing neural radiance fields that combines a multi-plane representation with a coordinate-based network. By leveraging the strengths of these two techniques and using residual connections to integrate them, the authors have developed a method that can effectively capture both low and high-frequency details, even in the presence of sparse input data.
The proposed progressive training scheme further enhances the model's ability to disentangle these different types of features, leading to improved efficiency and stability during the training process. This work represents an important step forward in the field of neural radiance field modeling, with potential applications in a variety of 3D reconstruction and rendering tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
JointRF: End-to-End Joint Optimization for Dynamic Neural Radiance Field Representation and Compression
Zihan Zheng, Houqiang Zhong, Qiang Hu, Xiaoyun Zhang, Li Song, Ya Zhang, Yanfeng Wang
0
0
Neural Radiance Field (NeRF) excels in photo-realistically static scenes, inspiring numerous efforts to facilitate volumetric videos. However, rendering dynamic and long-sequence radiance fields remains challenging due to the significant data required to represent volumetric videos. In this paper, we propose a novel end-to-end joint optimization scheme of dynamic NeRF representation and compression, called JointRF, thus achieving significantly improved quality and compression efficiency against the previous methods. Specifically, JointRF employs a compact residual feature grid and a coefficient feature grid to represent the dynamic NeRF. This representation handles large motions without compromising quality while concurrently diminishing temporal redundancy. We also introduce a sequential feature compression subnetwork to further reduce spatial-temporal redundancy. Finally, the representation and compression subnetworks are end-to-end trained combined within the JointRF. Extensive experiments demonstrate that JointRF can achieve superior compression performance across various datasets.
6/11/2024
👁️
Simple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Nagabhushan Somraj, Sai Harsha Mupparaju, Adithyan Karanayil, Rajiv Soundararajan
0
0
Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^circ$ scenes by employing the above regularizations.
5/28/2024

Neural NeRF Compression
Tuan Pham, Stephan Mandt
0
0
Neural Radiance Fields (NeRFs) have emerged as powerful tools for capturing detailed 3D scenes through continuous volumetric representations. Recent NeRFs utilize feature grids to improve rendering quality and speed; however, these representations introduce significant storage overhead. This paper presents a novel method for efficiently compressing a grid-based NeRF model, addressing the storage overhead concern. Our approach is based on the non-linear transform coding paradigm, employing neural compression for compressing the model's feature grids. Due to the lack of training data involving many i.i.d scenes, we design an encoder-free, end-to-end optimized approach for individual scenes, using lightweight decoders. To leverage the spatial inhomogeneity of the latent feature grids, we introduce an importance-weighted rate-distortion objective and a sparse entropy model employing a masking mechanism. Our experimental results validate that our proposed method surpasses existing works in terms of grid-based NeRF compression efficacy and reconstruction quality.
6/14/2024
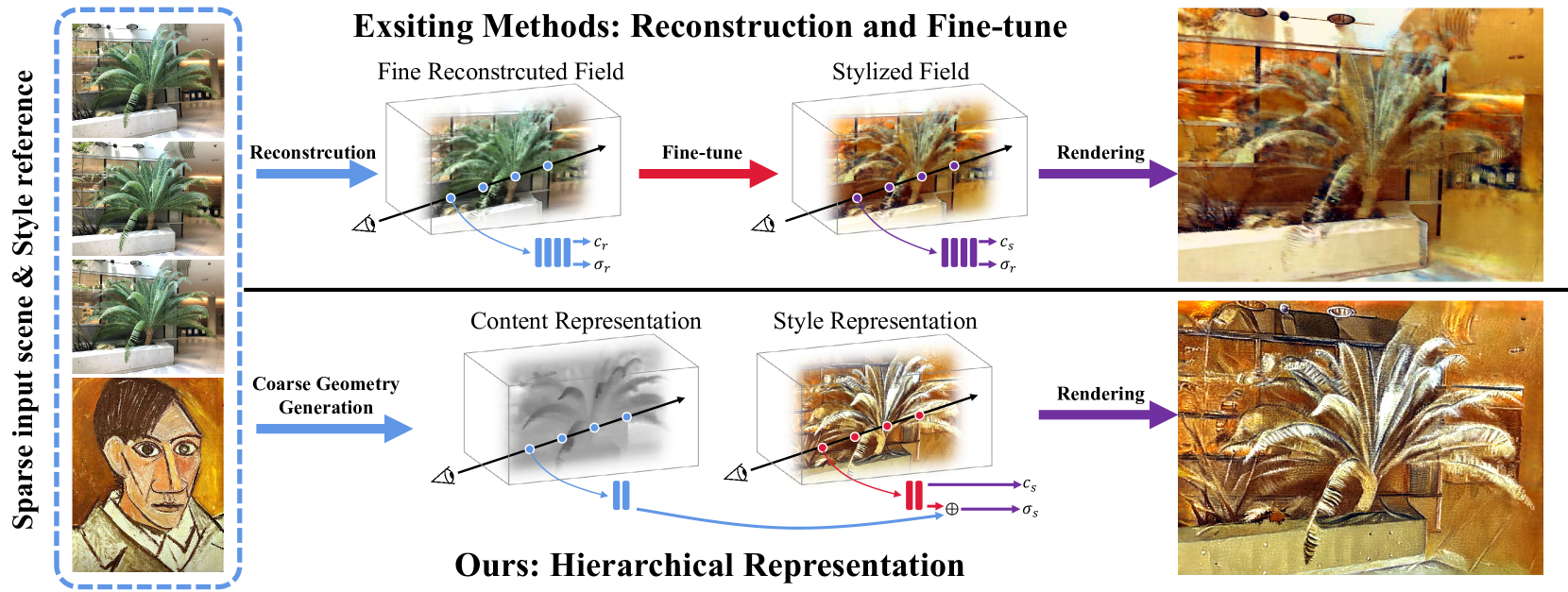
Stylizing Sparse-View 3D Scenes with Hierarchical Neural Representation
Y. Wang, A. Gao, Y. Gong, Y. Zeng
0
0
Recently, a surge of 3D style transfer methods has been proposed that leverage the scene reconstruction power of a pre-trained neural radiance field (NeRF). To successfully stylize a scene this way, one must first reconstruct a photo-realistic radiance field from collected images of the scene. However, when only sparse input views are available, pre-trained few-shot NeRFs often suffer from high-frequency artifacts, which are generated as a by-product of high-frequency details for improving reconstruction quality. Is it possible to generate more faithful stylized scenes from sparse inputs by directly optimizing encoding-based scene representation with target style? In this paper, we consider the stylization of sparse-view scenes in terms of disentangling content semantics and style textures. We propose a coarse-to-fine sparse-view scene stylization framework, where a novel hierarchical encoding-based neural representation is designed to generate high-quality stylized scenes directly from implicit scene representations. We also propose a new optimization strategy with content strength annealing to achieve realistic stylization and better content preservation. Extensive experiments demonstrate that our method can achieve high-quality stylization of sparse-view scenes and outperforms fine-tuning-based baselines in terms of stylization quality and efficiency.
4/9/2024