Synthesizing Multimodal Electronic Health Records via Predictive Diffusion Models
2406.13942
0
0
Abstract
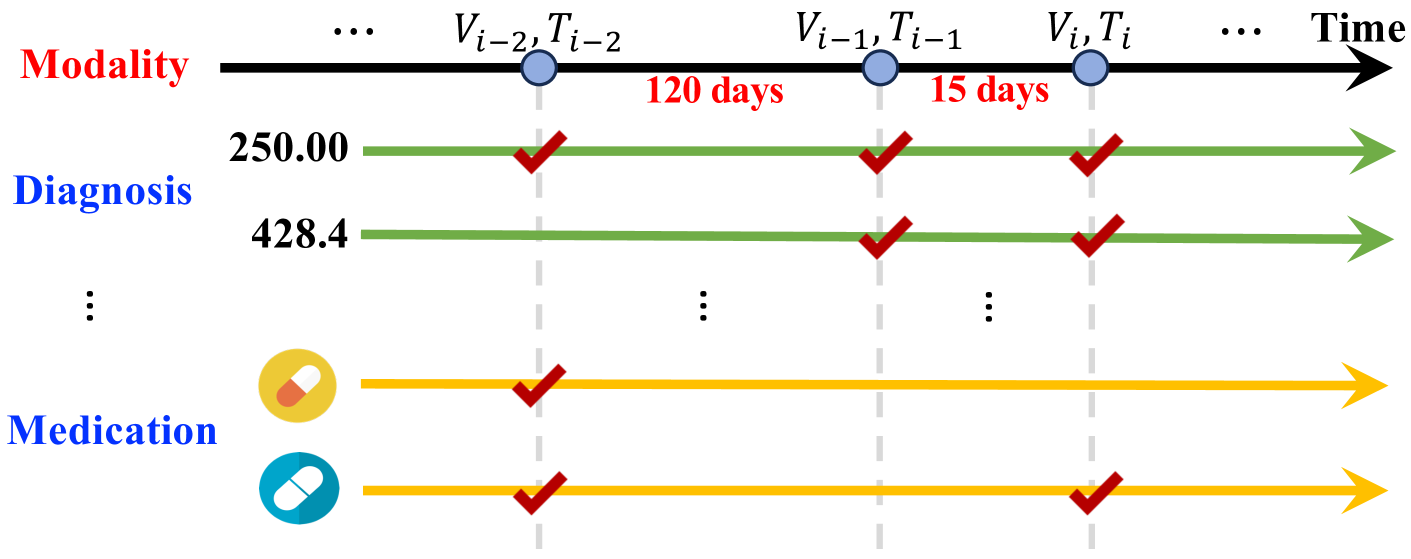
Synthesizing electronic health records (EHR) data has become a preferred strategy to address data scarcity, improve data quality, and model fairness in healthcare. However, existing approaches for EHR data generation predominantly rely on state-of-the-art generative techniques like generative adversarial networks, variational autoencoders, and language models. These methods typically replicate input visits, resulting in inadequate modeling of temporal dependencies between visits and overlooking the generation of time information, a crucial element in EHR data. Moreover, their ability to learn visit representations is limited due to simple linear mapping functions, thus compromising generation quality. To address these limitations, we propose a novel EHR data generation model called EHRPD. It is a diffusion-based model designed to predict the next visit based on the current one while also incorporating time interval estimation. To enhance generation quality and diversity, we introduce a novel time-aware visit embedding module and a pioneering predictive denoising diffusion probabilistic model (PDDPM). Additionally, we devise a predictive U-Net (PU-Net) to optimize P-DDPM.We conduct experiments on two public datasets and evaluate EHRPD from fidelity, privacy, and utility perspectives. The experimental results demonstrate the efficacy and utility of the proposed EHRPD in addressing the aforementioned limitations and advancing EHR data generation.
Create account to get full access
Overview
- This paper presents a novel approach to synthesizing realistic and diverse multimodal electronic health records (EHRs) using predictive diffusion models.
- The proposed method aims to address the challenge of generating high-quality synthetic EHR data that can be used for tasks such as medical code prediction, temporal health modeling, and other healthcare applications.
- The authors leverage the capabilities of diffusion models, which are a class of generative models that have shown promising results in various domains, to generate realistic multimodal EHR data.
Plain English Explanation
Electronic health records (EHRs) contain a wealth of information about patients' medical history, treatments, and outcomes. However, access to real EHR data is often restricted due to privacy concerns. To address this, the researchers in this paper developed a way to generate synthetic EHR data that maintains the key characteristics and patterns of real data, but without using any actual patient information.
The core idea is to use a type of machine learning model called a "diffusion model." Diffusion models are trained on real data and then used to generate new, realistic-looking data that has similar properties to the original. In this case, the researchers trained their diffusion model on a large dataset of real EHR data, which includes information like a patient's diagnosis, medications, lab results, and other medical details.
By using this diffusion modeling approach, the researchers were able to create synthetic EHR data that looks and behaves very similar to real patient records, but without containing any identifiable information about actual individuals. This synthetic data can then be used by researchers and healthcare organizations for tasks like predicting future medical codes, modeling how patient health changes over time, and other important applications in the field of healthcare.
The advantage of this approach is that it allows for the development of more advanced AI models and analyses, without running into privacy and ethical concerns associated with using real patient data. By generating realistic synthetic data, the researchers hope to unlock new opportunities for innovation and progress in the healthcare domain.
Technical Explanation
The key technical contributions of this paper are:
-
Multimodal EHR Synthesis: The authors propose a framework for synthesizing diverse and realistic multimodal EHR data using predictive diffusion models. This goes beyond previous work that has focused on generating more limited types of EHR data, such as text-only medical notes or temporal health information.
-
Diffusion Model Architecture: The researchers design a novel diffusion model architecture that can effectively capture the complex dependencies and distributions present in multimodal EHR data. This includes modeling the intricate relationships between different medical modalities, such as diagnoses, medications, and lab results.
-
Conditional Synthesis: The proposed framework allows for conditional synthesis of EHR data, where the generation process can be guided by specific attributes or clinical information. This enables the creation of synthetic data that aligns with particular medical conditions, patient demographics, or other relevant factors.
-
Evaluation: The authors conduct extensive experiments to validate the quality and utility of the synthesized EHR data. They demonstrate that the generated data closely matches the statistical properties and clinical plausibility of real-world EHR data, making it suitable for a variety of downstream healthcare applications.
The core technical approach involves training a conditional diffusion model on a large EHR dataset, which captures the complex multimodal relationships present in the data. During the generation process, the model is conditioned on various clinical factors to produce synthetic EHR samples that exhibit the desired characteristics. The authors show that this approach outperforms alternative generative modeling techniques, such as generative adversarial networks, in terms of the realism and diversity of the generated data.
Critical Analysis
One potential limitation of this work is the reliance on a single, large-scale EHR dataset for training the diffusion model. The researchers acknowledge that the generalizability of the approach may be affected by the specific characteristics and biases present in the dataset used. Evaluating the framework's performance on a wider range of EHR data sources, including those from different healthcare systems or geographic regions, could provide a more comprehensive understanding of its capabilities and limitations.
Additionally, while the authors demonstrate the clinical plausibility of the generated EHR data, there may be subtle nuances or domain-specific patterns that are not fully captured by the current model. Further research could explore techniques to better preserve the fine-grained details and complex dependencies present in real-world EHR data, potentially by incorporating additional domain knowledge or incorporating advanced diffusion model architectures.
It is also worth noting that the ethical and privacy implications of synthetic data generation in the healthcare domain warrant careful consideration. The authors discuss the potential benefits of using synthetic EHR data for research and development, but it is essential to ensure that appropriate safeguards and governance frameworks are in place to prevent any misuse or unintended consequences.
Conclusion
This paper presents an innovative approach to synthesizing realistic and diverse multimodal electronic health records using predictive diffusion models. By leveraging the capabilities of diffusion models, the researchers have developed a framework that can generate high-quality synthetic EHR data, which can be used to support a wide range of healthcare applications, such as medical code prediction, temporal health modeling, and others.
The ability to create synthetic EHR data that maintains the key characteristics and patterns of real-world data, while ensuring patient privacy, is a significant advancement in the field of healthcare data generation and analysis. This work paves the way for further research and innovation in the development of more robust and inclusive AI-powered healthcare solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Guided Discrete Diffusion for Electronic Health Record Generation
Jun Han, Zixiang Chen, Yongqian Li, Yiwen Kou, Eran Halperin, Robert E. Tillman, Quanquan Gu
0
0
Electronic health records (EHRs) are a pivotal data source that enables numerous applications in computational medicine, e.g., disease progression prediction, clinical trial design, and health economics and outcomes research. Despite wide usability, their sensitive nature raises privacy and confidentially concerns, which limit potential use cases. To tackle these challenges, we explore the use of generative models to synthesize artificial, yet realistic EHRs. While diffusion-based methods have recently demonstrated state-of-the-art performance in generating other data modalities and overcome the training instability and mode collapse issues that plague previous GAN-based approaches, their applications in EHR generation remain underexplored. The discrete nature of tabular medical code data in EHRs poses challenges for high-quality data generation, especially for continuous diffusion models. To this end, we introduce a novel tabular EHR generation method, EHR-D3PM, which enables both unconditional and conditional generation using the discrete diffusion model. Our experiments demonstrate that EHR-D3PM significantly outperforms existing generative baselines on comprehensive fidelity and utility metrics while maintaining less attribute and membership vulnerability risks. Furthermore, we show EHR-D3PM is effective as a data augmentation method and enhances performance on downstream tasks when combined with real data.
6/18/2024
🔮
Time-aware Heterogeneous Graph Transformer with Adaptive Attention Merging for Health Event Prediction
Shibo Li, Hengliang Cheng, Weihua Li
0
0
The widespread application of Electronic Health Records (EHR) data in the medical field has led to early successes in disease risk prediction using deep learning methods. These methods typically require extensive data for training due to their large parameter sets. However, existing works do not exploit the full potential of EHR data. A significant challenge arises from the infrequent occurrence of many medical codes within EHR data, limiting their clinical applicability. Current research often lacks in critical areas: 1) incorporating disease domain knowledge; 2) heterogeneously learning disease representations with rich meanings; 3) capturing the temporal dynamics of disease progression. To overcome these limitations, we introduce a novel heterogeneous graph learning model designed to assimilate disease domain knowledge and elucidate the intricate relationships between drugs and diseases. This model innovatively incorporates temporal data into visit-level embeddings and leverages a time-aware transformer alongside an adaptive attention mechanism to produce patient representations. When evaluated on two healthcare datasets, our approach demonstrated notable enhancements in both prediction accuracy and interpretability over existing methodologies, signifying a substantial advancement towards personalized and proactive healthcare management.
5/13/2024
CEHR-GPT: Generating Electronic Health Records with Chronological Patient Timelines
Chao Pang, Xinzhuo Jiang, Nishanth Parameshwar Pavinkurve, Krishna S. Kalluri, Elise L. Minto, Jason Patterson, Linying Zhang, George Hripcsak, Gamze Gursoy, No'emie Elhadad, Karthik Natarajan
0
0
Synthetic Electronic Health Records (EHR) have emerged as a pivotal tool in advancing healthcare applications and machine learning models, particularly for researchers without direct access to healthcare data. Although existing methods, like rule-based approaches and generative adversarial networks (GANs), generate synthetic data that resembles real-world EHR data, these methods often use a tabular format, disregarding temporal dependencies in patient histories and limiting data replication. Recently, there has been a growing interest in leveraging Generative Pre-trained Transformers (GPT) for EHR data. This enables applications like disease progression analysis, population estimation, counterfactual reasoning, and synthetic data generation. In this work, we focus on synthetic data generation and demonstrate the capability of training a GPT model using a particular patient representation derived from CEHR-BERT, enabling us to generate patient sequences that can be seamlessly converted to the Observational Medical Outcomes Partnership (OMOP) data format.
5/7/2024

Next Visit Diagnosis Prediction via Medical Code-Centric Multimodal Contrastive EHR Modelling with Hierarchical Regularisation
Heejoon Koo
0
0
Predicting next visit diagnosis using Electronic Health Records (EHR) is an essential task in healthcare, critical for devising proactive future plans for both healthcare providers and patients. Nonetheless, many preceding studies have not sufficiently addressed the heterogeneous and hierarchical characteristics inherent in EHR data, inevitably leading to sub-optimal performance. To this end, we propose NECHO, a novel medical code-centric multimodal contrastive EHR learning framework with hierarchical regularisation. First, we integrate multifaceted information encompassing medical codes, demographics, and clinical notes using a tailored network design and a pair of bimodal contrastive losses, all of which pivot around a medical codes representation. We also regularise modality-specific encoders using a parental level information in medical ontology to learn hierarchical structure of EHR data. A series of experiments on MIMIC-III data demonstrates effectiveness of our approach.
5/2/2024