T-RAG: Lessons from the LLM Trenches
2402.07483
0
0
↗️
Abstract
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
Create account to get full access
Overview
- Large language models (LLMs) have shown impressive language abilities, leading to attempts to integrate them into various applications.
- An important application area is question answering over private enterprise documents, which raises considerations around data security, limited computational resources, and the need for a robust system.
- Retrieval-Augmented Generation (RAG) has emerged as a prominent framework for building LLM-based applications, but building a reliable RAG application requires significant customization and domain knowledge.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform impressive language tasks, such as answering questions or generating human-like text. Researchers have been exploring ways to integrate these LLMs into real-world applications, particularly for answering questions about private company documents.
This is a valuable application, as companies often have sensitive information that they need to share with employees or customers. However, there are some challenges to overcome. First, the information needs to be kept secure, so the application needs to be able to run on the company's own servers rather than in the cloud. Second, the company might not have a lot of computing power available, so the application needs to be efficient. Third, the application needs to be able to reliably answer questions correctly, without making mistakes.
The Retrieval-Augmented Generation (RAG) framework has been one of the most popular ways to build LLM-based applications like this. RAG allows the LLM to access relevant information from a database when answering questions. However, making a RAG application that is truly robust and reliable requires a lot of customization and a deep understanding of the specific domain (in this case, the company's documents and information).
Technical Explanation
The researchers in this paper share their experiences building and deploying an LLM-based question-answering application for private organizational documents. Their system, called Tree-RAG (T-RAG), combines the use of the RAG framework with a fine-tuned open-source LLM.
One key innovation in T-RAG is the use of a tree structure to represent the entity hierarchies within the organization. This tree structure is used to generate a textual description that augments the context when the system is responding to queries about entities in the organization's hierarchy.
The researchers evaluate their T-RAG system and find that it performs better than a simple RAG implementation or a fine-tuning-only approach. They also report on a "Needle in a Haystack" test, which assesses the system's ability to correctly answer queries about specific details buried in the organizational documents.
Critical Analysis
The paper provides a valuable case study on the challenges of building a reliable LLM-based application for real-world use. The researchers acknowledge that while the RAG framework is relatively straightforward to implement, making it robust and accurate requires significant customization and domain knowledge.
One potential limitation is that the evaluation is focused on a specific organizational setting. It would be interesting to see how well the T-RAG approach generalizes to other types of private documents or knowledge domains. Additionally, the paper does not provide a detailed comparison to other state-of-the-art approaches for retrieval-augmented question answering, such as the Extreme QA or Telco-RAG systems.
Nevertheless, the researchers' insights on the practical challenges of deploying LLM applications and their innovative use of entity hierarchies are valuable contributions to the field. Their work also highlights the importance of balancing technical capabilities with real-world considerations like security, efficiency, and robustness.
Conclusion
This paper shares valuable lessons learned from building and deploying an LLM-based question-answering application for private organizational documents. While LLMs have shown remarkable language abilities, integrating them into reliable, real-world applications requires careful design and extensive customization.
The researchers' T-RAG system, which combines RAG with a fine-tuned LLM and a tree-structured representation of entity hierarchies, demonstrates the potential of such hybrid approaches. As LLM applications continue to evolve, this paper provides a useful case study on the practical challenges and design considerations involved in creating robust, trustworthy systems for sensitive domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024

ERATTA: Extreme RAG for Table To Answers with Large Language Models
Sohini Roychowdhury, Marko Krema, Anvar Mahammad, Brian Moore, Arijit Mukherjee, Punit Prakashchandra
0
0
Large language models (LLMs) with retrieval augmented-generation (RAG) have been the optimal choice for scalable generative AI solutions in the recent past. However, the choice of use-cases that incorporate RAG with LLMs have been either generic or extremely domain specific, thereby questioning the scalability and generalizability of RAG-LLM approaches. In this work, we propose a unique LLM-based system where multiple LLMs can be invoked to enable data authentication, user query routing, data retrieval and custom prompting for question answering capabilities from data tables that are highly varying and large in size. Our system is tuned to extract information from Enterprise-level data products and furnish real time responses under 10 seconds. One prompt manages user-to-data authentication followed by three prompts to route, fetch data and generate a customizable prompt natural language responses. Additionally, we propose a five metric scoring module that detects and reports hallucinations in the LLM responses. Our proposed system and scoring metrics achieve >90% confidence scores across hundreds of user queries in the sustainability, financial health and social media domains. Extensions to the proposed extreme RAG architectures can enable heterogeneous source querying using LLMs.
5/15/2024
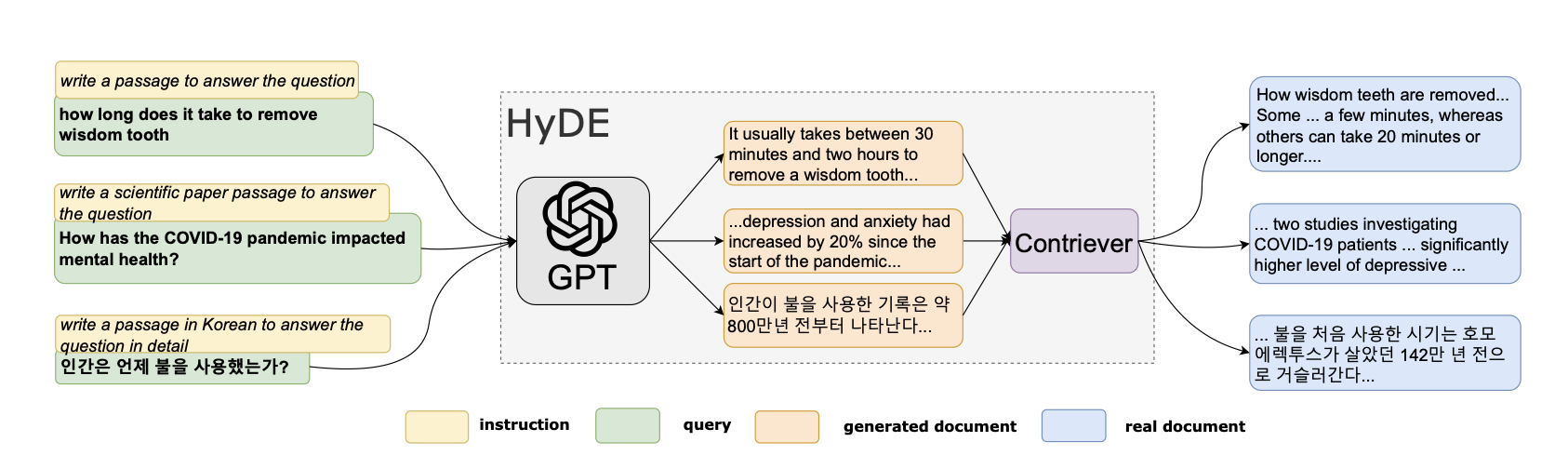
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024
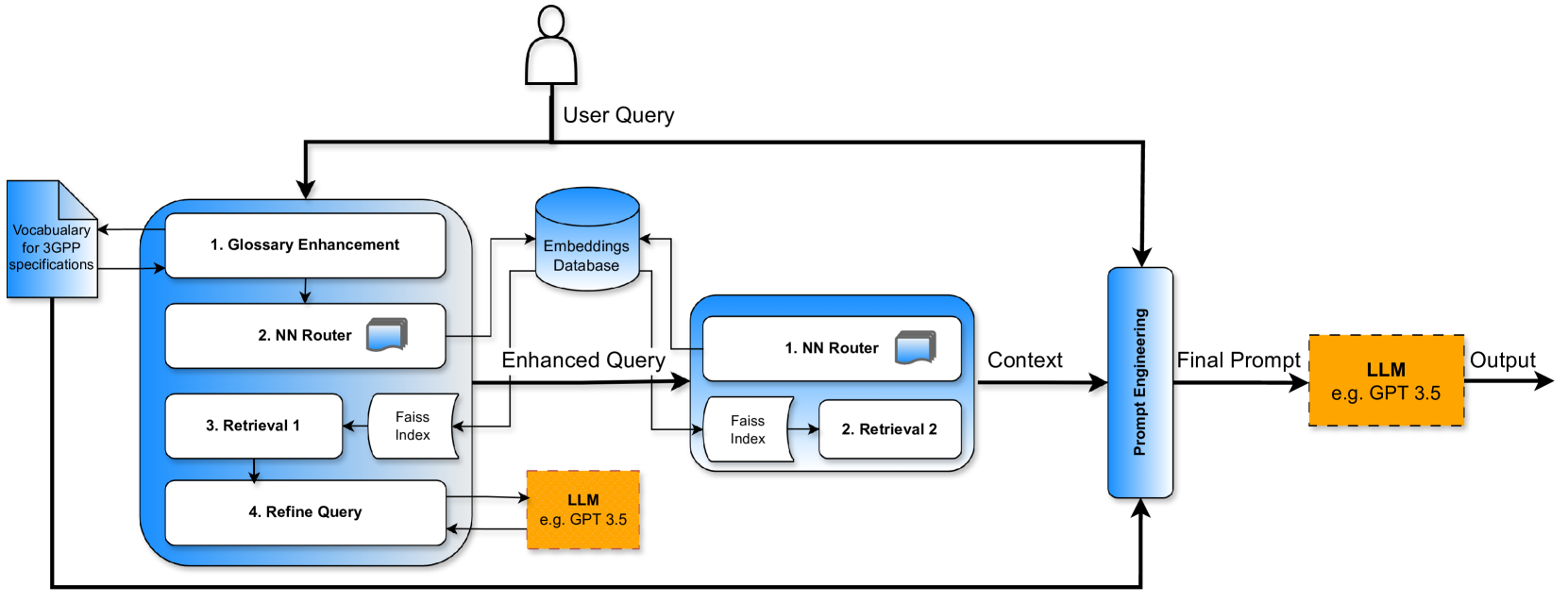
Telco-RAG: Navigating the Challenges of Retrieval-Augmented Language Models for Telecommunications
Andrei-Laurentiu Bornea, Fadhel Ayed, Antonio De Domenico, Nicola Piovesan, Ali Maatouk
0
0
The application of Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems in the telecommunication domain presents unique challenges, primarily due to the complex nature of telecom standard documents and the rapid evolution of the field. The paper introduces Telco-RAG, an open-source RAG framework designed to handle the specific needs of telecommunications standards, particularly 3rd Generation Partnership Project (3GPP) documents. Telco-RAG addresses the critical challenges of implementing a RAG pipeline on highly technical content, paving the way for applying LLMs in telecommunications and offering guidelines for RAG implementation in other technical domains.
4/29/2024