TAI++: Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt
2405.06926
0
0

Abstract
The recent introduction of prompt tuning based on pre-trained vision-language models has dramatically improved the performance of multi-label image classification. However, some existing strategies that have been explored still have drawbacks, i.e., either exploiting massive labeled visual data at a high cost or using text data only for text prompt tuning and thus failing to learn the diversity of visual knowledge. Hence, the application scenarios of these methods are limited. In this paper, we propose a pseudo-visual prompt~(PVP) module for implicit visual prompt tuning to address this problem. Specifically, we first learn the pseudo-visual prompt for each category, mining diverse visual knowledge by the well-aligned space of pre-trained vision-language models. Then, a co-learning strategy with a dual-adapter module is designed to transfer visual knowledge from pseudo-visual prompt to text prompt, enhancing their visual representation abilities. Experimental results on VOC2007, MS-COCO, and NUSWIDE datasets demonstrate that our method can surpass state-of-the-art~(SOTA) methods across various settings for multi-label image classification tasks. The code is available at https://github.com/njustkmg/PVP.
Create account to get full access
Overview
- The paper proposes a new approach called TAI++ (Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt) for multi-label image classification.
- TAI++ leverages a text-to-image model to generate image representations from input text, which are then used for multi-label image classification.
- The key innovation is the co-learning of a transferable prompt that can be used to effectively generate informative image representations from text for the target classification task.
Plain English Explanation
The researchers behind this paper have developed a new way to classify images with multiple labels using text. The core idea is to take a text description of an image and use a special model to convert that text into an image-like representation. This image-like representation can then be used to help classify the original image, even if it has multiple different objects or features in it.
The key breakthrough is the way they train the model to generate these image-like representations. They use a technique called "co-learning a transferable prompt" which allows the model to learn a specialized way of converting text into useful image features, tailored to the specific image classification task at hand. This makes the text-to-image conversion much more effective for classification compared to just using a generic text-to-image model.
By leveraging text in this way, the researchers were able to achieve better performance on multi-label image classification compared to approaches that only use the raw image data. This is an important advance, as many real-world images contain multiple relevant objects or attributes that need to be identified.
Technical Explanation
The central innovation of TAI++ is the co-learning of a transferable prompt that can be used to generate effective image representations from text for multi-label image classification. This builds on prior work on text-to-image generation and cross-modal learning, but with a focus on optimizing the text-to-image mapping specifically for the target classification task.
The TAI++ architecture consists of three main components: a text encoder, an image encoder, and a task-specific classifier. The text encoder takes the input text and generates a text embedding, which is then used to condition a text-to-image generation model. This generates an image-like representation that captures the semantic content of the text. The image encoder processes the original image, and the resulting image features are concatenated with the text-derived features before being passed to the classifier.
Crucially, the text-to-image generation model is trained end-to-end alongside the classifier, allowing the prompt used for text-to-image conversion to be optimized for the classification task through joint visual-text prompting. This "co-learning" of the transferable prompt is the key innovation that allows TAI++ to outperform approaches that use generic text-to-image models or separately trained prompt encoders.
Critical Analysis
The authors acknowledge several limitations of the TAI++ approach. First, the reliance on a text-to-image model introduces additional computational complexity and potential for errors compared to approaches that only use the raw image data. The authors also note that the performance of TAI++ is sensitive to the quality and relevance of the input text descriptions.
Additionally, the paper does not extensively explore the transparency or interpretability of the TAI++ model. It is unclear how the text-derived features are being used by the classifier, and whether the model's decision-making process can be easily understood. This is an important consideration, especially for high-stakes applications.
Further research could investigate ways to improve the efficiency and robustness of the TAI++ approach, as well as explore methods for making the model's reasoning more transparent. Additionally, comparisons to other multimodal learning and prompt-based techniques could shed more light on the relative strengths and weaknesses of the TAI++ framework.
Conclusion
The TAI++ approach represents an innovative way to leverage text information to improve multi-label image classification. By co-learning a transferable prompt for text-to-image conversion, the model is able to generate image representations that are well-suited for the target classification task. This advance could have significant implications for applications where identifying multiple relevant attributes in an image is important, such as medical diagnosis, visual search, or scene understanding.
However, the approach also raises some questions about efficiency, robustness, and interpretability that warrant further investigation. As the field of multimodal learning continues to evolve, techniques like TAI++ offer promising avenues for combining the strengths of text and image data to tackle complex visual recognition challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
Yaoqin Ye, Junjie Zhang, Hongwei Shi
0
0
The task of medical image recognition is notably complicated by the presence of varied and multiple pathological indications, presenting a unique challenge in multi-label classification with unseen labels. This complexity underlines the need for computer-aided diagnosis methods employing multi-label zero-shot learning. Recent advancements in pre-trained vision-language models (VLMs) have showcased notable zero-shot classification abilities on medical images. However, these methods have limitations on leveraging extensive pre-trained knowledge from broader image datasets, and often depend on manual prompt construction by expert radiologists. By automating the process of prompt tuning, prompt learning techniques have emerged as an efficient way to adapt VLMs to downstream tasks. Yet, existing CoOp-based strategies fall short in performing class-specific prompts on unseen categories, limiting generalizability in fine-grained scenarios. To overcome these constraints, we introduce a novel prompt generation approach inspirited by text generation in natural language processing (NLP). Our method, named Pseudo-Prompt Generating (PsPG), capitalizes on the priori knowledge of multi-modal features. Featuring a RNN-based decoder, PsPG autoregressively generates class-tailored embedding vectors, i.e., pseudo-prompts. Comparative evaluations on various multi-label chest radiograph datasets affirm the superiority of our approach against leading medical vision-language and multi-label prompt learning methods. The source code is available at https://github.com/fallingnight/PsPG
5/13/2024

ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
0
0
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a red bounding box or pointed arrow. Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
4/30/2024
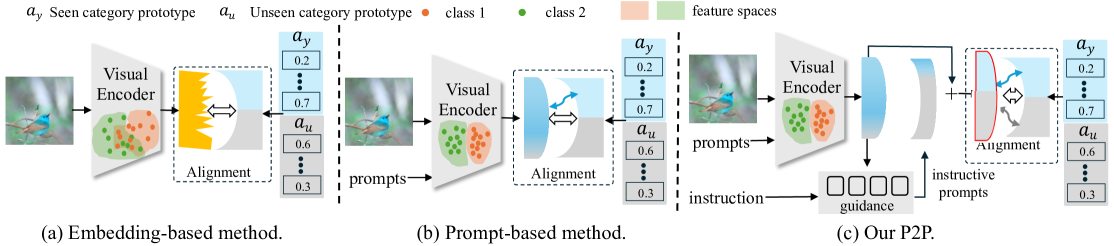
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
0
0
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
6/6/2024
🛸
Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting
Zijie Chen, Lichao Zhang, Fangsheng Weng, Lili Pan, Zhenzhong Lan
0
0
Despite significant progress in the field, it is still challenging to create personalized visual representations that align closely with the desires and preferences of individual users. This process requires users to articulate their ideas in words that are both comprehensible to the models and accurately capture their vision, posing difficulties for many users. In this paper, we tackle this challenge by leveraging historical user interactions with the system to enhance user prompts. We propose a novel approach that involves rewriting user prompts based on a newly collected large-scale text-to-image dataset with over 300k prompts from 3115 users. Our rewriting model enhances the expressiveness and alignment of user prompts with their intended visual outputs. Experimental results demonstrate the superiority of our methods over baseline approaches, as evidenced in our new offline evaluation method and online tests. Our code and dataset are available at https://github.com/zzjchen/Tailored-Visions.
4/9/2024