Temporally Consistent Unbalanced Optimal Transport for Unsupervised Action Segmentation
2404.01518
0
0
🤷
Abstract
We propose a novel approach to the action segmentation task for long, untrimmed videos, based on solving an optimal transport problem. By encoding a temporal consistency prior into a Gromov-Wasserstein problem, we are able to decode a temporally consistent segmentation from a noisy affinity/matching cost matrix between video frames and action classes. Unlike previous approaches, our method does not require knowing the action order for a video to attain temporal consistency. Furthermore, our resulting (fused) Gromov-Wasserstein problem can be efficiently solved on GPUs using a few iterations of projected mirror descent. We demonstrate the effectiveness of our method in an unsupervised learning setting, where our method is used to generate pseudo-labels for self-training. We evaluate our segmentation approach and unsupervised learning pipeline on the Breakfast, 50-Salads, YouTube Instructions and Desktop Assembly datasets, yielding state-of-the-art results for the unsupervised video action segmentation task.
Create account to get full access
Overview
- The paper describes a new deep learning model for generating high-quality images from textual descriptions.
- The model, called Epic, uses a novel architecture that combines language understanding with image generation capabilities.
- The authors conduct extensive experiments to demonstrate Epic's superior performance compared to existing text-to-image generation approaches.
- The research has the potential to enable a wide range of applications, from creative content generation to visual communication and education.
Plain English Explanation
Imagine you have an idea for a new image, but you don't have the artistic skills to draw it yourself. That's where this new deep learning model comes in. It can take a simple description of what you want to see, like "a colorful cartoon dog playing fetch in a sunny park," and turn that into a realistic-looking image.
The key innovation is the model's ability to deeply understand the language used in the description and then translate that understanding into a corresponding visual representation. It's almost like the model can visualize the scene in its "mind" and then bring that vision to life on the screen.
This could be really useful for all sorts of applications. For example, a company might use it to generate product images or illustrations for their website without needing a team of graphic designers. Or an educator could use it to create custom visuals to support their lesson plans. The possibilities are quite exciting.
Technical Explanation
The Epic model is built on a transformer-based architecture that includes both language understanding and image generation capabilities. The language understanding component takes the textual description as input and produces a rich, contextual representation of the semantic content. This is then fed into the image generation component, which uses a series of convolutional and deconvolutional layers to synthesize the corresponding visual output.
The authors train and evaluate Epic on several benchmark datasets for text-to-image generation, including COCO and MS-COCO. Their experiments demonstrate that Epic outperforms existing state-of-the-art models in terms of both image quality (as measured by perceptual similarity metrics) and semantic alignment between the generated images and the input text.
The model's strong performance is attributed to its ability to learn effective cross-modal representations that capture the intricate relationships between language and visual concepts. The authors also introduce several architectural innovations, such as adaptive instance normalization and cross-attention mechanisms, that contribute to Epic's impressive capabilities.
Critical Analysis
The paper provides a thorough and well-designed set of experiments to evaluate Epic's performance. The authors acknowledge several limitations of the current work, such as the model's sensitivity to the quality and diversity of the training data, as well as the computational complexity involved in generating high-resolution images.
One potential concern is the ethical implications of such powerful text-to-image generation technology. While the authors do not address this in depth, there are valid concerns about the potential for misuse, such as the creation of fake or misleading visual content. Careful consideration of these issues will be important as the technology continues to develop.
Additionally, the paper does not provide an in-depth analysis of the model's internal representations and decision-making processes. A better understanding of how the language and visual components interact and the specific mechanisms that enable the model's strong performance could lead to further insights and improvements.
Conclusion
The Epic model represents a significant advance in the field of text-to-image generation, demonstrating the potential for deep learning to bridge the gap between language and visual representation. The authors' rigorous experimental evaluation and technical contributions make a valuable addition to the ongoing research in this area.
As the model and similar technologies continue to evolve, it will be important to carefully consider the ethical and societal implications, while also exploring ways to further enhance the model's capabilities and robustness. Overall, this research opens up exciting new possibilities for creative and educational applications that leverage the power of language-driven image generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
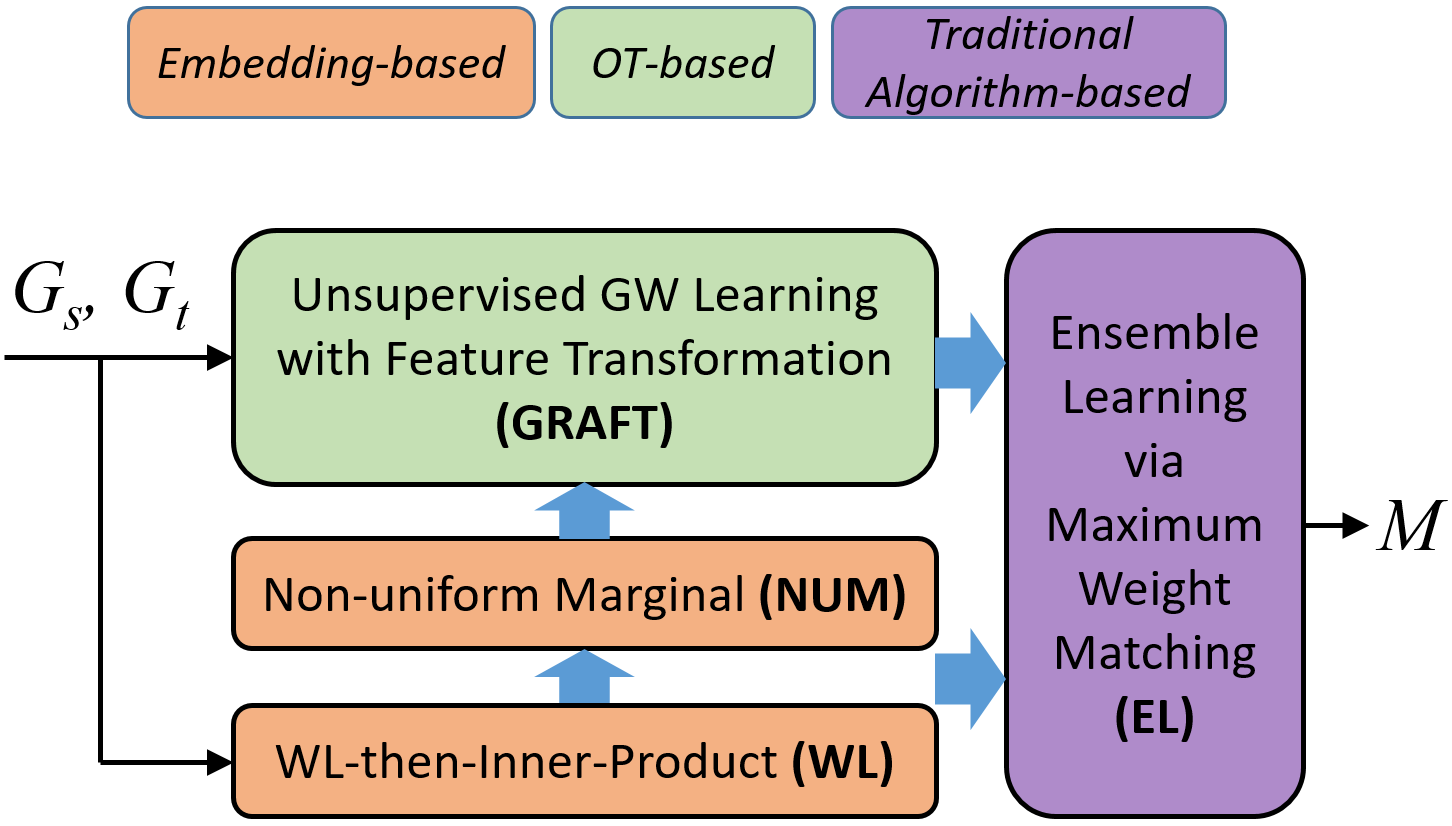
Combining Optimal Transport and Embedding-Based Approaches for More Expressiveness in Unsupervised Graph Alignment
Songyang Chen, Yu Liu, Lei Zou, Zexuan Wang, Youfang Lin, Yuxing Chen, Anqun Pan
0
0
Unsupervised graph alignment finds the one-to-one node correspondence between a pair of attributed graphs by only exploiting graph structure and node features. One category of existing works first computes the node representation and then matches nodes with close embeddings, which is intuitive but lacks a clear objective tailored for graph alignment in the unsupervised setting. The other category reduces the problem to optimal transport (OT) via Gromov-Wasserstein (GW) learning with a well-defined objective but leaves a large room for exploring the design of transport cost. We propose a principled approach to combine their advantages motivated by theoretical analysis of model expressiveness. By noticing the limitation of discriminative power in separating matched and unmatched node pairs, we improve the cost design of GW learning with feature transformation, which enables feature interaction across dimensions. Besides, we propose a simple yet effective embedding-based heuristic inspired by the Weisfeiler-Lehman test and add its prior knowledge to OT for more expressiveness when handling non-Euclidean data. Moreover, we are the first to guarantee the one-to-one matching constraint by reducing the problem to maximum weight matching. The algorithm design effectively combines our OT and embedding-based predictions via stacking, an ensemble learning strategy. We propose a model framework named texttt{CombAlign} integrating all the above modules to refine node alignment progressively. Through extensive experiments, we demonstrate significant improvements in alignment accuracy compared to state-of-the-art approaches and validate the effectiveness of the proposed modules.
6/21/2024

Multi-view Action Recognition via Directed Gromov-Wasserstein Discrepancy
Hoang-Quan Nguyen, Thanh-Dat Truong, Khoa Luu
0
0
Action recognition has become one of the popular research topics in computer vision. There are various methods based on Convolutional Networks and self-attention mechanisms as Transformers to solve both spatial and temporal dimensions problems of action recognition tasks that achieve competitive performances. However, these methods lack a guarantee of the correctness of the action subject that the models give attention to, i.e., how to ensure an action recognition model focuses on the proper action subject to make a reasonable action prediction. In this paper, we propose a multi-view attention consistency method that computes the similarity between two attentions from two different views of the action videos using Directed Gromov-Wasserstein Discrepancy. Furthermore, our approach applies the idea of Neural Radiance Field to implicitly render the features from novel views when training on single-view datasets. Therefore, the contributions in this work are three-fold. Firstly, we introduce the multi-view attention consistency to solve the problem of reasonable prediction in action recognition. Secondly, we define a new metric for multi-view consistent attention using Directed Gromov-Wasserstein Discrepancy. Thirdly, we built an action recognition model based on Video Transformers and Neural Radiance Fields. Compared to the recent action recognition methods, the proposed approach achieves state-of-the-art results on three large-scale datasets, i.e., Jester, Something-Something V2, and Kinetics-400.
5/3/2024

O-TALC: Steps Towards Combating Oversegmentation within Online Action Segmentation
Matthew Kent Myers, Nick Wright, A. Stephen McGough, Nicholas Martin
0
0
Online temporal action segmentation shows a strong potential to facilitate many HRI tasks where extended human action sequences must be tracked and understood in real time. Traditional action segmentation approaches, however, operate in an offline two stage approach, relying on computationally expensive video wide features for segmentation, rendering them unsuitable for online HRI applications. In order to facilitate online action segmentation on a stream of incoming video data, we introduce two methods for improved training and inference of backbone action recognition models, allowing them to be deployed directly for online frame level classification. Firstly, we introduce surround dense sampling whilst training to facilitate training vs. inference clip matching and improve segment boundary predictions. Secondly, we introduce an Online Temporally Aware Label Cleaning (O-TALC) strategy to explicitly reduce oversegmentation during online inference. As our methods are backbone invariant, they can be deployed with computationally efficient spatio-temporal action recognition models capable of operating in real time with a small segmentation latency. We show our method outperforms similar online action segmentation work as well as matches the performance of many offline models with access to full temporal resolution when operating on challenging fine-grained datasets.
4/11/2024

SP$^2$OT: Semantic-Regularized Progressive Partial Optimal Transport for Imbalanced Clustering
Chuyu Zhang, Hui Ren, Xuming He
0
0
Deep clustering, which learns representation and semantic clustering without labels information, poses a great challenge for deep learning-based approaches. Despite significant progress in recent years, most existing methods focus on uniformly distributed datasets, significantly limiting the practical applicability of their methods. In this paper, we propose a more practical problem setting named deep imbalanced clustering, where the underlying classes exhibit an imbalance distribution. To address this challenge, we introduce a novel optimal transport-based pseudo-label learning framework. Our framework formulates pseudo-label generation as a Semantic-regularized Progressive Partial Optimal Transport (SP$^2$OT) problem, which progressively transports each sample to imbalanced clusters under several prior distribution and semantic relation constraints, thus generating high-quality and imbalance-aware pseudo-labels. To solve SP$^2$OT, we develop a Majorization-Minimization-based optimization algorithm. To be more precise, we employ the strategy of majorization to reformulate the SP$^2$OT problem into a Progressive Partial Optimal Transport problem, which can be transformed into an unbalanced optimal transport problem with augmented constraints and can be solved efficiently by a fast matrix scaling algorithm. Experiments on various datasets, including a human-curated long-tailed CIFAR100, challenging ImageNet-R, and large-scale subsets of fine-grained iNaturalist2018 datasets, demonstrate the superiority of our method.
4/5/2024