Text-to-Vector Generation with Neural Path Representation
2405.10317
0
0
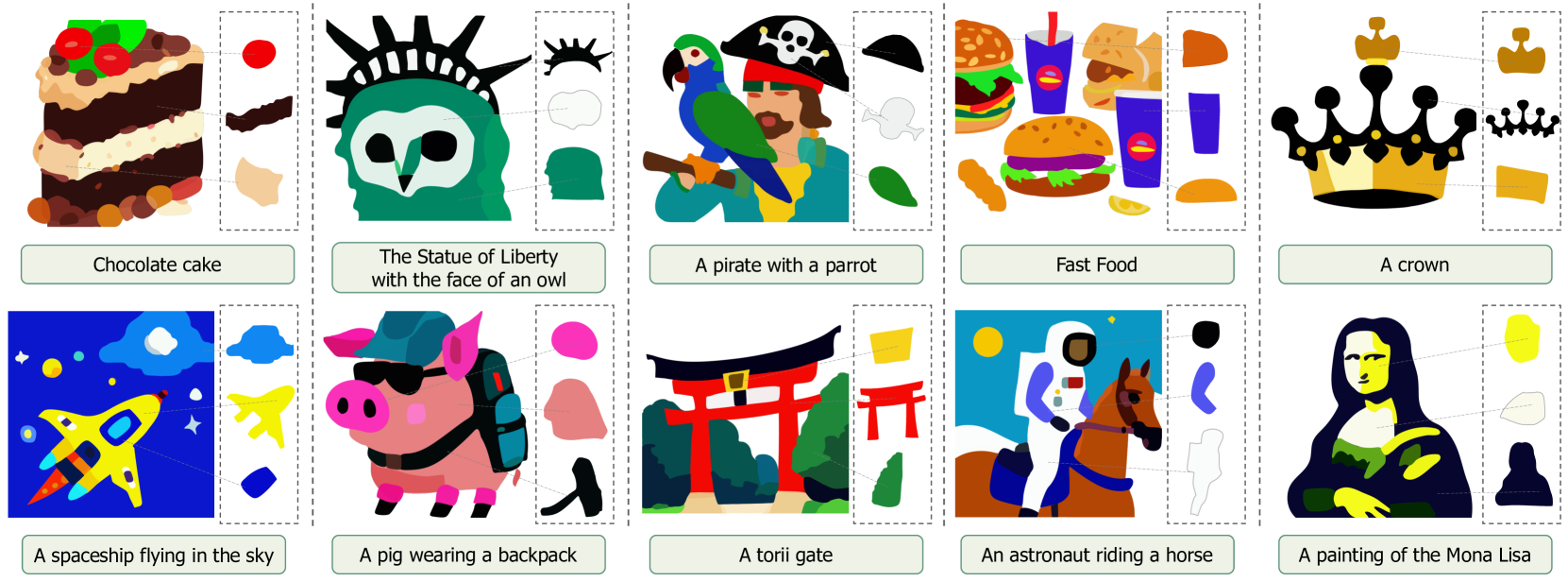
Abstract
Vector graphics are widely used in digital art and highly favored by designers due to their scalability and layer-wise properties. However, the process of creating and editing vector graphics requires creativity and design expertise, making it a time-consuming task. Recent advancements in text-to-vector (T2V) generation have aimed to make this process more accessible. However, existing T2V methods directly optimize control points of vector graphics paths, often resulting in intersecting or jagged paths due to the lack of geometry constraints. To overcome these limitations, we propose a novel neural path representation by designing a dual-branch Variational Autoencoder (VAE) that learns the path latent space from both sequence and image modalities. By optimizing the combination of neural paths, we can incorporate geometric constraints while preserving expressivity in generated SVGs. Furthermore, we introduce a two-stage path optimization method to improve the visual and topological quality of generated SVGs. In the first stage, a pre-trained text-to-image diffusion model guides the initial generation of complex vector graphics through the Variational Score Distillation (VSD) process. In the second stage, we refine the graphics using a layer-wise image vectorization strategy to achieve clearer elements and structure. We demonstrate the effectiveness of our method through extensive experiments and showcase various applications. The project page is https://intchous.github.io/T2V-NPR.
Create account to get full access
Introduction
In this paper, the authors present a novel approach to text-to-vector generation, where they use a neural network to translate text descriptions into vector graphics. This is an important problem in the field of computer graphics, as it can enable more intuitive and accessible creation of visual content.
Related Work
Prior Approaches to Text-Based Vector Graphics Generation
The authors discuss prior work in the area of text-based vector graphics generation, including SVGDreamer, which uses a diffusion model to generate SVG images from text, and VectorPainter, which takes a more traditional approach to vector graphics generation.
Limitations of Existing Approaches
The authors note that while these prior approaches have made progress, they often struggle to capture the nuanced relationships between text and vector graphics, or may produce results that lack coherence or fidelity to the input text.
Plain English Explanation
The key idea behind this paper is to use a neural network to learn the complex mapping between text descriptions and the corresponding vector graphics. Instead of relying on rule-based or template-based approaches, the authors train a model that can directly translate text into vector graphics in a more flexible and expressive way.
The model works by first encoding the input text into a high-dimensional vector representation, and then using that representation to generate a sequence of vector graphics "commands" that describe the visual content. This allows the model to capture the nuanced relationships between the text and the visual elements, and to produce more coherent and faithful vector graphics outputs.
One of the novel aspects of this approach is the use of a "neural path representation" - a way of encoding the vector graphics as a sequence of steps or "paths" that the model can learn to generate. This helps the model to better understand the structure and composition of the vector graphics, and to produce more realistic and natural-looking results.
Technical Explanation
The authors' approach consists of several key components:
- Text Encoder: A transformer-based encoder that takes the input text description and encodes it into a high-dimensional vector representation.
- Path Decoder: A recurrent neural network that takes the text encoding and generates a sequence of vector graphics "commands" that describe the visual content.
- Neural Path Representation: A novel way of representing the vector graphics as a sequence of steps or "paths", which the model can learn to generate more effectively.
The authors train and evaluate their model on a dataset of text-vector pairs, and demonstrate that it outperforms prior approaches in terms of both quantitative metrics and human evaluation of the generated outputs.
Critical Analysis
One potential limitation of the authors' approach is that it may struggle to capture the full range of visual complexity that can be expressed in vector graphics. While the neural path representation helps to address this to some degree, there may be certain types of vector graphics that are difficult for the model to generate accurately.
Additionally, the authors do not explore the potential biases or limitations of the training data, which could affect the model's performance on certain types of text descriptions or visual content.
Conclusion
Overall, this paper presents a promising new approach to text-to-vector generation that leverages the power of neural networks to learn the complex mapping between text and vector graphics. The authors' use of a neural path representation is a particularly interesting and novel aspect of their work, and their results suggest that this approach has the potential to enable more intuitive and expressive vector graphics creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
NIVeL: Neural Implicit Vector Layers for Text-to-Vector Generation
Vikas Thamizharasan, Difan Liu, Matthew Fisher, Nanxuan Zhao, Evangelos Kalogerakis, Michal Lukac
0
0
The success of denoising diffusion models in representing rich data distributions over 2D raster images has prompted research on extending them to other data representations, such as vector graphics. Unfortunately due to their variable structure and scarcity of vector training data, directly applying diffusion models on this domain remains a challenging problem. Using workarounds like optimization via Score Distillation Sampling (SDS) is also fraught with difficulty, as vector representations are non trivial to directly optimize and tend to result in implausible geometries such as redundant or self-intersecting shapes. NIVeL addresses these challenges by reinterpreting the problem on an alternative, intermediate domain which preserves the desirable properties of vector graphics -- mainly sparsity of representation and resolution-independence. This alternative domain is based on neural implicit fields expressed in a set of decomposable, editable layers. Based on our experiments, NIVeL produces text-to-vector graphics results of significantly better quality than the state-of-the-art.
5/27/2024

SuperSVG: Superpixel-based Scalable Vector Graphics Synthesis
Teng Hu, Ran Yi, Baihong Qian, Jiangning Zhang, Paul L. Rosin, Yu-Kun Lai
0
0
SVG (Scalable Vector Graphics) is a widely used graphics format that possesses excellent scalability and editability. Image vectorization, which aims to convert raster images to SVGs, is an important yet challenging problem in computer vision and graphics. Existing image vectorization methods either suffer from low reconstruction accuracy for complex images or require long computation time. To address this issue, we propose SuperSVG, a superpixel-based vectorization model that achieves fast and high-precision image vectorization. Specifically, we decompose the input image into superpixels to help the model focus on areas with similar colors and textures. Then, we propose a two-stage self-training framework, where a coarse-stage model is employed to reconstruct the main structure and a refinement-stage model is used for enriching the details. Moreover, we propose a novel dynamic path warping loss to help the refinement-stage model to inherit knowledge from the coarse-stage model. Extensive qualitative and quantitative experiments demonstrate the superior performance of our method in terms of reconstruction accuracy and inference time compared to state-of-the-art approaches. The code is available in url{https://github.com/sjtuplayer/SuperSVG}.
6/17/2024

Text-Based Reasoning About Vector Graphics
Zhenhailong Wang, Joy Hsu, Xingyao Wang, Kuan-Hao Huang, Manling Li, Jiajun Wu, Heng Ji
0
0
While large multimodal models excel in broad vision-language benchmarks, they often struggle with tasks requiring precise perception of low-level visual details, such as comparing line lengths or solving simple mazes. In particular, this failure mode persists in question-answering tasks about vector graphics -- images composed purely of 2D objects and shapes. To address this challenge, we propose the Visually Descriptive Language Model (VDLM), which performs text-based reasoning about vector graphics. VDLM leverages Scalable Vector Graphics (SVG) for a more precise visual description and first uses an off-the-shelf raster-to-SVG algorithm for encoding. Since existing language models cannot understand raw SVGs in a zero-shot setting, VDLM then bridges SVG with pretrained language models through a newly introduced intermediate symbolic representation, Primal Visual Description (PVD), comprising primitive attributes (e.g., shape, position, measurement) with their corresponding predicted values. PVD is task-agnostic and represents visual primitives that are universal across all vector graphics. It can be learned with procedurally generated (SVG, PVD) pairs and also enables the direct use of LLMs for generalization to complex reasoning tasks. By casting an image to a text-based representation, we can leverage the power of language models to learn alignment from SVG to visual primitives and generalize to unseen question-answering tasks. Empirical results show that VDLM achieves stronger zero-shot performance compared to state-of-the-art LMMs, such as GPT-4V, in various low-level multimodal perception and reasoning tasks on vector graphics. We additionally present extensive analyses on VDLM's performance, demonstrating that our framework offers better interpretability due to its disentangled perception and reasoning processes. Project page: https://mikewangwzhl.github.io/VDLM/
5/28/2024

T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text
Aoxiong Yin, Haoyuan Li, Kai Shen, Siliang Tang, Yueting Zhuang
0
0
In this work, we propose a two-stage sign language production (SLP) paradigm that first encodes sign language sequences into discrete codes and then autoregressively generates sign language from text based on the learned codebook. However, existing vector quantization (VQ) methods are fixed-length encodings, overlooking the uneven information density in sign language, which leads to under-encoding of important regions and over-encoding of unimportant regions. To address this issue, we propose a novel dynamic vector quantization (DVA-VAE) model that can dynamically adjust the encoding length based on the information density in sign language to achieve accurate and compact encoding. Then, a GPT-like model learns to generate code sequences and their corresponding durations from spoken language text. Extensive experiments conducted on the PHOENIX14T dataset demonstrate the effectiveness of our proposed method. To promote sign language research, we propose a new large German sign language dataset, PHOENIX-News, which contains 486 hours of sign language videos, audio, and transcription texts.Experimental analysis on PHOENIX-News shows that the performance of our model can be further improved by increasing the size of the training data. Our project homepage is https://t2sgpt-demo.yinaoxiong.cn.
6/12/2024