Time-Equivariant Contrastive Learning for Degenerative Disease Progression in Retinal OCT
2405.09404
0
0

Abstract
Contrastive pretraining provides robust representations by ensuring their invariance to different image transformations while simultaneously preventing representational collapse. Equivariant contrastive learning, on the other hand, provides representations sensitive to specific image transformations while remaining invariant to others. By introducing equivariance to time-induced transformations, such as disease-related anatomical changes in longitudinal imaging, the model can effectively capture such changes in the representation space. In this work, we pro-pose a Time-equivariant Contrastive Learning (TC) method. First, an encoder embeds two unlabeled scans from different time points of the same patient into the representation space. Next, a temporal equivariance module is trained to predict the representation of a later visit based on the representation from one of the previous visits and the corresponding time interval with a novel regularization loss term while preserving the invariance property to irrelevant image transformations. On a large longitudinal dataset, our model clearly outperforms existing equivariant contrastive methods in predicting progression from intermediate age-related macular degeneration (AMD) to advanced wet-AMD within a specified time-window.
Create account to get full access
Overview
- This paper proposes a novel approach called Time-Equivariant Contrastive Learning (TECL) for predicting the progression of degenerative eye diseases, such as Age-Related Macular Degeneration (AMD), using retinal optical coherence tomography (OCT) scans.
- The key idea is to leverage the inherent time-equivariance in longitudinal medical imaging data to learn more robust and accurate predictive models for disease progression.
- The proposed TECL framework outperforms state-of-the-art methods in predicting future disease stages, which could aid early diagnosis and personalized treatment planning for patients with degenerative eye conditions.
Plain English Explanation
The paper focuses on developing a machine learning model to predict how eye diseases like AMD progress over time. The researchers used a type of medical imaging called optical coherence tomography (OCT) to capture images of the back of the eye.
The key insight is that eye disease progression follows a consistent pattern over time. By leveraging this "time-equivariance" - the idea that the disease progression looks similar at different time points - the model can learn more robust and accurate predictions of how the disease will advance in the future. This is in contrast to previous approaches that may have treated each time point independently.
The proposed Time-Equivariant Contrastive Learning (TECL) framework outperformed other state-of-the-art methods at predicting future disease stages. This could help doctors diagnose eye diseases earlier and develop personalized treatment plans for patients.
Technical Explanation
The paper introduces a novel Time-Equivariant Contrastive Learning (TECL) framework for predicting the progression of degenerative eye diseases, such as Age-Related Macular Degeneration (AMD), using longitudinal retinal optical coherence tomography (OCT) scans.
The key idea is to leverage the inherent time-equivariance present in the longitudinal medical imaging data. Time-equivariance refers to the property that the disease progression looks similar at different time points, and TECL aims to capture this by learning representations that are invariant to temporal shifts.
The TECL framework consists of two main components:
- Time-Equivariant Encoder: This module learns a time-equivariant representation of the input OCT scans by enforcing the learned features to be invariant to temporal shifts.
- Contrastive Prediction Head: This component predicts the future disease stage by training a contrastive head to discriminate between positive (temporally consistent) and negative (temporally inconsistent) pairs of representations.
The researchers demonstrate that TECL outperforms state-of-the-art methods, such as LATIM and 3D-TINC, on the task of predicting future disease stages in longitudinal OCT datasets. This improvement is attributed to the model's ability to better capture the inherent time-equivariance in the data, leading to more robust and accurate predictions of disease progression.
Critical Analysis
The paper presents a compelling approach to leveraging the temporal structure of longitudinal medical imaging data for predicting the progression of degenerative eye diseases. The authors' focus on time-equivariance is novel and aligns well with the underlying properties of disease progression observed in the data.
However, one potential limitation of the study is the reliance on a relatively small dataset of retinal OCT scans. While the authors demonstrate the effectiveness of TECL on this dataset, it would be valuable to evaluate the model's performance on larger, more diverse datasets to assess its generalizability.
Additionally, the paper does not provide a detailed analysis of the model's interpretability or the specific features it learns to predict disease progression. Incorporating explanatory or anatomically-conditioned approaches could further enhance the model's transparency and provide valuable insights for clinicians.
Overall, the TECL framework represents an important step forward in developing more accurate and robust predictive models for degenerative eye diseases. Further research to address the limitations and explore the model's broader applicability would be valuable contributions to the field.
Conclusion
This paper introduces a novel Time-Equivariant Contrastive Learning (TECL) framework for predicting the progression of degenerative eye diseases, such as Age-Related Macular Degeneration (AMD), using longitudinal retinal optical coherence tomography (OCT) scans.
The key innovation is the leveraging of the inherent time-equivariance present in the longitudinal medical imaging data, allowing the model to learn more robust and accurate representations of disease progression. The proposed TECL framework outperforms state-of-the-art methods, demonstrating its potential to aid in early diagnosis and personalized treatment planning for patients with degenerative eye conditions.
While further research is needed to address the limitations and explore the broader applicability of the TECL approach, this work represents an important step forward in the field of predictive modeling for degenerative diseases using longitudinal medical imaging data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
3DTINC: Time-Equivariant Non-Contrastive Learning for Predicting Disease Progression from Longitudinal OCTs
Taha Emre, Arunava Chakravarty, Antoine Rivail, Dmitrii Lachinov, Oliver Leingang, Sophie Riedl, Julia Mai, Hendrik P. N. Scholl, Sobha Sivaprasad, Daniel Rueckert, Andrew Lotery, Ursula Schmidt-Erfurth, Hrvoje Bogunovi'c
0
0
Self-supervised learning (SSL) has emerged as a powerful technique for improving the efficiency and effectiveness of deep learning models. Contrastive methods are a prominent family of SSL that extract similar representations of two augmented views of an image while pushing away others in the representation space as negatives. However, the state-of-the-art contrastive methods require large batch sizes and augmentations designed for natural images that are impractical for 3D medical images. To address these limitations, we propose a new longitudinal SSL method, 3DTINC, based on non-contrastive learning. It is designed to learn perturbation-invariant features for 3D optical coherence tomography (OCT) volumes, using augmentations specifically designed for OCT. We introduce a new non-contrastive similarity loss term that learns temporal information implicitly from intra-patient scans acquired at different times. Our experiments show that this temporal information is crucial for predicting progression of retinal diseases, such as age-related macular degeneration (AMD). After pretraining with 3DTINC, we evaluated the learned representations and the prognostic models on two large-scale longitudinal datasets of retinal OCTs where we predict the conversion to wet-AMD within a six months interval. Our results demonstrate that each component of our contributions is crucial for learning meaningful representations useful in predicting disease progression from longitudinal volumetric scans.
5/14/2024

Equivariant Spatio-Temporal Self-Supervision for LiDAR Object Detection
Deepti Hegde, Suhas Lohit, Kuan-Chuan Peng, Michael J. Jones, Vishal M. Patel
0
0
Popular representation learning methods encourage feature invariance under transformations applied at the input. However, in 3D perception tasks like object localization and segmentation, outputs are naturally equivariant to some transformations, such as rotation. Using pre-training loss functions that encourage equivariance of features under certain transformations provides a strong self-supervision signal while also retaining information of geometric relationships between transformed feature representations. This can enable improved performance in downstream tasks that are equivariant to such transformations. In this paper, we propose a spatio-temporal equivariant learning framework by considering both spatial and temporal augmentations jointly. Our experiments show that the best performance arises with a pre-training approach that encourages equivariance to translation, scaling, and flip, rotation and scene flow. For spatial augmentations, we find that depending on the transformation, either a contrastive objective or an equivariance-by-classification objective yields best results. To leverage real-world object deformations and motion, we consider sequential LiDAR scene pairs and develop a novel 3D scene flow-based equivariance objective that leads to improved performance overall. We show our pre-training method for 3D object detection which outperforms existing equivariant and invariant approaches in many settings.
4/19/2024

Contrastive Learning Via Equivariant Representation
Sifan Song, Jinfeng Wang, Qiaochu Zhao, Xiang Li, Dufan Wu, Angelos Stefanidis, Jionglong Su, S. Kevin Zhou, Quanzheng Li
0
0
Invariant-based Contrastive Learning (ICL) methods have achieved impressive performance across various domains. However, the absence of latent space representation for distortion (augmentation)-related information in the latent space makes ICL sub-optimal regarding training efficiency and robustness in downstream tasks. Recent studies suggest that introducing equivariance into Contrastive Learning (CL) can improve overall performance. In this paper, we rethink the roles of augmentation strategies and equivariance in improving CL efficacy. We propose a novel Equivariant-based Contrastive Learning (ECL) framework, CLeVER (Contrastive Learning Via Equivariant Representation), compatible with augmentation strategies of arbitrary complexity for various mainstream CL methods and model frameworks. Experimental results demonstrate that CLeVER effectively extracts and incorporates equivariant information from data, thereby improving the training efficiency and robustness of baseline models in downstream tasks.
6/4/2024
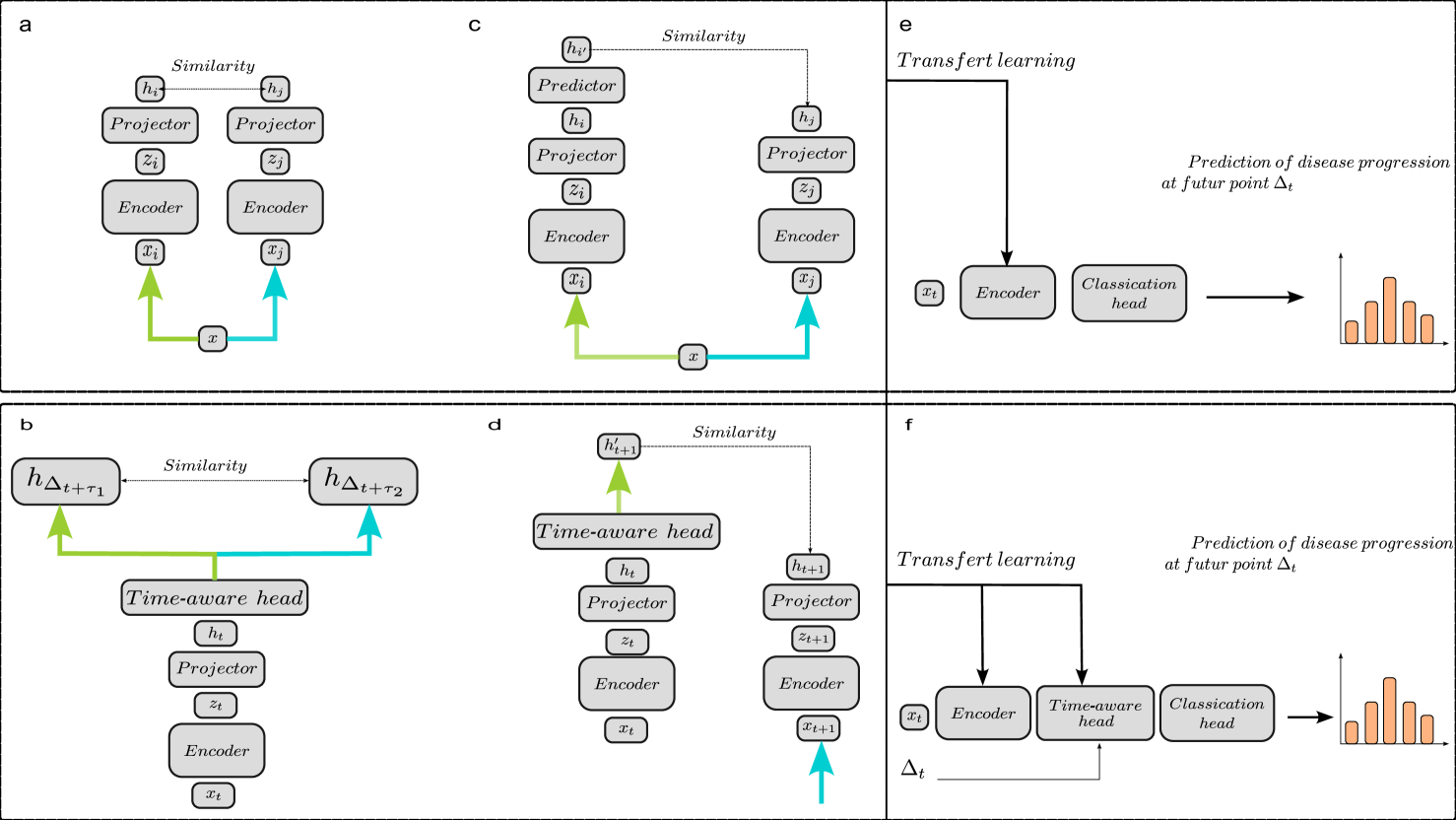
LaTiM: Longitudinal representation learning in continuous-time models to predict disease progression
Rachid Zeghlache, Pierre-Henri Conze, Mostafa El Habib Daho, Yihao Li, Hugo Le Boit'e, Ramin Tadayoni, Pascal Massin, B'eatrice Cochener, Alireza Rezaei, Ikram Brahim, Gwenol'e Quellec, Mathieu Lamard
0
0
This work proposes a novel framework for analyzing disease progression using time-aware neural ordinary differential equations (NODE). We introduce a time-aware head in a framework trained through self-supervised learning (SSL) to leverage temporal information in latent space for data augmentation. This approach effectively integrates NODEs with SSL, offering significant performance improvements compared to traditional methods that lack explicit temporal integration. We demonstrate the effectiveness of our strategy for diabetic retinopathy progression prediction using the OPHDIAT database. Compared to the baseline, all NODE architectures achieve statistically significant improvements in area under the ROC curve (AUC) and Kappa metrics, highlighting the efficacy of pre-training with SSL-inspired approaches. Additionally, our framework promotes stable training for NODEs, a commonly encountered challenge in time-aware modeling.
4/11/2024