Understanding the Dataset Practitioners Behind Large Language Model Development
2402.16611
0
0
Abstract
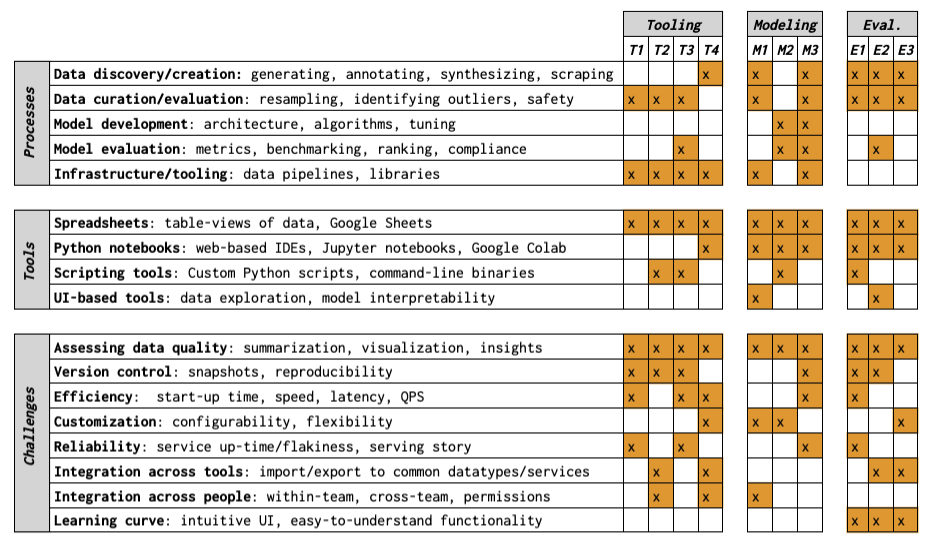
As large language models (LLMs) become more advanced and impactful, it is increasingly important to scrutinize the data that they rely upon and produce. What is it to be a dataset practitioner doing this work? We approach this in two parts: first, we define the role of dataset practitioners by performing a retrospective analysis on the responsibilities of teams contributing to LLM development at a technology company, Google. Then, we conduct semi-structured interviews with a cross-section of these practitioners (N=10). We find that although data quality is a top priority, there is little consensus around what data quality is and how to evaluate it. Consequently, practitioners either rely on their own intuition or write custom code to evaluate their data. We discuss potential reasons for this phenomenon and opportunities for alignment.
Create account to get full access
Overview
- This paper examines the dataset practitioners involved in the development of large language models (LLMs).
- It explores the diverse backgrounds, experiences, and perspectives of the individuals responsible for creating the datasets that power these advanced AI systems.
- The research aims to shed light on the often overlooked yet critical role of dataset practitioners in shaping the capabilities and potential impacts of LLMs.
Plain English Explanation
Large language models (LLMs) like ChatGPT have become incredibly powerful and influential, with the ability to engage in human-like conversations, answer questions, and complete a wide range of tasks. However, the development of these models relies heavily on the datasets used to train them.
The individuals responsible for curating, annotating, and preparing these datasets are known as "dataset practitioners." They come from a variety of backgrounds, including linguistics, data science, and user experience design. The researchers in this paper wanted to understand more about who these practitioners are, what their roles and experiences entail, and how their work influences the final LLM capabilities.
By interviewing dataset practitioners, the researchers uncovered insights into the complex and often overlooked contributions these individuals make. They found that dataset practitioners play a crucial role in shaping the knowledge, biases, and limitations of LLMs, with far-reaching implications for how these AI systems are deployed and used in the real world.
Technical Explanation
The researchers conducted in-depth interviews with 21 dataset practitioners involved in the development of large language models. The participants came from diverse backgrounds, with varied levels of experience and roles within the dataset creation process.
Through qualitative analysis of the interview transcripts, the researchers identified several key themes:
-
Diverse Backgrounds and Expertise: The dataset practitioners had a wide range of educational and professional backgrounds, including linguistics, computer science, user experience design, and more. This diversity of perspectives and skillsets influenced how they approached dataset curation and annotation.
-
Challenges and Considerations: The practitioners faced numerous challenges in their work, such as balancing data quality, scale, and representation; navigating ethical concerns; and dealing with ambiguous or subjective annotation tasks.
-
Evolving Roles and Responsibilities: The role of dataset practitioners has expanded over time, with increasing importance placed on tasks like data validation, model testing, and engaging with end-users and stakeholders.
-
Impact on Model Development: The dataset practitioners recognized their significant influence on the capabilities, biases, and limitations of the resulting language models. They expressed a sense of responsibility and a desire for more transparency and collaboration in the model development process.
The findings highlight the critical yet often overlooked contributions of dataset practitioners in shaping the AI systems that have become so pervasive in our daily lives.
Critical Analysis
The paper provides valuable insights into the often hidden world of dataset practitioners and their role in large language model development. By giving voice to these practitioners, the researchers shed light on the complexities and nuances involved in curating and annotating the data that powers these advanced AI systems.
One potential limitation of the study is the relatively small sample size of 21 participants. While the researchers aimed for diversity in the backgrounds and experiences of the interviewees, expanding the study to include a larger and more representative sample could provide an even richer understanding of the dataset practitioner landscape.
Additionally, the paper does not delve deeply into the specific ethical concerns and potential harms that dataset practitioners grapple with. As LLMs continue to be deployed in high-stakes domains, further research on the ethical implications of dataset curation and the mitigation of biases and other societal issues would be valuable.
Overall, this study represents an important step in recognizing the critical yet often overlooked contributions of dataset practitioners. By highlighting their pivotal role, the researchers encourage greater transparency, collaboration, and accountability in the development of large language models and other AI systems.
Conclusion
This research paper provides a compelling exploration of the dataset practitioners behind the development of large language models. By interviewing these often unsung contributors, the researchers shed light on the diverse backgrounds, challenges, and significant influence of these individuals.
The findings underscore the vital role that dataset practitioners play in shaping the capabilities, biases, and limitations of the AI systems that are increasingly shaping our world. As LLMs become more ubiquitous, it is crucial to recognize and empower these practitioners, fostering greater transparency, collaboration, and accountability in the model development process.
This study serves as a valuable resource for researchers, policymakers, and the broader AI community, highlighting the need to better understand and support the individuals whose work is foundational to the development of transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
0
0
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
4/16/2024

Global Data Constraints: Ethical and Effectiveness Challenges in Large Language Model
Jin Yang, Zhiqiang Wang, Yanbin Lin, Zunduo Zhao
0
0
The efficacy and ethical integrity of large language models (LLMs) are profoundly influenced by the diversity and quality of their training datasets. However, the global landscape of data accessibility presents significant challenges, particularly in regions with stringent data privacy laws or limited open-source information. This paper examines the multifaceted challenges associated with acquiring high-quality training data for LLMs, focusing on data scarcity, bias, and low-quality content across various linguistic contexts. We highlight the technical and ethical implications of relying on publicly available but potentially biased or irrelevant data sources, which can lead to the generation of biased or hallucinatory content by LLMs. Through a series of evaluations using GPT-4 and GPT-4o, we demonstrate how these data constraints adversely affect model performance and ethical alignment. We propose and validate several mitigation strategies designed to enhance data quality and model robustness, including advanced data filtering techniques and ethical data collection practices. Our findings underscore the need for a proactive approach in developing LLMs that considers both the effectiveness and ethical implications of data constraints, aiming to foster the creation of more reliable and universally applicable AI systems.
6/18/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
💬
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
0
0
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
4/10/2024