Unified Generation, Reconstruction, and Representation: Generalized Diffusion with Adaptive Latent Encoding-Decoding
2402.19009
0
0
Abstract
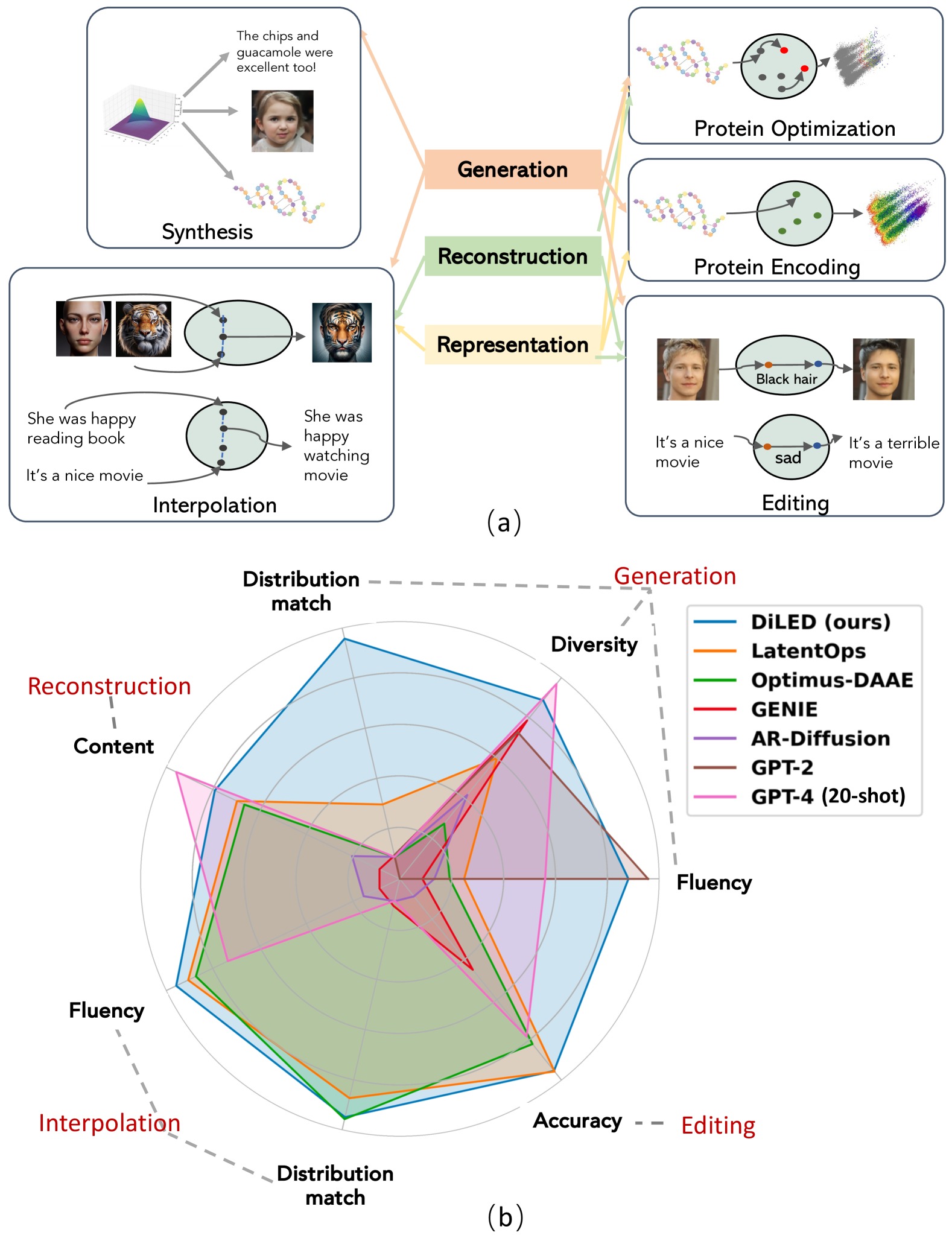
The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like variational autoencoders (VAEs), generative adversarial networks (GANs), autoregressive models, and (latent) diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce Generalized Encoding-Decoding Diffusion Probabilistic Models (EDDPMs) which integrate the core capabilities for broad applicability and enhanced performance. EDDPMs generalize the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, EDDPMs are compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), EDDPMs naturally apply to different data types. Extensive experiments on text, proteins, and images demonstrate the flexibility to handle diverse data and tasks and the strong improvement over various existing models.
Create account to get full access
Overview
- This paper introduces a novel approach for generating, reconstructing, and representing both discrete and continuous data using a generalized diffusion framework with learnable encoding-decoding.
- The authors propose a unified diffusion model that can handle a wide range of data types, from images to text, without requiring separate architectures or training procedures.
- The key innovation is the use of a learnable encoding-decoding mechanism that allows the diffusion process to adapt to the specific characteristics of the input data.
Plain English Explanation
The paper presents a new way to work with different types of data, such as images, text, and numbers, using a technique called "generalized diffusion." Typically, researchers need to develop separate models and training processes for each type of data. But this paper introduces a single, flexible model that can handle many kinds of data.
The key is that the model can "learn" how to best encode and decode the data, rather than relying on a fixed approach. This makes the model more adaptable and powerful. For example, when working with images, the model can learn the best way to represent the visual features. And when working with text, it can learn how to capture the structure and meaning of the language.
By having a single, flexible model that can handle diverse data, the researchers hope to make it easier and more efficient to work with a wide range of real-world information. This could have important applications in areas like [link to https://aimodels.fyi/papers/arxiv/udpm-upsampling-diffusion-probabilistic-models]image processing[/link], [link to https://aimodels.fyi/papers/arxiv/causal-diffusion-autoencoders-toward-counterfactual-generation-via]generating counterfactuals[/link], and [link to https://aimodels.fyi/papers/arxiv/missing-u-efficient-diffusion-models]handling missing data[/link].
Technical Explanation
The paper introduces a "generalized diffusion" framework that can model both discrete and continuous data using a unified approach. The key innovation is the use of a learnable encoding-decoding mechanism that allows the diffusion process to adapt to the specific characteristics of the input data.
Typically, diffusion models are designed for a specific data type, such as images or text. But the authors propose a more flexible model that can handle a wide range of data by learning how to best represent and transform the input. This is achieved through a learnable encoding-decoding module that is integrated into the diffusion process.
The encoding-decoding module learns to map the input data to a latent representation that can be effectively diffused and then reconstructed. This allows the model to capture the underlying structure and patterns in the data, whether it's the visual features of an image or the semantic relationships in text.
The authors evaluate their approach on a variety of datasets, including images, text, and tabular data. They demonstrate that the generalized diffusion model can outperform specialized models in terms of generation quality and reconstruction fidelity, while also being more efficient and flexible.
Critical Analysis
The paper presents a promising approach for handling diverse data types using a unified diffusion framework. The use of a learnable encoding-decoding mechanism is a key innovation that allows the model to adapt to the specific characteristics of the input data.
However, the paper does not address some potential limitations and areas for further research. For example, it's unclear how well the model would scale to very large or high-dimensional datasets, or how it would perform on more complex data structures like graphs or time series.
Additionally, the paper does not explore the interpretability or explainability of the learned encoding-decoding mechanism. Understanding how the model represents and transforms the input data could be important for certain applications, such as [link to https://aimodels.fyi/papers/arxiv/discovery-expansion-new-domains-within-diffusion-models]domain discovery and expansion[/link] or [link to https://aimodels.fyi/papers/arxiv/neural-network-parameter-diffusion]parameter diffusion[/link].
Overall, the research presents a valuable contribution to the field of diffusion models and highlights the potential benefits of a more flexible and adaptable approach to data representation and generation. Further exploration of the model's capabilities and limitations could lead to important insights and applications in various domains.
Conclusion
The paper introduces a novel approach for generating, reconstructing, and representing diverse data types using a generalized diffusion framework with a learnable encoding-decoding mechanism. This unified model can handle a wide range of data, from images to text, without requiring separate architectures or training procedures.
The key innovation is the use of a learnable encoding-decoding module that allows the diffusion process to adapt to the specific characteristics of the input data. This makes the model more flexible and powerful, with the potential to improve performance and efficiency in a variety of applications, such as image processing, counterfactual generation, and handling missing data.
While the paper presents promising results, it also highlights the need for further research to address potential limitations and explore the interpretability and scalability of the model. Nonetheless, the generalized diffusion approach represents an important step forward in developing more versatile and adaptable data modeling techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
UDPM: Upsampling Diffusion Probabilistic Models
Shady Abu-Hussein, Raja Giryes
0
0
Denoising Diffusion Probabilistic Models (DDPM) have recently gained significant attention. DDPMs compose a Markovian process that begins in the data domain and gradually adds noise until reaching pure white noise. DDPMs generate high-quality samples from complex data distributions by defining an inverse process and training a deep neural network to learn this mapping. However, these models are inefficient because they require many diffusion steps to produce aesthetically pleasing samples. Additionally, unlike generative adversarial networks (GANs), the latent space of diffusion models is less interpretable. In this work, we propose to generalize the denoising diffusion process into an Upsampling Diffusion Probabilistic Model (UDPM). In the forward process, we reduce the latent variable dimension through downsampling, followed by the traditional noise perturbation. As a result, the reverse process gradually denoises and upsamples the latent variable to produce a sample from the data distribution. We formalize the Markovian diffusion processes of UDPM and demonstrate its generation capabilities on the popular FFHQ, AFHQv2, and CIFAR10 datasets. UDPM generates images with as few as three network evaluations, whose overall computational cost is less than a single DDPM or EDM step, while achieving an FID score of 6.86. This surpasses current state-of-the-art efficient diffusion models that use a single denoising step for sampling. Additionally, UDPM offers an interpretable and interpolable latent space, which gives it an advantage over traditional DDPMs. Our code is available online: url{https://github.com/shadyabh/UDPM/}
5/29/2024
Diffusion Models for Accurate Channel Distribution Generation
Muah Kim, Rick Fritschek, Rafael F. Schaefer
0
0
Strong generative models can accurately learn channel distributions. This could save recurring costs for physical measurements of the channel. Moreover, the resulting differentiable channel model supports training neural encoders by enabling gradient-based optimization. The initial approach in the literature draws upon the modern advancements in image generation, utilizing generative adversarial networks (GANs) or their enhanced variants to generate channel distributions. In this paper, we address this channel approximation challenge with diffusion models (DMs), which have demonstrated high sample quality and mode coverage in image generation. In addition to testing the generative performance of the channel distributions, we use an end-to-end (E2E) coded-modulation framework underpinned by DMs and propose an efficient training algorithm. Our simulations with various channel models show that a DM can accurately learn channel distributions, enabling an E2E framework to achieve near-optimal symbol error rates (SERs). Furthermore, we examine the trade-off between mode coverage and sampling speed through skipped sampling using sliced Wasserstein distance (SWD) and the E2E SER. We investigate the effect of noise scheduling on this trade-off, demonstrating that with an appropriate choice of parameters and techniques, sampling time can be significantly reduced with a minor increase in SWD and SER. Finally, we show that the DM can generate a correlated fading channel, whereas a strong GAN variant fails to learn the covariance. This paper highlights the potential benefits of using DMs for learning channel distributions, which could be further investigated for various channels and advanced techniques of DMs.
6/12/2024
New!DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents
Yilun Xu, Gabriele Corso, Tommi Jaakkola, Arash Vahdat, Karsten Kreis
0
0
Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem. We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end. DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable. The discrete latents significantly simplify learning the DM's complex noise-to-data mapping by reducing the curvature of the DM's generative ODE. An additional autoregressive transformer models the distribution of the discrete latents, a simple step because DisCo-Diff requires only few discrete variables with small codebooks. We validate DisCo-Diff on toy data, several image synthesis tasks as well as molecular docking, and find that introducing discrete latents consistently improves model performance. For example, DisCo-Diff achieves state-of-the-art FID scores on class-conditioned ImageNet-64/128 datasets with ODE sampler.
7/4/2024

Causal Diffusion Autoencoders: Toward Counterfactual Generation via Diffusion Probabilistic Models
Aneesh Komanduri, Chen Zhao, Feng Chen, Xintao Wu
0
0
Diffusion probabilistic models (DPMs) have become the state-of-the-art in high-quality image generation. However, DPMs have an arbitrary noisy latent space with no interpretable or controllable semantics. Although there has been significant research effort to improve image sample quality, there is little work on representation-controlled generation using diffusion models. Specifically, causal modeling and controllable counterfactual generation using DPMs is an underexplored area. In this work, we propose CausalDiffAE, a diffusion-based causal representation learning framework to enable counterfactual generation according to a specified causal model. Our key idea is to use an encoder to extract high-level semantically meaningful causal variables from high-dimensional data and model stochastic variation using reverse diffusion. We propose a causal encoding mechanism that maps high-dimensional data to causally related latent factors and parameterize the causal mechanisms among latent factors using neural networks. To enforce the disentanglement of causal variables, we formulate a variational objective and leverage auxiliary label information in a prior to regularize the latent space. We propose a DDIM-based counterfactual generation procedure subject to do-interventions. Finally, to address the limited label supervision scenario, we also study the application of CausalDiffAE when a part of the training data is unlabeled, which also enables granular control over the strength of interventions in generating counterfactuals during inference. We empirically show that CausalDiffAE learns a disentangled latent space and is capable of generating high-quality counterfactual images.
5/10/2024