Utilizing Grounded SAM for self-supervised frugal camouflaged human detection
2406.05776
0
0

Abstract
Visually detecting camouflaged objects is a hard problem for both humans and computer vision algorithms. Strong similarities between object and background appearance make the task significantly more challenging than traditional object detection or segmentation tasks. Current state-of-the-art models use either convolutional neural networks or vision transformers as feature extractors. They are trained in a fully supervised manner and thus need a large amount of labeled training data. In this paper, both self-supervised and frugal learning methods are introduced to the task of Camouflaged Object Detection (COD). The overall goal is to fine-tune two COD reference methods, namely SINet-V2 and HitNet, pre-trained for camouflaged animal detection to the task of camouflaged human detection. Therefore, we use the public dataset CPD1K that contains camouflaged humans in a forest environment. We create a strong baseline using supervised frugal transfer learning for the fine-tuning task. Then, we analyze three pseudo-labeling approaches to perform the fine-tuning task in a self-supervised manner. Our experiments show that we achieve similar performance by pure self-supervision compared to fully supervised frugal learning.
Create account to get full access
Overview
- This research paper presents a novel approach for self-supervised frugal camouflaged human detection using a Grounded Semantic Alignment Model (Grounded SAM).
- The authors demonstrate how Grounded SAM can be utilized to detect camouflaged humans in challenging environments, without the need for extensive labeled training data.
- The proposed method leverages self-supervised learning techniques to effectively learn visual representations, enabling efficient and reliable detection of camouflaged individuals.
Plain English Explanation
The paper discusses a technique for automatically detecting people who are trying to hide or camouflage themselves, without requiring a lot of labeled example data to train the system. The key idea is to use a model called Grounded SAM, which can learn visual representations in a self-supervised way by aligning image features with semantic information.
This allows the system to learn what camouflaged humans look like, even without having many examples of camouflaged humans labeled in the training data. The Adaptive Guidance Learning for Camouflaged Object Detection and Bootstrapping Autonomous Driving Radars with Self-Supervised Learning papers explore related self-supervised techniques for detecting camouflaged objects.
The advantage of this self-supervised approach is that it can work well even when there isn't a large dataset of labeled camouflaged human examples available. This makes it a more "frugal" or efficient way to build a camouflaged human detection system. The Shifting Spotlight: Co-Supervision for Simple Yet Efficient paper also discusses efficient ways to leverage limited labeled data.
Overall, this research aims to provide a practical solution for detecting people trying to hide or blend into their surroundings, which could have important applications in fields like security and surveillance.
Technical Explanation
The paper proposes a Grounded Semantic Alignment Model (Grounded SAM) for self-supervised frugal camouflaged human detection. Grounded SAM leverages self-supervised learning to effectively learn visual representations, enabling efficient and reliable detection of camouflaged individuals.
The key components of the Grounded SAM architecture include:
- A Vision Encoder that learns to extract visual features from input images.
- A Language Encoder that encodes semantic information from text descriptions.
- A Cross-Modal Alignment Module that aligns the visual and semantic representations, enabling the model to ground image features to corresponding text.
During training, the model is optimized to maximize the alignment between visual and semantic representations, without requiring any labeled data for camouflaged humans. This self-supervised learning approach allows the model to learn robust visual features that are predictive of camouflaged human presence, even in challenging environments.
The authors evaluate the Grounded SAM approach on several camouflaged human detection benchmarks, demonstrating its effectiveness compared to supervised baselines. The Improving Generalization for Segmentation Foundation Model under Distribution Shift paper discusses related challenges in generalizing detection models to new environments.
Critical Analysis
The paper presents a compelling approach for self-supervised camouflaged human detection, which addresses an important practical challenge. The key strength of the Grounded SAM model is its ability to learn effective visual representations without relying on extensive labeled training data, making it a more "frugal" solution.
However, the paper does not provide a detailed analysis of the limitations or potential failure modes of the proposed approach. For example, it would be useful to understand how the model's performance might degrade in highly complex or adversarial camouflage scenarios, or how sensitive it is to variations in lighting, occlusion, or background clutter.
Additionally, the Collecting Consistently High-Quality Object Tracks with Minimal paper highlights the importance of data quality in training effective detection models, which could be an area for further investigation in the context of this research.
Overall, the paper makes a valuable contribution to the field of camouflaged object detection, but additional research and analysis would be needed to fully assess the practical limitations and potential real-world applications of the Grounded SAM approach.
Conclusion
This research paper presents a novel self-supervised framework for camouflaged human detection using a Grounded Semantic Alignment Model (Grounded SAM). By leveraging self-supervised learning techniques, the proposed approach can effectively learn visual representations without relying on extensive labeled training data, making it a more efficient and practical solution for real-world deployment.
The key insights from this work could have important implications for fields such as security, surveillance, and search and rescue operations, where the ability to reliably detect camouflaged individuals is crucial. While the paper demonstrates the effectiveness of Grounded SAM, further research is needed to fully understand its limitations and explore ways to improve its robustness in challenging environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
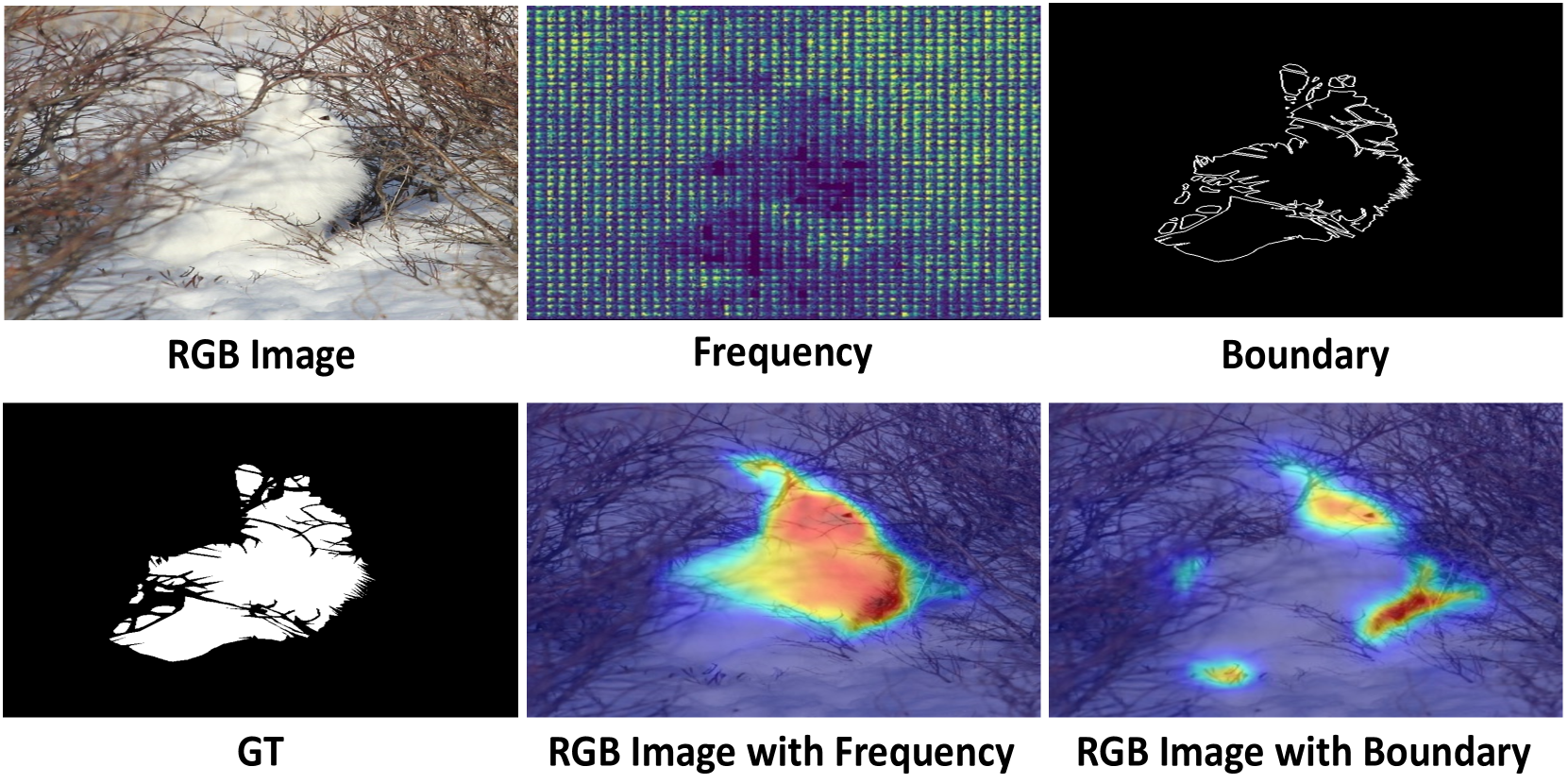
Adaptive Guidance Learning for Camouflaged Object Detection
Zhennan Chen, Xuying Zhang, Tian-Zhu Xiang, Ying Tai
0
0
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
5/8/2024
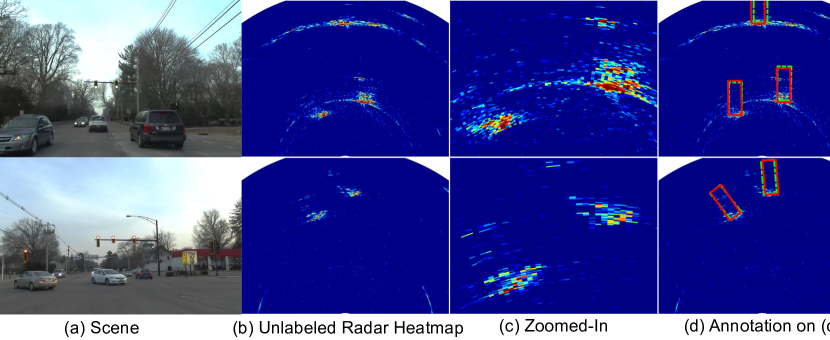
Bootstrapping Autonomous Driving Radars with Self-Supervised Learning
Yiduo Hao, Sohrab Madani, Junfeng Guan, Mohammed Alloulah, Saurabh Gupta, Haitham Hassanieh
0
0
The perception of autonomous vehicles using radars has attracted increased research interest due its ability to operate in fog and bad weather. However, training radar models is hindered by the cost and difficulty of annotating large-scale radar data. To overcome this bottleneck, we propose a self-supervised learning framework to leverage the large amount of unlabeled radar data to pre-train radar-only embeddings for self-driving perception tasks. The proposed method combines radar-to-radar and radar-to-vision contrastive losses to learn a general representation from unlabeled radar heatmaps paired with their corresponding camera images. When used for downstream object detection, we demonstrate that the proposed self-supervision framework can improve the accuracy of state-of-the-art supervised baselines by $5.8%$ in mAP. Code is available at url{https://github.com/yiduohao/Radical}.
4/19/2024

Shifting Spotlight for Co-supervision: A Simple yet Efficient Single-branch Network to See Through Camouflage
Yang Hu, Jinxia Zhang, Kaihua Zhang, Yin Yuan
0
0
Efficient and accurate camouflaged object detection (COD) poses a challenge in the field of computer vision. Recent approaches explored the utility of edge information for network co-supervision, achieving notable advancements. However, these approaches introduce an extra branch for complex edge extraction, complicate the model architecture and increases computational demands. Addressing this issue, our work replicates the effect that animal's camouflage can be easily revealed under a shifting spotlight, and leverages it for network co-supervision to form a compact yet efficient single-branch network, the Co-Supervised Spotlight Shifting Network (CS$^3$Net). The spotlight shifting strategy allows CS$^3$Net to learn additional prior within a single-branch framework, obviating the need for resource demanding multi-branch design. To leverage the prior of spotlight shifting co-supervision, we propose Shadow Refinement Module (SRM) and Projection Aware Attention (PAA) for feature refinement and enhancement. To ensure the continuity of multi-scale features aggregation, we utilize the Extended Neighbor Connection Decoder (ENCD) for generating the final predictions. Empirical evaluations on public datasets confirm that our CS$^3$Net offers an optimal balance between efficiency and performance: it accomplishes a 32.13% reduction in Multiply-Accumulate (MACs) operations compared to leading efficient COD models, while also delivering superior performance.
4/16/2024
🏷️
Collecting Consistently High Quality Object Tracks with Minimal Human Involvement by Using Self-Supervised Learning to Detect Tracker Errors
Samreen Anjum, Suyog Jain, Danna Gurari
0
0
We propose a hybrid framework for consistently producing high-quality object tracks by combining an automated object tracker with little human input. The key idea is to tailor a module for each dataset to intelligently decide when an object tracker is failing and so humans should be brought in to re-localize an object for continued tracking. Our approach leverages self-supervised learning on unlabeled videos to learn a tailored representation for a target object that is then used to actively monitor its tracked region and decide when the tracker fails. Since labeled data is not needed, our approach can be applied to novel object categories. Experiments on three datasets demonstrate our method outperforms existing approaches, especially for small, fast moving, or occluded objects.
5/7/2024