Vanishing Variance Problem in Fully Decentralized Neural-Network Systems
2404.04616
0
0
Abstract
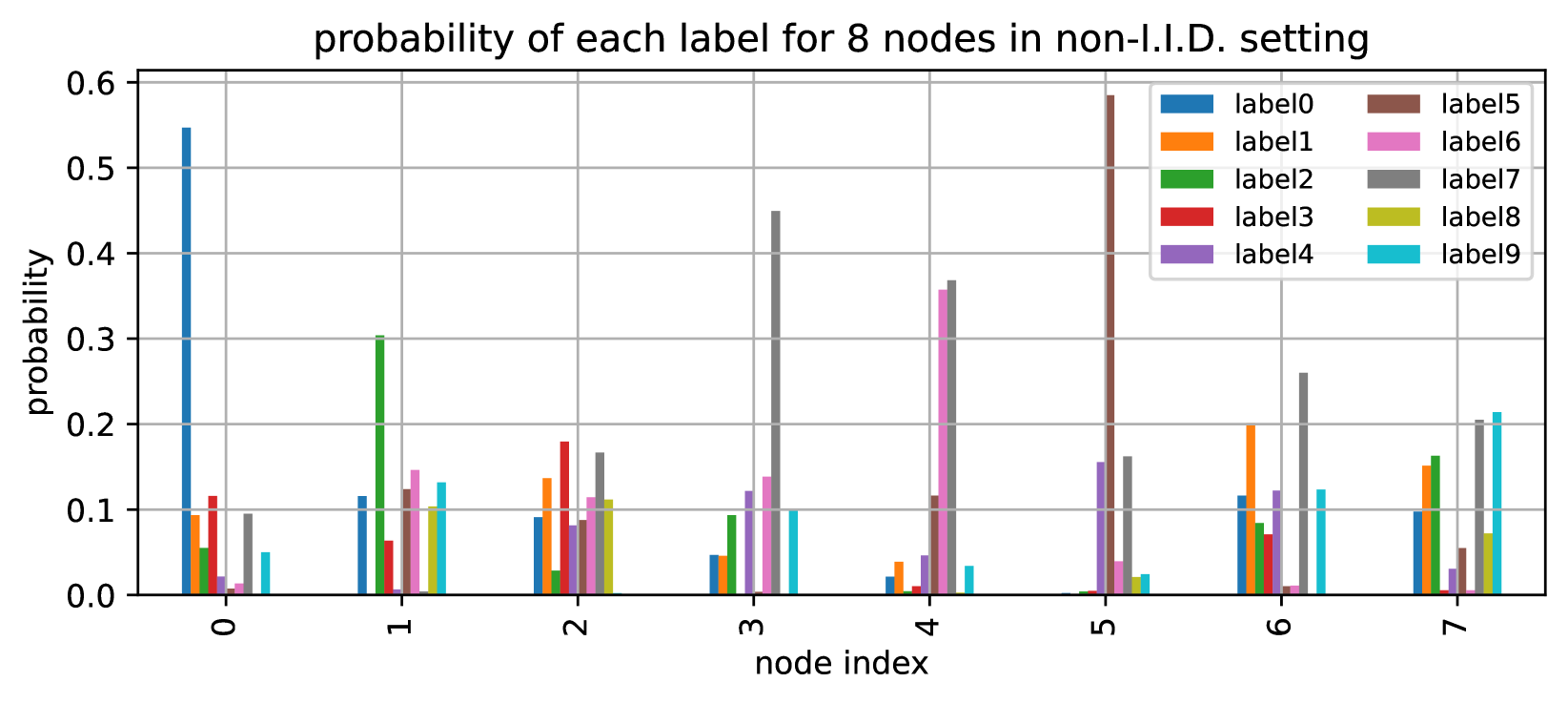
Federated learning and gossip learning are emerging methodologies designed to mitigate data privacy concerns by retaining training data on client devices and exclusively sharing locally-trained machine learning (ML) models with others. The primary distinction between the two lies in their approach to model aggregation: federated learning employs a centralized parameter server, whereas gossip learning adopts a fully decentralized mechanism, enabling direct model exchanges among nodes. This decentralized nature often positions gossip learning as less efficient compared to federated learning. Both methodologies involve a critical step: computing a representation of received ML models and integrating this representation into the existing model. Conventionally, this representation is derived by averaging the received models, exemplified by the FedAVG algorithm. Our findings suggest that this averaging approach inherently introduces a potential delay in model convergence. We identify the underlying cause and refer to it as the vanishing variance problem, where averaging across uncorrelated ML models undermines the optimal variance established by the Xavier weight initialization. Unlike federated learning where the central server ensures model correlation, and unlike traditional gossip learning which circumvents this problem through model partitioning and sampling, our research introduces a variance-corrected model averaging algorithm. This novel algorithm preserves the optimal variance needed during model averaging, irrespective of network topology or non-IID data distributions. Our extensive simulation results demonstrate that our approach enables gossip learning to achieve convergence efficiency comparable to that of federated learning.
Create account to get full access
Overview
- This paper investigates the "vanishing variance problem" in fully decentralized neural network systems, which can hinder the training of such systems.
- The authors propose a solution to address this problem by introducing a novel normalization technique called "Layer-Wise Variance Normalization" (LWVN).
- The paper presents theoretical analysis and empirical evaluations to demonstrate the effectiveness of LWVN in improving the performance of decentralized neural networks.
Plain English Explanation
Neural networks are a type of machine learning model that can be trained to perform various tasks, such as image recognition or language processing. In a traditional neural network, the model is trained on a central server using a large dataset.
However, in some cases, the data may be distributed across many different devices, such as smartphones or IoT sensors. This is known as a "decentralized" neural network system. Training a neural network in a decentralized setting can be challenging due to the "vanishing variance problem."
The vanishing variance problem occurs when the variance (or spread) of the data used to train the neural network becomes too small, making it difficult for the model to learn effectively. This can happen in decentralized systems because the data on each device may be different, and when the model is trained on these different datasets, the variance can decrease over time.
To address this problem, the researchers in this paper propose a new technique called "Layer-Wise Variance Normalization" (LWVN). LWVN works by adjusting the way the neural network processes the data at each layer, to ensure that the variance remains at a suitable level throughout the training process.
The paper presents both theoretical analysis and experimental results to show that LWVN can effectively mitigate the vanishing variance problem and improve the performance of decentralized neural networks.
Technical Explanation
The paper focuses on the "vanishing variance problem" that can occur in fully decentralized neural network systems. This problem arises when the variance of the data used to train the neural network becomes too small, making it difficult for the model to learn effectively.
To address this issue, the authors propose a novel normalization technique called "Layer-Wise Variance Normalization" (LWVN). LWVN works by adjusting the way the neural network processes the data at each layer, to ensure that the variance remains at a suitable level throughout the training process.
The paper presents a theoretical analysis of the vanishing variance problem and how LWVN can help mitigate it. The authors show that LWVN can help maintain a stable and sufficient level of variance in the activations of the neural network, which is crucial for effective training.
The paper also includes extensive empirical evaluations of LWVN on various decentralized neural network architectures and datasets. The results demonstrate that LWVN can significantly improve the performance of decentralized neural networks compared to existing techniques, particularly in scenarios with high heterogeneity in the data across different devices.
Critical Analysis
The paper provides a thorough and well-executed investigation of the vanishing variance problem in decentralized neural network systems. The authors' proposed solution, LWVN, appears to be a promising approach to addressing this challenge.
One potential limitation of the research is the focus on fully decentralized systems, where each device trains its own model independently. In real-world scenarios, there may be some level of coordination or communication between devices, which could potentially mitigate the vanishing variance problem to some extent. It would be interesting to see how LWVN performs in partially decentralized or hybrid architectures.
Additionally, the paper does not explore the computational and memory overhead associated with LWVN, which could be an important practical consideration, especially for resource-constrained devices. Further research on the scalability and efficiency of LWVN would be valuable.
Overall, this paper makes a significant contribution to the field of decentralized machine learning, and the LWVN technique presented could have important implications for the development of robust and effective decentralized neural network systems.
Conclusion
This paper addresses a critical challenge in fully decentralized neural network systems: the vanishing variance problem. The authors propose a novel normalization technique called Layer-Wise Variance Normalization (LWVN) that can effectively mitigate this problem and improve the performance of decentralized neural networks.
The theoretical analysis and empirical evaluations presented in the paper demonstrate the effectiveness of LWVN in maintaining a stable and sufficient level of variance in the neural network activations, which is crucial for effective training. The results show that LWVN can significantly outperform existing techniques, particularly in scenarios with high data heterogeneity across different devices.
While the paper focuses on fully decentralized systems, the insights and techniques presented could have broader implications for the development of robust and scalable decentralized machine learning solutions. Further research on the practical considerations and potential extensions of LWVN could help unlock the full potential of this approach in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Empowering Federated Learning with Implicit Gossiping: Mitigating Connection Unreliability Amidst Unknown and Arbitrary Dynamics
Ming Xiang, Stratis Ioannidis, Edmund Yeh, Carlee Joe-Wong, Lili Su
0
0
Federated learning is a popular distributed learning approach for training a machine learning model without disclosing raw data. It consists of a parameter server and a possibly large collection of clients (e.g., in cross-device federated learning) that may operate in congested and changing environments. In this paper, we study federated learning in the presence of stochastic and dynamic communication failures wherein the uplink between the parameter server and client $i$ is on with unknown probability $p_i^t$ in round $t$. Furthermore, we allow the dynamics of $p_i^t$ to be arbitrary. We first demonstrate that when the $p_i^t$'s vary across clients, the most widely adopted federated learning algorithm, Federated Average (FedAvg), experiences significant bias. To address this observation, we propose Federated Postponed Broadcast (FedPBC), a simple variant of FedAvg. FedPBC differs from FedAvg in that the parameter server postpones broadcasting the global model till the end of each round. Despite uplink failures, we show that FedPBC converges to a stationary point of the original non-convex objective. On the technical front, postponing the global model broadcasts enables implicit gossiping among the clients with active links in round $t$. Despite the time-varying nature of $p_i^t$, we can bound the perturbation of the global model dynamics using techniques to control gossip-type information mixing errors. Extensive experiments have been conducted on real-world datasets over diversified unreliable uplink patterns to corroborate our analysis.
4/17/2024
📈
Federated Learning Model Aggregation in Heterogenous Aerial and Space Networks
Fan Dong, Ali Abbasi, Steve Drew, Henry Leung, Xin Wang, Jiayu Zhou
0
0
Federated learning offers a promising approach under the constraints of networking and data privacy constraints in aerial and space networks (ASNs), utilizing large-scale private edge data from drones, balloons, and satellites. Existing research has extensively studied the optimization of the learning process, computing efficiency, and communication overhead. An important yet often overlooked aspect is that participants contribute predictive knowledge with varying diversity of knowledge, affecting the quality of the learned federated models. In this paper, we propose a novel approach to address this issue by introducing a Weighted Averaging and Client Selection (WeiAvgCS) framework that emphasizes updates from high-diversity clients and diminishes the influence of those from low-diversity clients. Direct sharing of the data distribution may be prohibitive due to the additional private information that is sent from the clients. As such, we introduce an estimation for the diversity using a projection-based method. Extensive experiments have been performed to show WeiAvgCS's effectiveness. WeiAvgCS could converge 46% faster on FashionMNIST and 38% faster on CIFAR10 than its benchmarks on average in our experiments.
4/11/2024
🛠️
Muffliato: Peer-to-Peer Privacy Amplification for Decentralized Optimization and Averaging
Edwige Cyffers, Mathieu Even, Aur'elien Bellet, Laurent Massouli'e
0
0
Decentralized optimization is increasingly popular in machine learning for its scalability and efficiency. Intuitively, it should also provide better privacy guarantees, as nodes only observe the messages sent by their neighbors in the network graph. But formalizing and quantifying this gain is challenging: existing results are typically limited to Local Differential Privacy (LDP) guarantees that overlook the advantages of decentralization. In this work, we introduce pairwise network differential privacy, a relaxation of LDP that captures the fact that the privacy leakage from a node $u$ to a node $v$ may depend on their relative position in the graph. We then analyze the combination of local noise injection with (simple or randomized) gossip averaging protocols on fixed and random communication graphs. We also derive a differentially private decentralized optimization algorithm that alternates between local gradient descent steps and gossip averaging. Our results show that our algorithms amplify privacy guarantees as a function of the distance between nodes in the graph, matching the privacy-utility trade-off of the trusted curator, up to factors that explicitly depend on the graph topology. Finally, we illustrate our privacy gains with experiments on synthetic and real-world datasets.
6/12/2024

Training Diffusion Models with Federated Learning
Matthijs de Goede, Bart Cox, J'er'emie Decouchant
0
0
The training of diffusion-based models for image generation is predominantly controlled by a select few Big Tech companies, raising concerns about privacy, copyright, and data authority due to their lack of transparency regarding training data. To ad-dress this issue, we propose a federated diffusion model scheme that enables the independent and collaborative training of diffusion models without exposing local data. Our approach adapts the Federated Averaging (FedAvg) algorithm to train a Denoising Diffusion Model (DDPM). Through a novel utilization of the underlying UNet backbone, we achieve a significant reduction of up to 74% in the number of parameters exchanged during training,compared to the naive FedAvg approach, whilst simultaneously maintaining image quality comparable to the centralized setting, as evaluated by the FID score.
6/19/2024