Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
2406.11196
0
0
Abstract
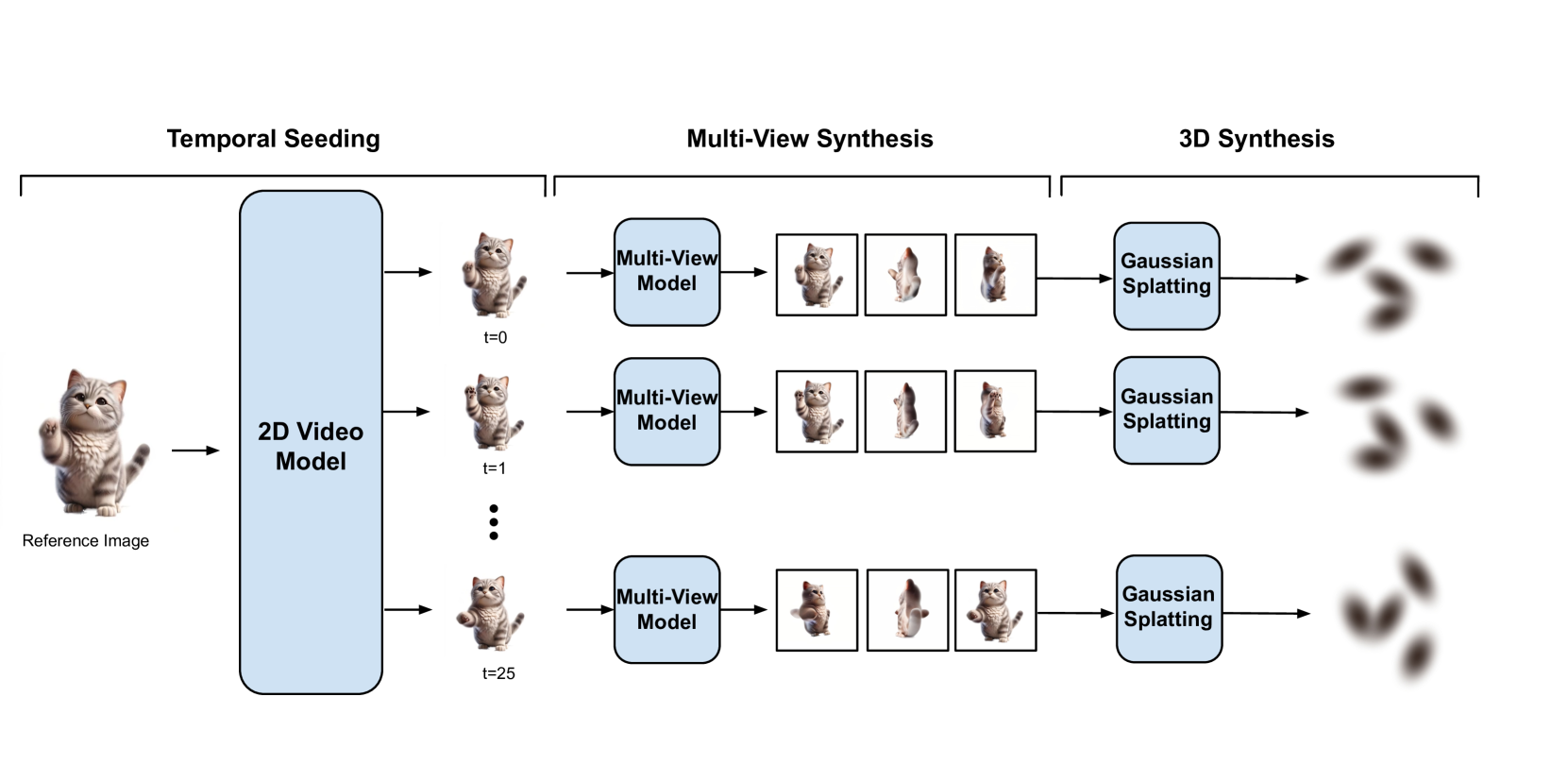
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D seed of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
Create account to get full access
Overview
• This research paper presents a novel method, called Vid3D, for synthesizing dynamic 3D scenes from 2D video inputs using diffusion models. • The key idea is to leverage the powerful image generation capabilities of 2D diffusion models and extend them to the 3D video domain, enabling the synthesis of high-quality 3D animations from simple 2D video clips. • This approach opens up possibilities for various applications, such as 3D video generation, 4D scene modeling, and multi-view video synthesis.
Plain English Explanation
The researchers have developed a new method called Vid3D that can create 3D animated scenes from 2D video clips. The key idea is to use powerful AI models called diffusion models, which are great at generating high-quality images. The researchers found a way to extend these 2D diffusion models to work with 3D video data, allowing them to synthesize dynamic 3D scenes from simple 2D videos.
This is an exciting development because it opens up new possibilities for various applications. For example, it could be used to generate 3D videos or even 4D scenes that include movement over time. It could also be used to create multi-view video where you can see a scene from different angles.
Technical Explanation
The researchers propose a novel method called Vid3D that leverages the power of 2D diffusion models to synthesize dynamic 3D scenes from 2D video inputs. Diffusion models have demonstrated impressive image generation capabilities, and the key insight here is to extend these models to the 3D video domain.
The core of the Vid3D approach involves three key steps:
- 3D Reconstruction: The method first reconstructs a 3D representation of the scene from the 2D video input using multi-view techniques.
- Diffusion-based Generation: A 3D diffusion model is then trained to generate dynamic 3D scenes conditioned on the reconstructed 3D representation and the original 2D video.
- Refinement and Rendering: The generated 3D content is further refined and rendered to produce the final dynamic 3D scene.
The researchers explore several architectural choices and training techniques to make this approach effective, including the use of 3D convolutions, temporal modeling, and iterative refinement. Through extensive experiments, they demonstrate the ability of Vid3D to synthesize high-quality dynamic 3D scenes from a variety of 2D video inputs.
Critical Analysis
The Vid3D approach represents an exciting advancement in the field of 3D video synthesis, leveraging the impressive capabilities of diffusion models in a novel way. However, the paper also acknowledges several limitations and areas for further research:
-
Reconstruction Accuracy: The quality of the final 3D scenes is heavily dependent on the accuracy of the initial 3D reconstruction from the 2D video input. Improving 3D reconstruction techniques could further enhance the realism of the generated content.
-
Temporal Consistency: While the researchers address temporal modeling in their approach, maintaining long-term temporal consistency in the generated 3D animations remains a challenge that requires further investigation.
-
Scalability: The computational and memory requirements of the 3D diffusion model may limit the scalability of the approach to handling larger or more complex scenes. Exploring more efficient architectures or alternate modeling techniques could help address this issue.
-
Evaluation Metrics: The paper relies primarily on qualitative assessments and user studies to evaluate the generated 3D content. Developing more robust and comprehensive quantitative metrics for 3D video synthesis could provide a more objective assessment of the method's performance.
Despite these limitations, the Vid3D method represents a significant step forward in the field of 3D video synthesis, and the researchers have demonstrated its potential through compelling results. Continued research in this direction could lead to further advancements and broader applications in areas such as virtual and augmented reality, film and animation, and beyond.
Conclusion
The Vid3D research paper presents a novel approach for synthesizing dynamic 3D scenes from 2D video inputs using diffusion models. By extending the powerful image generation capabilities of 2D diffusion models to the 3D video domain, the researchers have opened up new possibilities for various applications, including 3D video generation, 4D scene modeling, and multi-view video synthesis.
The core technical approach involves 3D reconstruction, diffusion-based generation, and refinement, demonstrating the ability to synthesize high-quality dynamic 3D scenes from diverse 2D video inputs. While the method has some limitations, such as reconstruction accuracy and temporal consistency, the overall results and potential applications are highly promising. Further research in this direction could lead to even more advanced and impactful developments in the field of 3D video synthesis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion$^2$: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
Zeyu Yang, Zijie Pan, Chun Gu, Li Zhang
0
0
Recent advancements in 3D generation are predominantly propelled by improvements in 3D-aware image diffusion models which are pretrained on Internet-scale image data and fine-tuned on massive 3D data, offering the capability of producing highly consistent multi-view images. However, due to the scarcity of synchronized multi-view video data, it is impractical to adapt this paradigm to 4D generation directly. Despite that, the available video and 3D data are adequate for training video and multi-view diffusion models separately that can provide satisfactory dynamic and geometric priors respectively. To take advantage of both, this paper present Diffusion$^2$, a novel framework for dynamic 3D content creation that reconciles the knowledge about geometric consistency and temporal smoothness from these models to directly sample dense multi-view multi-frame images which can be employed to optimize continuous 4D representation. Specifically, we design a simple yet effective denoising strategy via score composition of pretrained video and multi-view diffusion models based on the probability structure of the target image array. Owing to the high parallelism of the proposed image generation process and the efficiency of the modern 4D reconstruction pipeline, our framework can generate 4D content within few minutes. Additionally, our method circumvents the reliance on 4D data, thereby having the potential to benefit from the scaling of the foundation video and multi-view diffusion models. Extensive experiments demonstrate the efficacy of our proposed framework and its ability to flexibly handle various types of prompts.
5/24/2024
🛸
4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models
Heng Yu, Chaoyang Wang, Peiye Zhuang, Willi Menapace, Aliaksandr Siarohin, Junli Cao, Laszlo A Jeni, Sergey Tulyakov, Hsin-Ying Lee
0
0
Existing dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets. As a result, the generated scenes are often object-centric and lack photorealism. To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets. Our method begins by generating a reference video using the video generation model. We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video. To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections. We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video. The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation.
6/12/2024

Vivid-ZOO: Multi-View Video Generation with Diffusion Model
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, Bernard Ghanem
0
0
While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
6/14/2024

Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
Hanwen Liang, Yuyang Yin, Dejia Xu, Hanxue Liang, Zhangyang Wang, Konstantinos N. Plataniotis, Yao Zhao, Yunchao Wei
0
0
The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple image or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, textbf{Diffusion4D}, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. The synthesized multi-view consistent 4D image set enables us to swiftly generate high-fidelity and diverse 4D assets within just several minutes. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.
5/28/2024