VILA: On Pre-training for Visual Language Models
2312.07533
2
0

Abstract
Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
Create account to get full access
Overview
- This paper introduces VILA, a framework for pre-training visual language models.
- VILA aims to improve the performance of vision-language models by incorporating more diverse training data and more comprehensive pre-training tasks.
- The paper explores different training strategies and model architectures for effectively combining visual and language information.
Plain English Explanation
The researchers behind this paper have developed a new approach called VILA (Visual-Language Pre-training) to help improve the performance of models that work with both images and text. These types of "vision-language" models are used for tasks like image captioning, visual question answering, and multimodal understanding.
The key idea is that by doing more comprehensive pre-training - that is, training the model on a wider variety of data and tasks before applying it to a specific application - the model can learn richer representations that allow it to perform better on downstream tasks. The VILA framework explores different ways to structure the model architecture and the pre-training process to most effectively combine the visual and language information.
For example, the model might be pre-trained on a large dataset of images paired with captions, as well as other tasks like predicting which words are relevant to an image. By learning these kinds of multimodal associations during pre-training, the model can then apply that knowledge more effectively when faced with new image-text problems.
The paper experiments with different model designs and pre-training setups to understand what works best for boosting the performance of vision-language models. The goal is to help advance the state-of-the-art in this important area of artificial intelligence research.
Technical Explanation
The VILA framework explores different model architectures and training strategies for effectively combining visual and language information during pre-training of vision-language models.
<a href="https://aimodels.fyi/papers/arxiv/unified-video-language-pre-training-synchronized-audio">Previous work</a> has shown the benefits of pre-training vision-language models on large-scale datasets and diverse tasks. VILA builds on this by investigating more comprehensive pre-training approaches.
The paper evaluates different model designs, including:
- <a href="https://aimodels.fyi/papers/arxiv/mm1-methods-analysis-insights-from-multimodal-llm">Multi-stream architectures</a> that process visual and language inputs separately before combining them
- <a href="https://aimodels.fyi/papers/arxiv/what-matters-when-building-vision-language-models">Single-stream architectures</a> that jointly encode the visual and language inputs
Additionally, the authors explore different pre-training tasks beyond just image-text matching, such as:
- Predicting relevant words for a given image
- Generating captions for images
- Aligning visual and language representations
The paper presents extensive experiments comparing these different model designs and pre-training setups on a range of vision-language benchmarks. The results demonstrate that the VILA framework can lead to significant performance improvements, highlighting the value of comprehensive pre-training for vision-language models.
Critical Analysis
The VILA paper makes a valuable contribution by systematically exploring how to effectively pre-train vision-language models. The authors' focus on expanding the pre-training data and tasks is well-motivated, as <a href="https://aimodels.fyi/papers/arxiv/revisiting-role-language-priors-vision-language-models">prior research</a> has shown the importance of rich multimodal representations for these models.
That said, the paper does not delve deeply into the underlying reasons why certain architectural choices or pre-training approaches work better than others. More analysis on the specific inductive biases and learning dynamics introduced by the different model designs and pre-training setups could provide additional insights.
Additionally, the paper does not address potential limitations or negative societal impacts of the VILA framework. As vision-language models become more capable, it will be important to <a href="https://aimodels.fyi/papers/arxiv/exploring-frontier-vision-language-models-survey-current">carefully consider</a> issues like biases, privacy, and ethical deployment.
Overall, the VILA paper represents a promising step forward in advancing the state-of-the-art in vision-language pre-training. Further research building on this work could lead to even more capable and robust multimodal models.
Conclusion
The VILA paper introduces a framework for more comprehensive pre-training of vision-language models. By exploring diverse architectural choices and pre-training tasks, the researchers demonstrate significant performance gains on a range of vision-language benchmarks.
This work highlights the importance of rich multimodal representations for tasks that involve both visual and language understanding. As vision-language models continue to grow in capability, the VILA approach could help unlock new applications and insights at the intersection of computer vision and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh
0
0
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization, and challenge sets that probe properties such as hallucination; evaluations that provide fine-grained insight VLM capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and training from base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible training code, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open VLMs.
5/31/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024
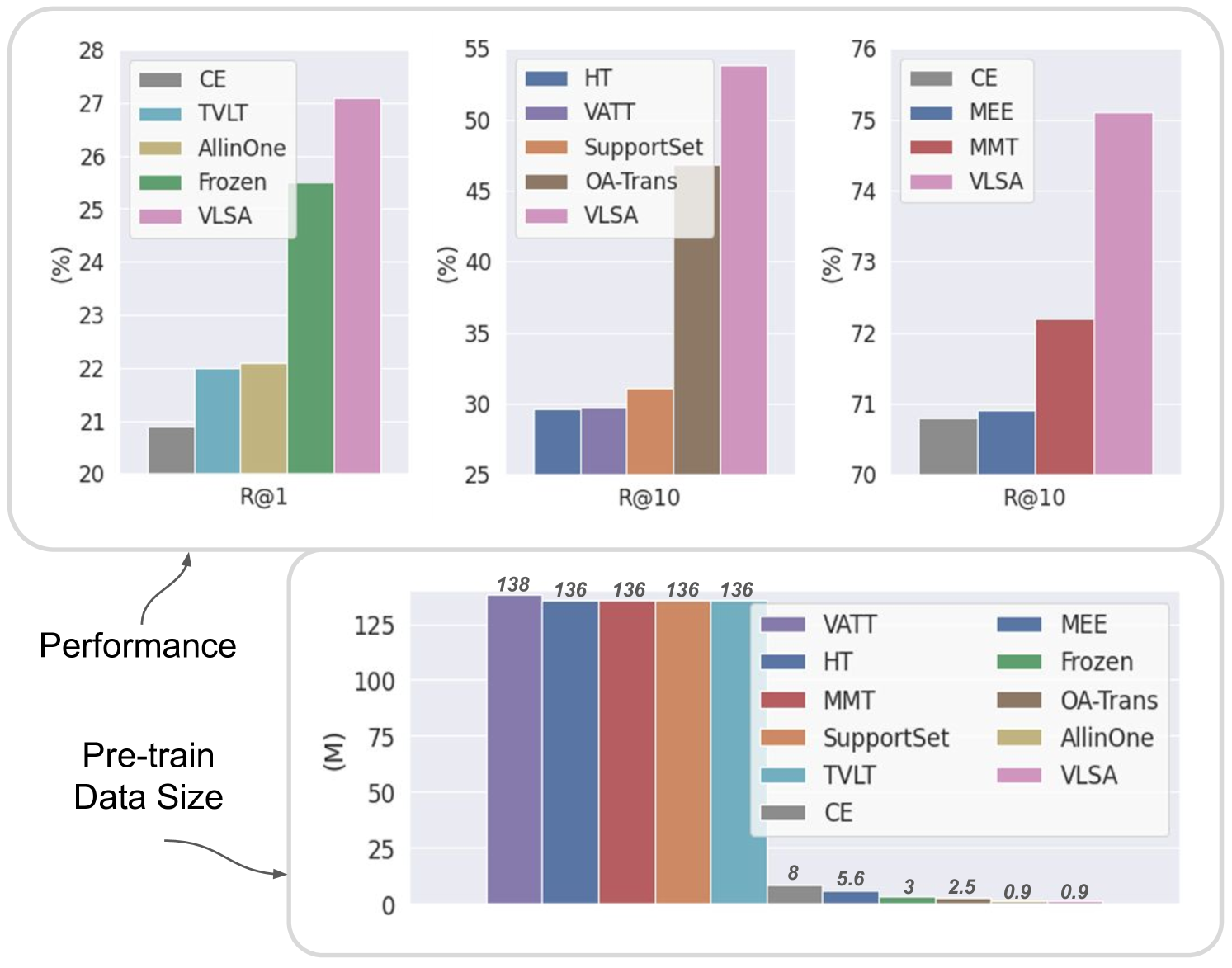
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024
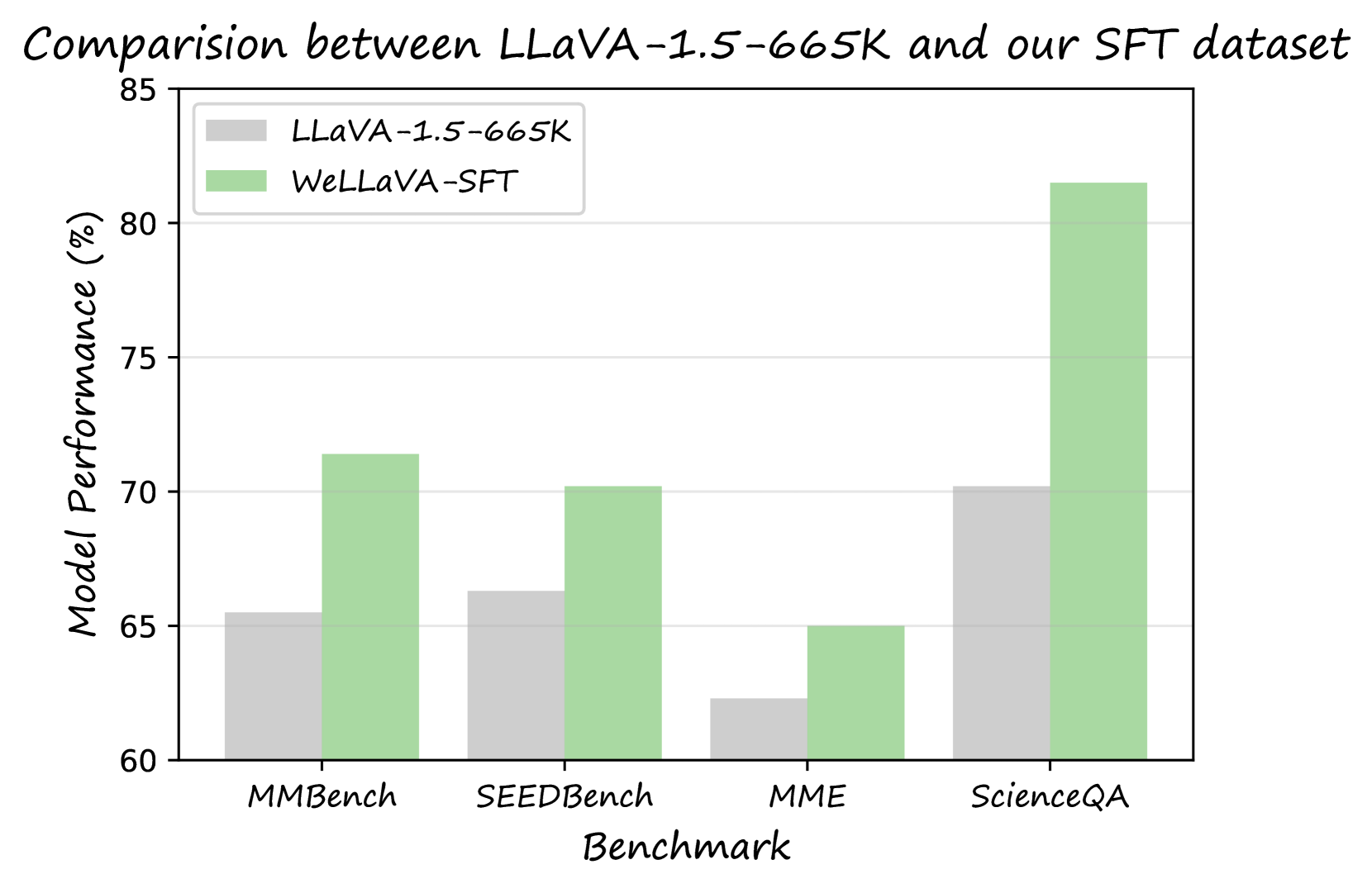
Rethinking Overlooked Aspects in Vision-Language Models
Yuan Liu, Le Tian, Xiao Zhou, Jie Zhou
0
0
Recent advancements in large vision-language models (LVLMs), such as GPT4-V and LLaVA, have been substantial. LLaVA's modular architecture, in particular, offers a blend of simplicity and efficiency. Recent works mainly focus on introducing more pre-training and instruction tuning data to improve model's performance. This paper delves into the often-neglected aspects of data efficiency during pre-training and the selection process for instruction tuning datasets. Our research indicates that merely increasing the size of pre-training data does not guarantee improved performance and may, in fact, lead to its degradation. Furthermore, we have established a pipeline to pinpoint the most efficient instruction tuning (SFT) dataset, implying that not all SFT data utilized in existing studies are necessary. The primary objective of this paper is not to introduce a state-of-the-art model, but rather to serve as a roadmap for future research, aiming to optimize data usage during pre-training and fine-tuning processes to enhance the performance of vision-language models.
5/21/2024