Vision Mamba: A Comprehensive Survey and Taxonomy
2405.04404
0
0
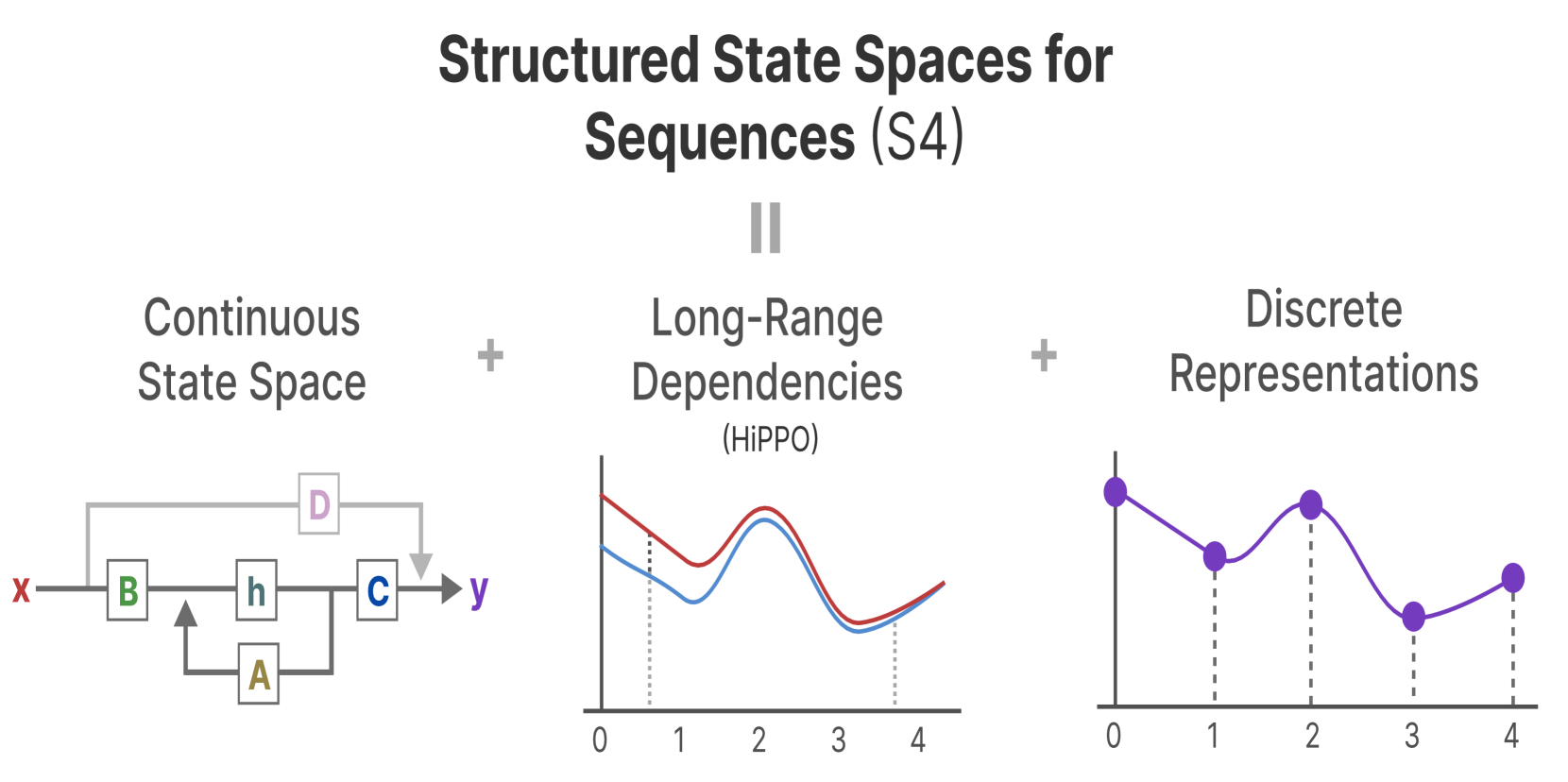
Abstract
State Space Model (SSM) is a mathematical model used to describe and analyze the behavior of dynamic systems. This model has witnessed numerous applications in several fields, including control theory, signal processing, economics and machine learning. In the field of deep learning, state space models are used to process sequence data, such as time series analysis, natural language processing (NLP) and video understanding. By mapping sequence data to state space, long-term dependencies in the data can be better captured. In particular, modern SSMs have shown strong representational capabilities in NLP, especially in long sequence modeling, while maintaining linear time complexity. Notably, based on the latest state-space models, Mamba merges time-varying parameters into SSMs and formulates a hardware-aware algorithm for efficient training and inference. Given its impressive efficiency and strong long-range dependency modeling capability, Mamba is expected to become a new AI architecture that may outperform Transformer. Recently, a number of works have attempted to study the potential of Mamba in various fields, such as general vision, multi-modal, medical image analysis and remote sensing image analysis, by extending Mamba from natural language domain to visual domain. To fully understand Mamba in the visual domain, we conduct a comprehensive survey and present a taxonomy study. This survey focuses on Mamba's application to a variety of visual tasks and data types, and discusses its predecessors, recent advances and far-reaching impact on a wide range of domains. Since Mamba is now on an upward trend, please actively notice us if you have new findings, and new progress on Mamba will be included in this survey in a timely manner and updated on the Mamba project at https://github.com/lx6c78/Vision-Mamba-A-Comprehensive-Survey-and-Taxonomy.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a comprehensive survey and taxonomy of the "Vision Mamba" framework, which is a state-space model for computer vision applications.
- It covers the formulation of the Mamba model, its applications in various domains like medical image analysis and remote sensing, and the key challenges and future research directions in this area.
Plain English Explanation
The research paper provides a detailed overview of the "Vision Mamba" framework, which is a mathematical model used in computer vision applications. Vision Mamba: A Comprehensive Survey and Taxonomy explains the core concepts behind this model and how it can be applied to different tasks, such as analyzing medical images or satellite imagery.
The Mamba model is a type of "state-space model," which means it represents the visual information in an image or video as a series of hidden "states" that evolve over time. This allows the model to capture the dynamic and complex nature of visual data, compared to more static approaches.
The paper goes on to discuss how Mamba has been used in a wide range of computer vision applications, from diagnosing medical conditions to monitoring environmental changes. It also highlights the key challenges and areas for future research in this field, such as improving the model's ability to handle occlusions, noise, and other practical issues.
Overall, the "Vision Mamba" framework represents a promising approach to solving many computer vision problems, and this survey paper provides a comprehensive overview of its capabilities and potential future developments.
Technical Explanation
The paper presents a comprehensive survey and taxonomy of the "Vision Mamba" framework, which is a state-space model for computer vision applications. Mamba: A Comprehensive Survey and Taxonomy of State-Space Models in Computer Vision introduces the core formulation of the Mamba model and discusses its applications in various domains, including medical image analysis and remote sensing.
The Mamba model is a state-space representation that can effectively capture the dynamic and complex nature of visual data. It represents the visual information in an image or video as a series of hidden "states" that evolve over time, allowing the model to adapt to changes and dependencies within the data.
The paper examines how the Mamba framework has been applied to a wide range of computer vision tasks, such as 360-degree image analysis, local image enhancement, and general visual recognition. It provides a detailed taxonomy of the various Mamba-based models and their key characteristics, highlighting the strengths and limitations of each approach.
Critical Analysis
The paper provides a comprehensive overview of the "Vision Mamba" framework and its applications, but it also acknowledges several challenges and limitations that require further research.
One key limitation mentioned is the model's ability to handle occlusions, noise, and other practical issues that can arise in real-world computer vision scenarios. The paper suggests that future work should focus on developing more robust and adaptive Mamba-based models to address these challenges.
Additionally, the survey highlights the need for more extensive empirical evaluations of the Mamba framework across a wider range of applications and datasets. While the paper showcases several successful use cases, it would be beneficial to see a more systematic and comparative analysis of the model's performance compared to other state-of-the-art approaches.
Overall, the "Vision Mamba" framework appears to be a promising direction in computer vision research, but the paper rightly identifies areas for improvement and further exploration to enhance the model's versatility and practical impact.
Conclusion
The research paper presents a thorough survey and taxonomy of the "Vision Mamba" framework, a state-space model for computer vision applications. It explains the core formulation of the Mamba model and discusses its successful deployment in various domains, such as medical image analysis and remote sensing.
The paper highlights the Mamba model's ability to capture the dynamic and complex nature of visual data, which sets it apart from more static approaches. It also outlines the key challenges and future research directions in this field, including the need to improve the model's robustness to practical issues and to conduct more extensive empirical evaluations.
Overall, the "Vision Mamba" framework represents an exciting development in the field of computer vision, and this survey paper provides researchers and practitioners with a comprehensive understanding of its capabilities, applications, and areas for further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
0
0
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
4/29/2024
A Survey on Vision Mamba: Models, Applications and Challenges
Rui Xu, Shu Yang, Yihui Wang, Bo Du, Hao Chen
0
0
Mamba, a recent selective structured state space model, performs excellently on long sequence modeling tasks. Mamba mitigates the modeling constraints of convolutional neural networks and offers advanced modeling capabilities similar to those of Transformers, through global receptive fields and dynamic weighting. Crucially, it achieves this without incurring the quadratic computational complexity typically associated with Transformers. Due to its advantages over the former two mainstream foundation models, Mamba exhibits great potential to be a visual foundation model. Researchers are actively applying Mamba to various computer vision tasks, leading to numerous emerging works. To help keep pace with the rapid advancements in computer vision, this paper aims to provide a comprehensive review of visual Mamba approaches. This paper begins by delineating the formulation of the original Mamba model. Subsequently, our review of visual Mamba delves into several representative backbone networks to elucidate the core insights of the visual Mamba. We then categorize related works using different modalities, including image, video, point cloud, multi-modal, and others. Specifically, for image applications, we further organize them into distinct tasks to facilitate a more structured discussion. Finally, we discuss the challenges and future research directions for visual Mamba, providing insights for future research in this quickly evolving area. A comprehensive list of visual Mamba models reviewed in this work is available at https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models.
4/30/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024
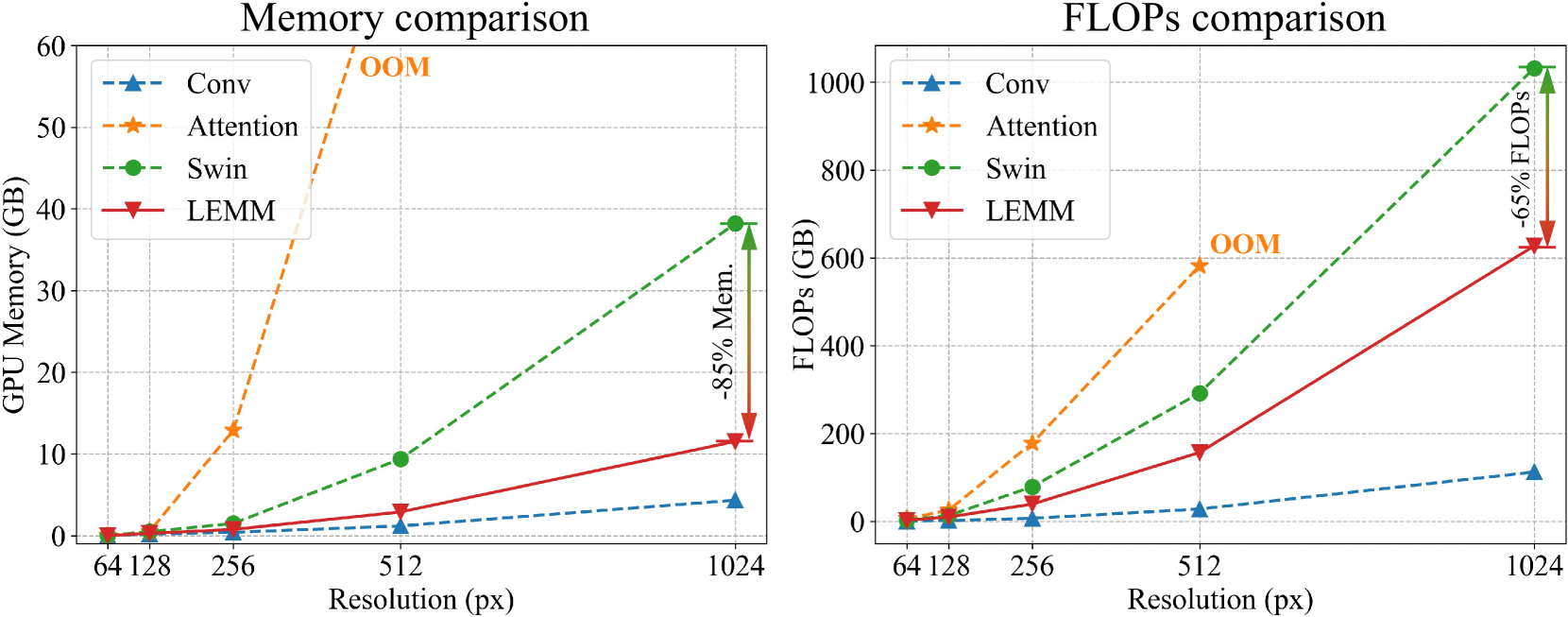
A Novel State Space Model with Local Enhancement and State Sharing for Image Fusion
Zihan Cao, Xiao Wu, Liang-Jian Deng, Yu Zhong
0
0
In image fusion tasks, images from different sources possess distinct characteristics. This has driven the development of numerous methods to explore better ways of fusing them while preserving their respective characteristics. Mamba, as a state space model, has emerged in the field of natural language processing. Recently, many studies have attempted to extend Mamba to vision tasks. However, due to the nature of images different from casual language sequences, the limited state capacity of Mamba weakens its ability to model image information. Additionally, the sequence modeling ability of Mamba is only capable of spatial information and cannot effectively capture the rich spectral information in images. Motivated by these challenges, we customize and improve the vision Mamba network designed for the image fusion task. Specifically, we propose the local-enhanced vision Mamba block, dubbed as LEVM. The LEVM block can improve local information perception of the network and simultaneously learn local and global spatial information. Furthermore, we propose the state sharing technique to enhance spatial details and integrate spatial and spectral information. Finally, the overall network is a multi-scale structure based on vision Mamba, called LE-Mamba. Extensive experiments show the proposed methods achieve state-of-the-art results on multispectral pansharpening and multispectral and hyperspectral image fusion datasets, and demonstrate the effectiveness of the proposed approach. Code will be made available.
4/16/2024