Vision Transformers in Domain Adaptation and Generalization: A Study of Robustness
2404.04452
0
0

Abstract
Deep learning models are often evaluated in scenarios where the data distribution is different from those used in the training and validation phases. The discrepancy presents a challenge for accurately predicting the performance of models once deployed on the target distribution. Domain adaptation and generalization are widely recognized as effective strategies for addressing such shifts, thereby ensuring reliable performance. The recent promising results in applying vision transformers in computer vision tasks, coupled with advancements in self-attention mechanisms, have demonstrated their significant potential for robustness and generalization in handling distribution shifts. Motivated by the increased interest from the research community, our paper investigates the deployment of vision transformers in domain adaptation and domain generalization scenarios. For domain adaptation methods, we categorize research into feature-level, instance-level, model-level adaptations, and hybrid approaches, along with other categorizations with respect to diverse strategies for enhancing domain adaptation. Similarly, for domain generalization, we categorize research into multi-domain learning, meta-learning, regularization techniques, and data augmentation strategies. We further classify diverse strategies in research, underscoring the various approaches researchers have taken to address distribution shifts by integrating vision transformers. The inclusion of comprehensive tables summarizing these categories is a distinct feature of our work, offering valuable insights for researchers. These findings highlight the versatility of vision transformers in managing distribution shifts, crucial for real-world applications, especially in critical safety and decision-making scenarios.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines the robustness of Vision Transformers (ViTs) in domain adaptation and generalization tasks.
- ViTs have shown promising results in computer vision, but their performance can degrade when applied to new domains.
- The study investigates the factors that impact ViT robustness and explores techniques to improve their generalization capabilities.
Plain English Explanation
Vision Transformers (ViTs) are a type of machine learning model that have been successful in various computer vision tasks, such as image classification and object detection. However, these models can struggle when applied to new datasets or scenarios that differ from the data they were trained on. This is a common challenge in machine learning, known as the domain adaptation and generalization problem.
This paper aims to understand the factors that affect the robustness of ViTs in these types of situations. The researchers investigate how the architecture and training of ViTs can be modified to improve their ability to perform well on a variety of datasets and tasks, even if they were not specifically trained on that data.
By exploring the strengths and weaknesses of ViTs, the researchers hope to provide insights that can help improve the general reliability and versatility of these models, making them more useful in real-world applications where the data may differ from the training set.
Technical Explanation
The paper begins by providing an overview of Vision Transformers and their fundamental architecture. ViTs are a type of neural network that uses self-attention mechanisms, similar to those used in language models, to process visual data. This allows ViTs to capture long-range dependencies and global information, which can be beneficial for various computer vision tasks.
The researchers then dive into investigating the domain adaptation and generalization capabilities of ViTs. They conduct experiments on multiple datasets, including standard benchmarks as well as more challenging, real-world scenarios. The experiments explore factors such as the ViT architecture, training strategies, and the use of pre-training.
The results show that ViTs can struggle with domain shift, where the test data differs significantly from the training data. The paper identifies several key factors that impact ViT robustness, including the size of the model, the amount of pre-training data, and the training strategy used. The researchers also explore techniques like meta-learning and feature-based adaptation to improve ViT performance in domain adaptation and generalization tasks.
Critical Analysis
The paper provides a thorough and insightful analysis of the robustness of ViTs in domain adaptation and generalization tasks. The authors have carefully designed their experiments to cover a range of scenarios, which gives the findings more breadth and relevance.
One potential limitation of the study is the reliance on established benchmark datasets, which may not fully capture the complexities of real-world domain shifts. The researchers acknowledge this and suggest that further exploration of more diverse and challenging datasets could yield additional insights.
Additionally, the paper focuses primarily on identifying the factors that influence ViT robustness, but it does not go into extensive detail on the underlying reasons for these behaviors. Further research could delve deeper into the mechanisms and representations within ViTs that lead to their strengths and weaknesses in these tasks.
Overall, this paper makes a valuable contribution to the understanding of ViT performance and robustness, which is crucial as these models continue to be adopted in various applications. The findings and techniques presented can inform the development of more versatile and reliable computer vision systems.
Conclusion
This study on the domain adaptation and generalization capabilities of Vision Transformers highlights the importance of understanding the robustness of machine learning models, especially as they are deployed in real-world scenarios. The researchers have provided a comprehensive analysis of the factors that influence ViT performance, offering insights that can guide the design and training of these models to improve their general applicability and reliability.
As the field of computer vision continues to evolve, the ability of models to adapt to new data and environments will become increasingly critical. This work on ViT robustness contributes to the ongoing efforts to develop more versatile and trustworthy vision systems, paving the way for their wider adoption in diverse applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
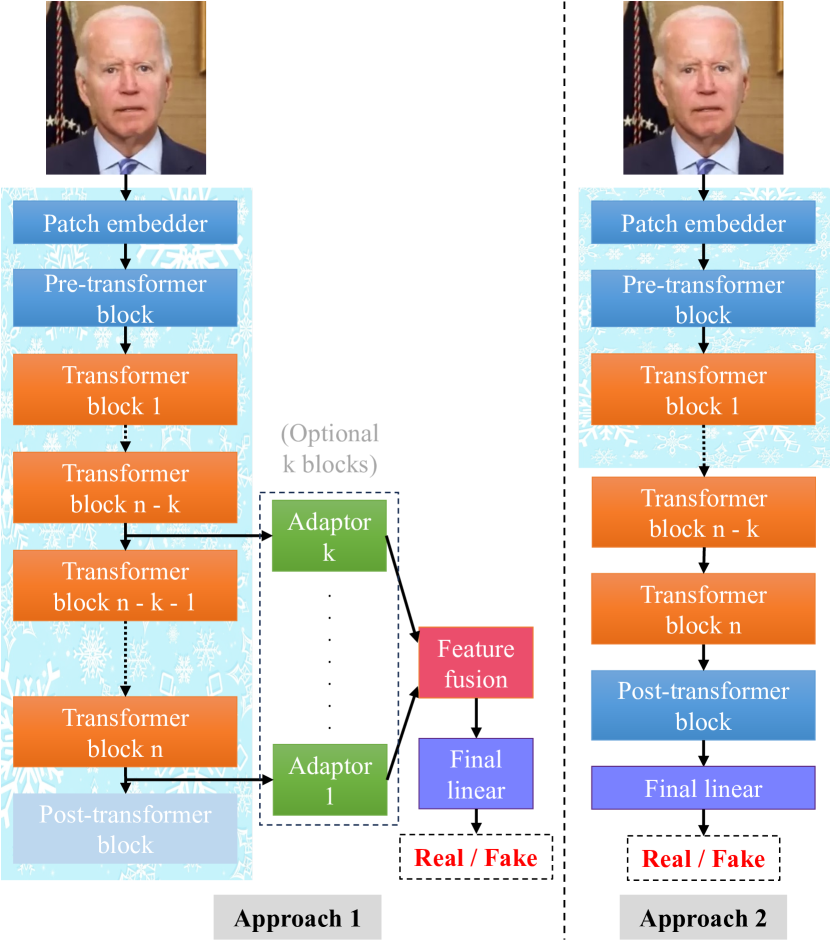
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
0
0
This paper investigates the effectiveness of self-supervised pre-trained transformers compared to supervised pre-trained transformers and conventional neural networks (ConvNets) for detecting various types of deepfakes. We focus on their potential for improved generalization, particularly when training data is limited. Despite the notable success of large vision-language models utilizing transformer architectures in various tasks, including zero-shot and few-shot learning, the deepfake detection community has still shown some reluctance to adopt pre-trained vision transformers (ViTs), especially large ones, as feature extractors. One concern is their perceived excessive capacity, which often demands extensive data, and the resulting suboptimal generalization when training or fine-tuning data is small or less diverse. This contrasts poorly with ConvNets, which have already established themselves as robust feature extractors. Additionally, training and optimizing transformers from scratch requires significant computational resources, making this accessible primarily to large companies and hindering broader investigation within the academic community. Recent advancements in using self-supervised learning (SSL) in transformers, such as DINO and its derivatives, have showcased significant adaptability across diverse vision tasks and possess explicit semantic segmentation capabilities. By leveraging DINO for deepfake detection with modest training data and implementing partial fine-tuning, we observe comparable adaptability to the task and the natural explainability of the detection result via the attention mechanism. Moreover, partial fine-tuning of transformers for deepfake detection offers a more resource-efficient alternative, requiring significantly fewer computational resources.
5/2/2024
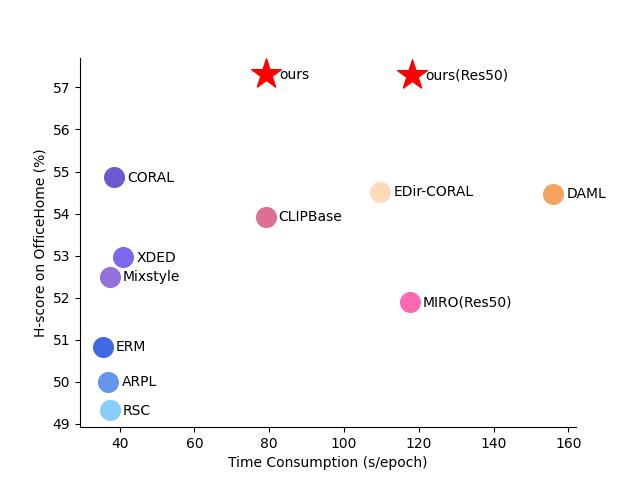
PracticalDG: Perturbation Distillation on Vision-Language Models for Hybrid Domain Generalization
Zining Chen, Weiqiu Wang, Zhicheng Zhao, Fei Su, Aidong Men, Hongying Meng
0
0
Domain Generalization (DG) aims to resolve distribution shifts between source and target domains, and current DG methods are default to the setting that data from source and target domains share identical categories. Nevertheless, there exists unseen classes from target domains in practical scenarios. To address this issue, Open Set Domain Generalization (OSDG) has emerged and several methods have been exclusively proposed. However, most existing methods adopt complex architectures with slight improvement compared with DG methods. Recently, vision-language models (VLMs) have been introduced in DG following the fine-tuning paradigm, but consume huge training overhead with large vision models. Therefore, in this paper, we innovate to transfer knowledge from VLMs to lightweight vision models and improve the robustness by introducing Perturbation Distillation (PD) from three perspectives, including Score, Class and Instance (SCI), named SCI-PD. Moreover, previous methods are oriented by the benchmarks with identical and fixed splits, ignoring the divergence between source domains. These methods are revealed to suffer from sharp performance decay with our proposed new benchmark Hybrid Domain Generalization (HDG) and a novel metric $H^{2}$-CV, which construct various splits to comprehensively assess the robustness of algorithms. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms on multiple datasets, especially improving the robustness when confronting data scarcity.
4/16/2024

Domain Generalization through Meta-Learning: A Survey
Arsham Gholamzadeh Khoee, Yinan Yu, Robert Feldt
0
0
Deep neural networks (DNNs) have revolutionized artificial intelligence but often lack performance when faced with out-of-distribution (OOD) data, a common scenario due to the inevitable domain shifts in real-world applications. This limitation stems from the common assumption that training and testing data share the same distribution-an assumption frequently violated in practice. Despite their effectiveness with large amounts of data and computational power, DNNs struggle with distributional shifts and limited labeled data, leading to overfitting and poor generalization across various tasks and domains. Meta-learning presents a promising approach by employing algorithms that acquire transferable knowledge across various tasks for fast adaptation, eliminating the need to learn each task from scratch. This survey paper delves into the realm of meta-learning with a focus on its contribution to domain generalization. We first clarify the concept of meta-learning for domain generalization and introduce a novel taxonomy based on the feature extraction strategy and the classifier learning methodology, offering a granular view of methodologies. Through an exhaustive review of existing methods and underlying theories, we map out the fundamentals of the field. Our survey provides practical insights and an informed discussion on promising research directions, paving the way for future innovation in meta-learning for domain generalization.
4/4/2024
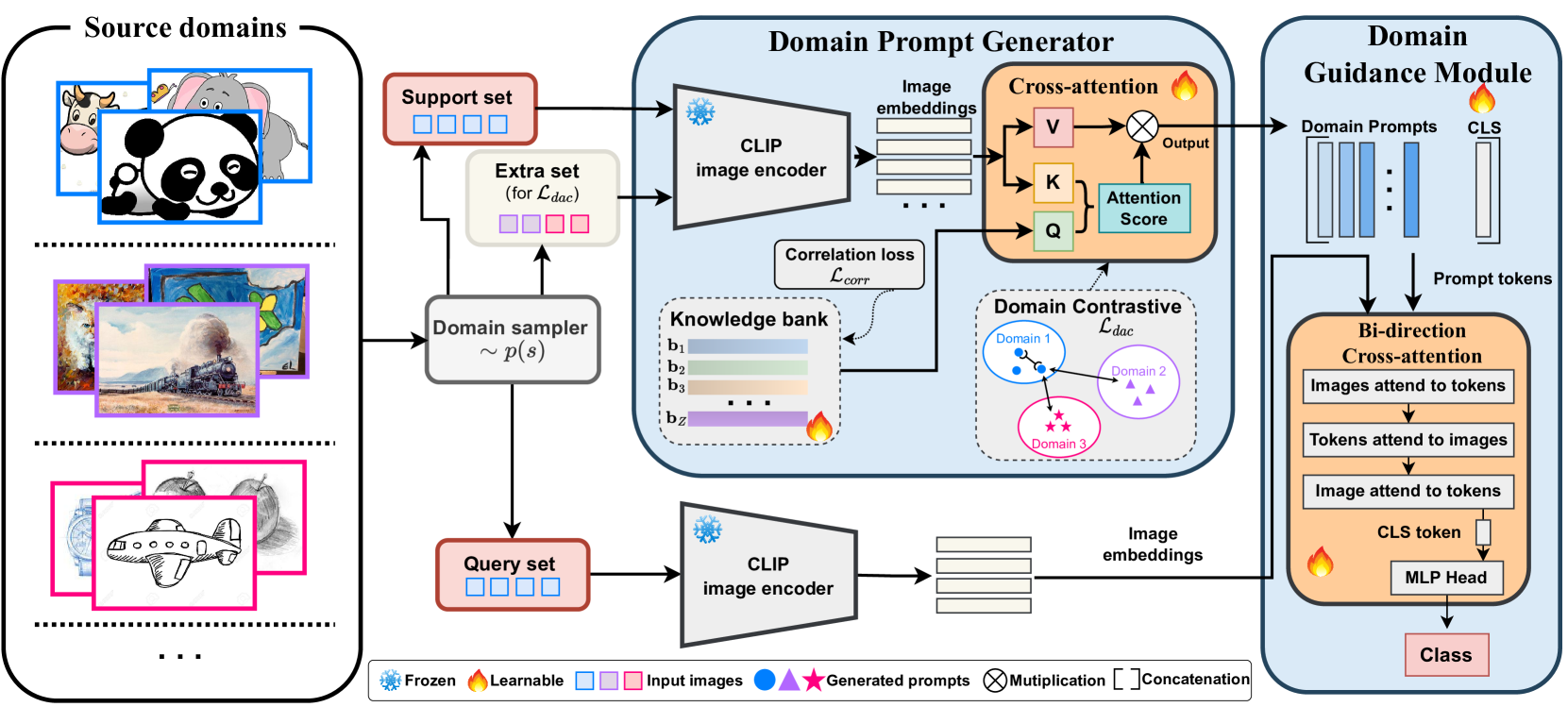
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
0
0
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
5/7/2024