VST++: Efficient and Stronger Visual Saliency Transformer
2310.11725
0
0
Abstract
While previous CNN-based models have exhibited promising results for salient object detection (SOD), their ability to explore global long-range dependencies is restricted. Our previous work, the Visual Saliency Transformer (VST), addressed this constraint from a transformer-based sequence-to-sequence perspective, to unify RGB and RGB-D SOD. In VST, we developed a multi-task transformer decoder that concurrently predicts saliency and boundary outcomes in a pure transformer architecture. Moreover, we introduced a novel token upsampling method called reverse T2T for predicting a high-resolution saliency map effortlessly within transformer-based structures. Building upon the VST model, we further propose an efficient and stronger VST version in this work, i.e. VST++. To mitigate the computational costs of the VST model, we propose a Select-Integrate Attention (SIA) module, partitioning foreground into fine-grained segments and aggregating background information into a single coarse-grained token. To incorporate 3D depth information with low cost, we design a novel depth position encoding method tailored for depth maps. Furthermore, we introduce a token-supervised prediction loss to provide straightforward guidance for the task-related tokens. We evaluate our VST++ model across various transformer-based backbones on RGB, RGB-D, and RGB-T SOD benchmark datasets. Experimental results show that our model outperforms existing methods while achieving a 25% reduction in computational costs without significant performance compromise. The demonstrated strong ability for generalization, enhanced performance, and heightened efficiency of our VST++ model highlight its potential.
Create account to get full access
Overview
- This research paper introduces VST++, an efficient and stronger visual saliency transformer for saliency detection tasks.
- The model leverages the strengths of transformers to effectively capture long-range dependencies and context, leading to improved saliency detection performance.
- The paper explores multi-task learning approaches to jointly optimize saliency detection on RGB, RGB-D, and RGB-T data.
- Experimental results demonstrate the effectiveness of VST++ compared to state-of-the-art methods, with the model achieving competitive performance while being more efficient.
Plain English Explanation
VST++ is a new deep learning model that is designed to detect salient or important regions in images. Saliency detection is a fundamental task in computer vision, with applications in areas like image processing, object detection, and visual attention modeling.
The key innovation of VST++ is its use of transformer architectures, which are a type of neural network that excel at capturing long-range dependencies and contextual information in data. By leveraging the strengths of transformers, VST++ is able to more effectively identify the most visually salient parts of an image, outperforming previous state-of-the-art saliency detection models.
Additionally, the paper explores training VST++ to perform saliency detection on different types of input data, including standard RGB images as well as those with additional depth or thermal information. This multi-task learning approach allows the model to learn more robust and generalizable saliency prediction capabilities.
The experimental results presented in the paper demonstrate that VST++ achieves competitive performance on saliency detection benchmarks, while also being more computationally efficient than other transformer-based models. This efficiency makes VST++ a promising candidate for real-world applications that require fast and accurate saliency estimation, such as in autonomous systems or video analysis.
Technical Explanation
The paper first reviews prior work on CNN-based saliency detection and the emergence of transformer-based approaches for various computer vision tasks. The authors highlight the advantages of transformers in capturing long-range dependencies and contextual information, which are crucial for accurate saliency prediction.
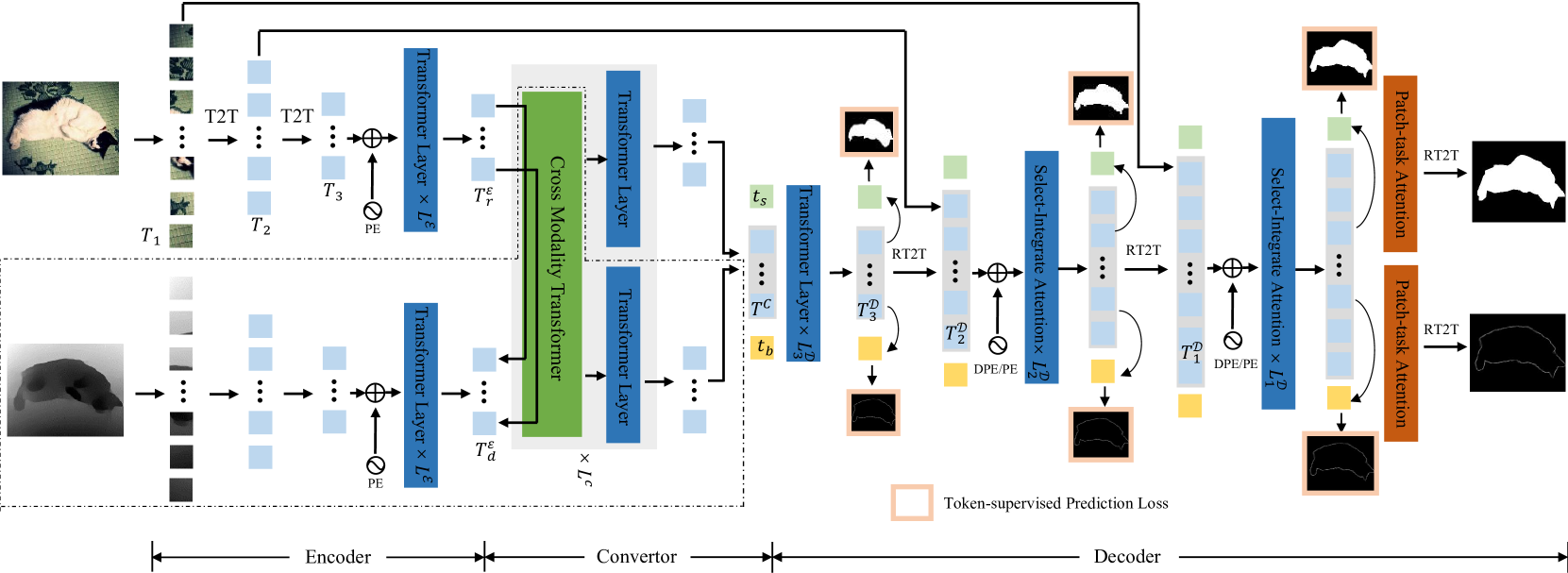
Building on this, the core contribution of the paper is the VST++ model, which leverages a transformer-based architecture to perform efficient and effective saliency detection. The model takes in an input image (either RGB, RGB-D, or RGB-T) and outputs a saliency map indicating the most salient regions.
The key components of the VST++ architecture include:
- Patch Embedding: The input image is divided into non-overlapping patches, which are then linearly projected to create patch embeddings.
- Transformer Encoder: A transformer encoder module processes the patch embeddings, capturing long-range dependencies and contextual information.
- Fusion Module: This module combines the transformer features with convolutional features to provide a more comprehensive representation for saliency prediction.
- Saliency Head: The final layer of the network outputs the saliency map, which can be used for various downstream applications.
The paper also explores a multi-task learning approach, where VST++ is trained to perform saliency detection on RGB, RGB-D, and RGB-T data simultaneously. This allows the model to learn more robust and generalizable saliency representations.
Extensive experiments are conducted on several saliency detection benchmarks, including DUTS, DUT-OMRON, and ECSSD. The results demonstrate that VST++ outperforms state-of-the-art saliency detection models, while also being more efficient in terms of computational cost and inference time.
Critical Analysis
The paper presents a compelling approach to saliency detection by leveraging the strengths of transformer architectures. The authors provide a thorough technical explanation of the VST++ model and its key components, and the experimental results showcase the model's effectiveness in comparison to other state-of-the-art methods.
One notable strength of the research is the exploration of multi-task learning for saliency detection on different input modalities (RGB, RGB-D, RGB-T). This approach allows the model to learn more generalizable saliency representations, which could be beneficial for real-world applications that may encounter varied input data.
However, the paper does not delve deeply into the potential limitations or areas for further research. For example, it would be interesting to understand how the model's performance might scale with larger or more diverse datasets, or how it might handle more complex or challenging saliency detection scenarios.
Additionally, the paper could have provided more insights into the interpretability of the VST++ model, such as visualizations of the attention patterns or an analysis of the most salient features learned by the transformer components. This could help researchers and practitioners better understand the model's decision-making process and identify potential biases or failure cases.
Overall, the VST++ paper presents a compelling and efficient approach to visual saliency detection, but there may be opportunities for further exploration and refinement of the model's capabilities and limitations.
Conclusion
The VST++ paper introduces an efficient and powerful visual saliency transformer that leverages the strengths of transformer architectures to achieve state-of-the-art performance on saliency detection tasks. By exploring multi-task learning on RGB, RGB-D, and RGB-T data, the model demonstrates its ability to learn robust and generalizable saliency representations.
The experimental results show that VST++ outperforms other leading saliency detection models while being more computationally efficient, making it a promising candidate for real-world applications that require fast and accurate saliency estimation. The paper's technical contributions and insights could inspire further research and development in the field of visual attention modeling and its diverse applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MDS-ViTNet: Improving saliency prediction for Eye-Tracking with Vision Transformer
Polezhaev Ignat, Goncharenko Igor, Iurina Natalya
0
0
In this paper, we present a novel methodology we call MDS-ViTNet (Multi Decoder Saliency by Vision Transformer Network) for enhancing visual saliency prediction or eye-tracking. This approach holds significant potential for diverse fields, including marketing, medicine, robotics, and retail. We propose a network architecture that leverages the Vision Transformer, moving beyond the conventional ImageNet backbone. The framework adopts an encoder-decoder structure, with the encoder utilizing a Swin transformer to efficiently embed most important features. This process involves a Transfer Learning method, wherein layers from the Vision Transformer are converted by the Encoder Transformer and seamlessly integrated into a CNN Decoder. This methodology ensures minimal information loss from the original input image. The decoder employs a multi-decoding technique, utilizing dual decoders to generate two distinct attention maps. These maps are subsequently combined into a singular output via an additional CNN model. Our trained model MDS-ViTNet achieves state-of-the-art results across several benchmarks. Committed to fostering further collaboration, we intend to make our code, models, and datasets accessible to the public.
5/31/2024

ViDSOD-100: A New Dataset and a Baseline Model for RGB-D Video Salient Object Detection
Junhao Lin, Lei Zhu, Jiaxing Shen, Huazhu Fu, Qing Zhang, Liansheng Wang
0
0
With the rapid development of depth sensor, more and more RGB-D videos could be obtained. Identifying the foreground in RGB-D videos is a fundamental and important task. However, the existing salient object detection (SOD) works only focus on either static RGB-D images or RGB videos, ignoring the collaborating of RGB-D and video information. In this paper, we first collect a new annotated RGB-D video SOD (ViDSOD-100) dataset, which contains 100 videos within a total of 9,362 frames, acquired from diverse natural scenes. All the frames in each video are manually annotated to a high-quality saliency annotation. Moreover, we propose a new baseline model, named attentive triple-fusion network (ATF-Net), for RGB-D video salient object detection. Our method aggregates the appearance information from an input RGB image, spatio-temporal information from an estimated motion map, and the geometry information from the depth map by devising three modality-specific branches and a multi-modality integration branch. The modality-specific branches extract the representation of different inputs, while the multi-modality integration branch combines the multi-level modality-specific features by introducing the encoder feature aggregation (MEA) modules and decoder feature aggregation (MDA) modules. The experimental findings conducted on both our newly introduced ViDSOD-100 dataset and the well-established DAVSOD dataset highlight the superior performance of the proposed ATF-Net. This performance enhancement is demonstrated both quantitatively and qualitatively, surpassing the capabilities of current state-of-the-art techniques across various domains, including RGB-D saliency detection, video saliency detection, and video object segmentation. Our data and our code are available at github.com/jhl-Det/RGBD_Video_SOD.
6/19/2024
🔎
Salient Object Detection in RGB-D Videos
Ao Mou, Yukang Lu, Jiahao He, Dingyao Min, Keren Fu, Qijun Zhao
0
0
Given the widespread adoption of depth-sensing acquisition devices, RGB-D videos and related data/media have gained considerable traction in various aspects of daily life. Consequently, conducting salient object detection (SOD) in RGB-D videos presents a highly promising and evolving avenue. Despite the potential of this area, SOD in RGB-D videos remains somewhat under-explored, with RGB-D SOD and video SOD (VSOD) traditionally studied in isolation. To explore this emerging field, this paper makes two primary contributions: the dataset and the model. On one front, we construct the RDVS dataset, a new RGB-D VSOD dataset with realistic depth and characterized by its diversity of scenes and rigorous frame-by-frame annotations. We validate the dataset through comprehensive attribute and object-oriented analyses, and provide training and testing splits. Moreover, we introduce DCTNet+, a three-stream network tailored for RGB-D VSOD, with an emphasis on RGB modality and treats depth and optical flow as auxiliary modalities. In pursuit of effective feature enhancement, refinement, and fusion for precise final prediction, we propose two modules: the multi-modal attention module (MAM) and the refinement fusion module (RFM). To enhance interaction and fusion within RFM, we design a universal interaction module (UIM) and then integrate holistic multi-modal attentive paths (HMAPs) for refining multi-modal low-level features before reaching RFMs. Comprehensive experiments, conducted on pseudo RGB-D video datasets alongside our RDVS, highlight the superiority of DCTNet+ over 17 VSOD models and 14 RGB-D SOD models. Ablation experiments were performed on both pseudo and realistic RGB-D video datasets to demonstrate the advantages of individual modules as well as the necessity of introducing realistic depth. Our code together with RDVS dataset will be available at https://github.com/kerenfu/RDVS/.
5/22/2024
🔎
TAM-VT: Transformation-Aware Multi-scale Video Transformer for Segmentation and Tracking
Raghav Goyal, Wan-Cyuan Fan, Mennatullah Siam, Leonid Sigal
0
0
Video Object Segmentation (VOS) has emerged as an increasingly important problem with availability of larger datasets and more complex and realistic settings, which involve long videos with global motion (e.g, in egocentric settings), depicting small objects undergoing both rigid and non-rigid (including state) deformations. While a number of recent approaches have been explored for this task, these data characteristics still present challenges. In this work we propose a novel, clip-based DETR-style encoder-decoder architecture, which focuses on systematically analyzing and addressing aforementioned challenges. Specifically, we propose a novel transformation-aware loss that focuses learning on portions of the video where an object undergoes significant deformations -- a form of soft hard examples mining. Further, we propose a multiplicative time-coded memory, beyond vanilla additive positional encoding, which helps propagate context across long videos. Finally, we incorporate these in our proposed holistic multi-scale video transformer for tracking via multi-scale memory matching and decoding to ensure sensitivity and accuracy for long videos and small objects. Our model enables on-line inference with long videos in a windowed fashion, by breaking the video into clips and propagating context among them. We illustrate that short clip length and longer memory with learned time-coding are important design choices for improved performance. Collectively, these technical contributions enable our model to achieve new state-of-the-art (SoTA) performance on two complex egocentric datasets -- VISOR and VOST, while achieving comparable to SoTA results on the conventional VOS benchmark, DAVIS'17. A series of detailed ablations validate our design choices as well as provide insights into the importance of parameter choices and their impact on performance.
4/11/2024