Zeroth-Order Fine-Tuning of LLMs with Extreme Sparsity
2406.02913
0
0

Abstract
Zeroth-order optimization (ZO) is a memory-efficient strategy for fine-tuning Large Language Models using only forward passes. However, the application of ZO fine-tuning in memory-constrained settings such as mobile phones and laptops is still challenging since full precision forward passes are infeasible. In this study, we address this limitation by integrating sparsity and quantization into ZO fine-tuning of LLMs. Specifically, we investigate the feasibility of fine-tuning an extremely small subset of LLM parameters using ZO. This approach allows the majority of un-tuned parameters to be quantized to accommodate the constraint of limited device memory. Our findings reveal that the pre-training process can identify a set of sensitive parameters that can guide the ZO fine-tuning of LLMs on downstream tasks. Our results demonstrate that fine-tuning 0.1% sensitive parameters in the LLM with ZO can outperform the full ZO fine-tuning performance, while offering wall-clock time speedup. Additionally, we show that ZO fine-tuning targeting these 0.1% sensitive parameters, combined with 4 bit quantization, enables efficient ZO fine-tuning of an Llama2-7B model on a GPU device with less than 8 GiB of memory and notably reduced latency.
Create account to get full access
Overview
- This paper explores a technique called "zeroth-order fine-tuning" for efficiently updating large language models (LLMs) with a small amount of data.
- The key idea is to fine-tune only a sparse subset of the model's parameters, drastically reducing the number of parameters that need to be updated.
- The researchers demonstrate this approach on several benchmark tasks, showing that it can match or outperform standard fine-tuning while using a fraction of the computational resources.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful, but they require a lot of data and computation to fine-tune for specific tasks. This paper presents a more efficient approach called "zeroth-order fine-tuning."
The main insight is that you don't need to update every single parameter in the model to improve its performance on a new task. Instead, you can get good results by only updating a small, carefully selected subset of the parameters.
This is like renovating just one room in your house, rather than doing a full remodel. It's a lot less work, but can still make a big difference.
The researchers show that by using this sparse, targeted approach, you can match or even outperform standard fine-tuning methods, while using a fraction of the computational resources. This could make it much easier and cheaper to adapt large language models to new applications.
Technical Explanation
The paper introduces a novel "zeroth-order fine-tuning" technique for efficiently updating large language models (LLMs) with a small amount of data. The key idea is to fine-tune only a sparse subset of the model's parameters, drastically reducing the number of parameters that need to be updated.
Specifically, the researchers propose a two-stage approach. First, they use a zeroth-order optimization method [<a href="https://aimodels.fyi/papers/arxiv/revisiting-zeroth-order-optimization-memory-efficient-llm">1</a>, <a href="https://aimodels.fyi/papers/arxiv/variance-reduced-zeroth-order-methods-fine-tuning">2</a>, <a href="https://aimodels.fyi/papers/arxiv/differentially-private-zeroth-order-methods-scalable-large">3</a>] to identify the most important parameters to fine-tune. Then, they only update this sparse subset of parameters, leaving the rest of the model unchanged.
Through extensive experiments on various benchmarks, the authors demonstrate that this sparse fine-tuning approach can match or even outperform standard fine-tuning methods, while using a fraction of the computational resources. For example, they show that their method can achieve comparable performance to full fine-tuning while only updating 1-5% of the model's parameters.
The researchers also provide insights into the optimal sparsity levels and fine-tuning strategies for different types of tasks and model architectures [<a href="https://aimodels.fyi/papers/arxiv/study-optimizations-fine-tuning-large-language-models">4</a>]. Additionally, they explore the impact of different parameter selection methods and the trade-offs between sparsity and performance.
Critical Analysis
The "zeroth-order fine-tuning" approach presented in this paper is a promising technique for improving the efficiency of fine-tuning large language models. By only updating a small subset of the model's parameters, the researchers are able to achieve comparable performance while using a fraction of the computational resources.
One potential limitation of this approach is that the optimal sparsity level and fine-tuning strategy may vary depending on the specific task and model architecture. The authors provide some guidance on this, but more research may be needed to fully understand the optimal configurations for different use cases.
Additionally, the paper does not explore the impact of this approach on the model's robustness or generalization capabilities. It would be interesting to see whether the sparse fine-tuning technique affects the model's ability to perform well on a diverse range of tasks or handle distributional shift in the input data.
Overall, this research represents a meaningful contribution to the field of efficient fine-tuning for large language models. The sparse, targeted approach could have significant practical implications, making it more feasible to adapt these powerful models to a wide range of applications. However, further investigation into the broader implications and limitations of this technique would be valuable.
Conclusion
This paper introduces a novel "zeroth-order fine-tuning" technique that can efficiently update large language models (LLMs) with a small amount of data. By fine-tuning only a sparse subset of the model's parameters, the researchers demonstrate that it is possible to match or even outperform standard fine-tuning methods while using a fraction of the computational resources.
The insights from this work could have significant practical implications, making it more feasible to adapt powerful LLMs to a wide range of applications. By reducing the computational and data requirements for fine-tuning, this sparse approach could help democratize access to these advanced language models and accelerate their adoption across various domains.
While further research is needed to fully understand the limitations and optimal configurations of this technique, the core idea of selectively fine-tuning a small portion of a model's parameters represents an important step forward in the pursuit of efficient and scalable language model adaptation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Jason D. Lee, Wotao Yin, Mingyi Hong, Zhangyang Wang, Sijia Liu, Tianlong Chen
0
0
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow {in size}, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by MeZO. Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, first-of-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM .
5/29/2024
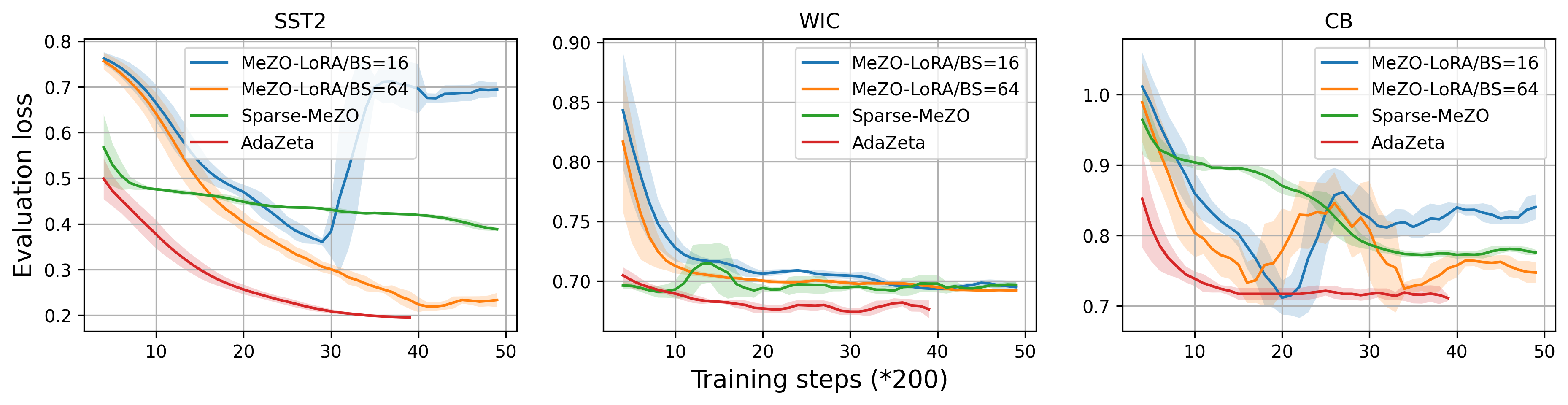
AdaZeta: Adaptive Zeroth-Order Tensor-Train Adaption for Memory-Efficient Large Language Models Fine-Tuning
Yifan Yang, Kai Zhen, Ershad Banijamal, Athanasios Mouchtaris, Zheng Zhang
0
0
Fine-tuning large language models (LLMs) has achieved remarkable performance across various natural language processing tasks, yet it demands more and more memory as model sizes keep growing. To address this issue, the recently proposed Memory-efficient Zeroth-order (MeZO) methods attempt to fine-tune LLMs using only forward passes, thereby avoiding the need for a backpropagation graph. However, significant performance drops and a high risk of divergence have limited their widespread adoption. In this paper, we propose the Adaptive Zeroth-order Tensor-Train Adaption (AdaZeta) framework, specifically designed to improve the performance and convergence of the ZO methods. To enhance dimension-dependent ZO estimation accuracy, we introduce a fast-forward, low-parameter tensorized adapter. To tackle the frequently observed divergence issue in large-scale ZO fine-tuning tasks, we propose an adaptive query number schedule that guarantees convergence. Detailed theoretical analysis and extensive experimental results on Roberta-Large and Llama-2-7B models substantiate the efficacy of our AdaZeta framework in terms of accuracy, memory efficiency, and convergence speed.
6/27/2024
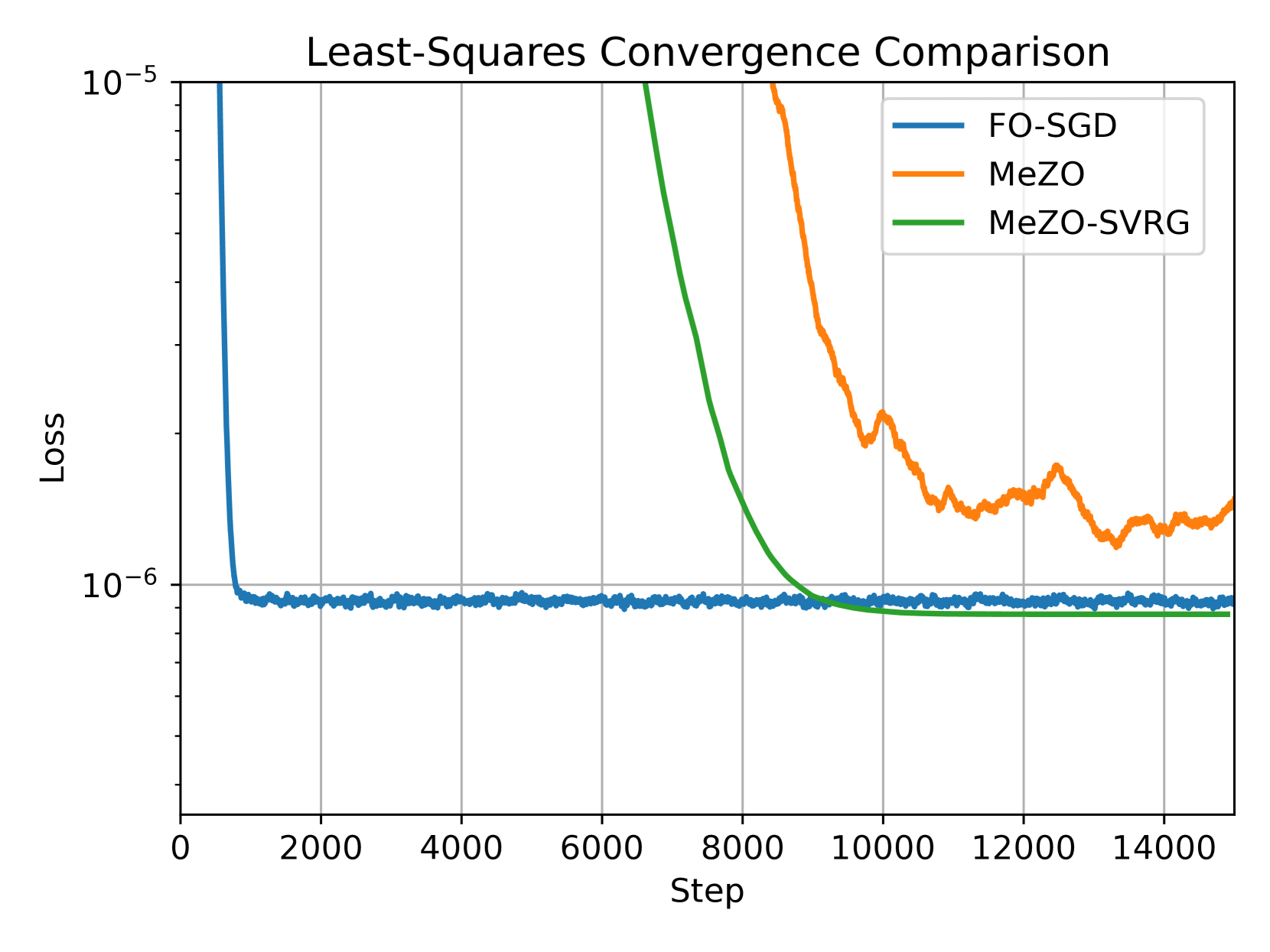
Variance-reduced Zeroth-Order Methods for Fine-Tuning Language Models
Tanmay Gautam, Youngsuk Park, Hao Zhou, Parameswaran Raman, Wooseok Ha
0
0
Fine-tuning language models (LMs) has demonstrated success in a wide array of downstream tasks. However, as LMs are scaled up, the memory requirements for backpropagation become prohibitively high. Zeroth-order (ZO) optimization methods can leverage memory-efficient forward passes to estimate gradients. More recently, MeZO, an adaptation of ZO-SGD, has been shown to consistently outperform zero-shot and in-context learning when combined with suitable task prompts. In this work, we couple ZO methods with variance reduction techniques to enhance stability and convergence for inference-based LM fine-tuning. We introduce Memory-Efficient Zeroth-Order Stochastic Variance-Reduced Gradient (MeZO-SVRG) and demonstrate its efficacy across multiple LM fine-tuning tasks, eliminating the reliance on task-specific prompts. Evaluated across a range of both masked and autoregressive LMs on benchmark GLUE tasks, MeZO-SVRG outperforms MeZO with up to 20% increase in test accuracies in both full- and partial-parameter fine-tuning settings. MeZO-SVRG benefits from reduced computation time as it often surpasses MeZO's peak test accuracy with a $2times$ reduction in GPU-hours. MeZO-SVRG significantly reduces the required memory footprint compared to first-order SGD, i.e. by $2times$ for autoregressive models. Our experiments highlight that MeZO-SVRG's memory savings progressively improve compared to SGD with larger batch sizes.
4/15/2024
💬
Differentially Private Zeroth-Order Methods for Scalable Large Language Model Finetuning
Z Liu, J Lou, W Bao, Y Hu, B Li, Z Qin, K Ren
0
0
Fine-tuning on task-specific datasets is a widely-embraced paradigm of harnessing the powerful capability of pretrained LLMs for various downstream tasks. Due to the popularity of LLMs fine-tuning and its accompanying privacy concerns, differentially private (DP) fine-tuning of pretrained LLMs has been widely used to safeguarding the privacy of task-specific datasets. Lying at the design core of DP LLM fine-tuning methods is the satisfactory tradeoff among privacy, utility, and scalability. Most existing methods build upon the seminal work of DP-SGD. Despite pushing the scalability of DP-SGD to its limit, DP-SGD-based fine-tuning methods are unfortunately limited by the inherent inefficiency of SGD. In this paper, we investigate the potential of DP zeroth-order methods for LLM pretraining, which avoids the scalability bottleneck of SGD by approximating the gradient with the more efficient zeroth-order gradient. Rather than treating the zeroth-order method as a drop-in replacement for SGD, this paper presents a comprehensive study both theoretically and empirically. First, we propose the stagewise DP zeroth-order method (DP-ZOSO) that dynamically schedules key hyperparameters. This design is grounded on the synergy between DP random perturbation and the gradient approximation error of the zeroth-order method, and its effect on fine-tuning trajectory. We provide theoretical analysis for both proposed methods. We conduct extensive empirical analysis on both encoder-only masked language model and decoder-only autoregressive language model, achieving impressive results in terms of scalability and utility (compared with DPZero, DP-ZOPO improves 4.5% on SST-5, 5.5% on MNLI with RoBERTa-Large and 9.2% on CB, 3.9% on BoolQ with OPT-2.7B when $epsilon=4$).
5/10/2024